|

TL;DR
OLLM is a confidential AI gateway that routes requests across hundreds of LLM providers behind a single, security-enforced API
For supported providers and models, inference runs inside hardware-isolated TEEs, backed by Intel TDX and NVIDIA GPU attestation proofs that compliance teams can independently verify.
By default, OLLM does not persistently store prompt or response content at the gateway layer, thereby eliminating the surface for inference data breaches.
Security controls, retention defaults, TEE-backed routing, and attestation reporting can be enforced at the infrastructure layer by configuration, not left to application-level implementation.
Gateway-layer scaling through rate-limit-aware routing, load balancing, and failover means security posture holds as inference volume grows.
Enterprise AI is no longer confined to experimentation labs or internal prototypes. Large language models are now embedded in customer support systems, legal workflows, financial analysis pipelines, healthcare documentation, and internal decision-support tools. As these systems begin handling regulated data and sensitive business context, the security conversation changes. It is no longer enough to rely on encryption in transit or vendor privacy statements. Enterprises are being asked to demonstrate where inference runs, what data is retained, how isolation is enforced, and whether execution integrity can be independently verified. AI infrastructure is now subject to the same scrutiny as financial systems and regulated data pipelines.
This article examines what enterprise-grade AI security actually requires and how OLLM addresses those requirements at the infrastructure layer. It explains how Trusted Execution Environments protect inference at runtime, how Intel TDX and NVIDIA GPU attestation generate cryptographic proof of execution integrity, how zero prompt and response retention reduce exposure to breaches, and how centralized routing and scaling preserve that security posture as usage grows. The goal is not to describe features in isolation, but to clarify why confidential AI gateways are becoming a structural requirement for organizations deploying LLMs in production.
What Is OLLM?
OLLM is the world’s first enterprise AI gateway aggregating high-security, zero-retention LLM providers behind a single, security-enforced API. It gives organizations access to multiple production-grade models through one integration surface while applying guaranteed, military-grade encryption at every layer of the inference path. The architecture is built around verifiable privacy: zero prompt and response retention by default, hardware-backed isolation for supported providers, and cryptographic attestation artifacts that can be independently validated.
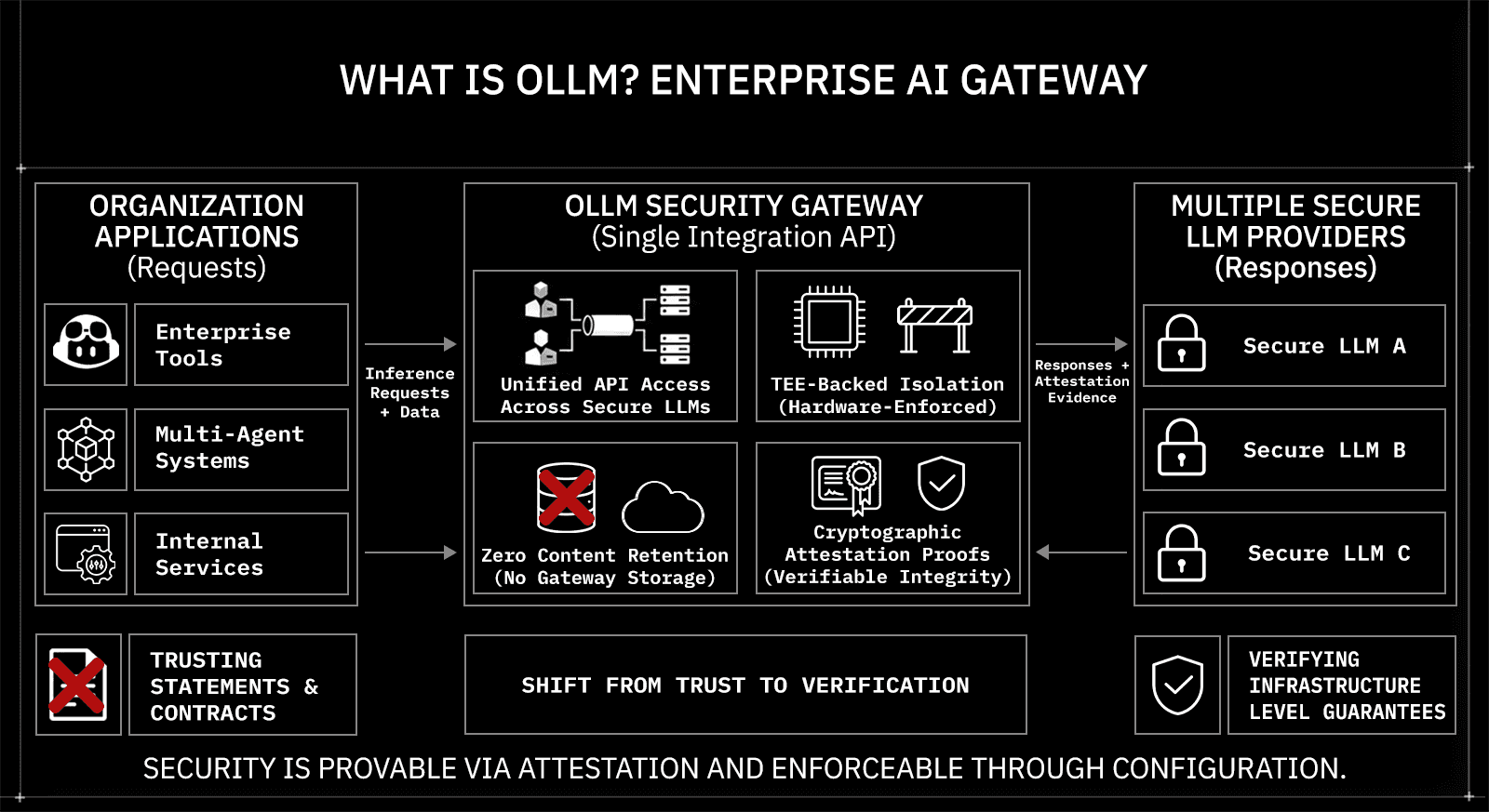
Unlike a standard API proxy or model aggregator, OLLM embeds security controls directly into the infrastructure layer. Its core capabilities include:
Unified API access across multiple secure LLM providers through a single integration point
TEE-backed execution for supported models, enabling inference inside hardware-isolated environments
Zero prompt and response retention by default, eliminating durable storage of request content at the gateway layer
Cryptographic attestation proofs that provide verifiable evidence of execution integrity
Encryption at every layer, covering network transport, runtime isolation, and infrastructure boundaries
These controls allow enterprises to access models without sacrificing compliance posture, data confidentiality, or operational control.
For organizations operating in regulated environments or handling sensitive data at scale, OLLM shifts the conversation from trusting a provider's privacy statement to verifying infrastructure-level evidence. Security becomes enforceable through configuration and provable through attestation, rather than relying on application-level discipline or contractual assurances.
The best way to understand what OLLM actually does is to see it in operation. Below is a live view of the OLLM messages dashboard, a real-time feed of inference requests across providers and models
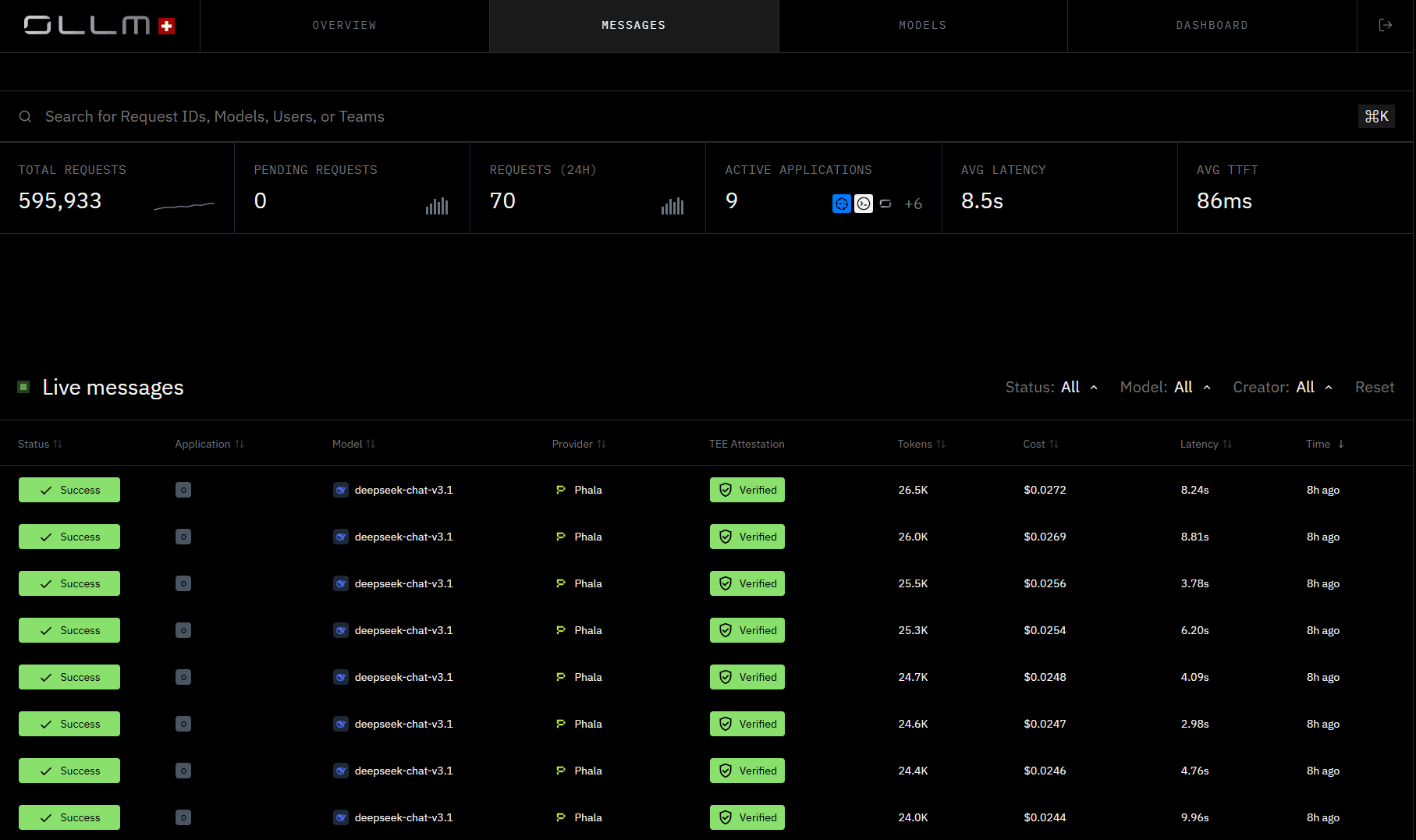
Notice the TEE Attestation column. Every request in this feed shows a Verified status, not as a post-hoc report, but as a per-request confirmation visible at the operational layer. This is what infrastructure-level security looks like in practice.
The Enterprise AI Security Problem Worth Solving
Most enterprises don't have a single AI provider; they have many. Different teams adopt different models for different tasks, each with its own API key, data handling policy, and compliance posture. That sprawl creates risk at every seam.
The core problem is that standard LLM APIs were not designed with enterprise security as a first principle. When a prompt leaves your application and travels to a third-party inference endpoint, several things are typically true:
Prompt content may be retained by the provider for logging, monitoring, or model improvement
Hardware-level isolation between your workload and other tenants on shared infrastructure is typically absent; hardware-backed isolation reduces the risk of certain co-tenant and host-access threats, but only within the TEE threat model
Compliance evidence is thin; you get a terms-of-service document, not a cryptographic proof
Multi-provider management multiplies surface area: more keys, more contracts, more potential failure points
The risk isn't hypothetical. In regulated industries, such as finance, healthcare, legal, and defense, a single improperly handled prompt containing client data, internal strategy, or PII can trigger a compliance violation. And unlike a database breach, AI prompt exposure is often invisible. No audit log entry says "your data was used."
What enterprises actually need is an inference path where security is enforceable by configuration, not just promised in a policy document, where execution integrity can be verified, and where sensitive prompt content has no durable storage surface to breach in the first place.
That is the problem OLLM was designed to solve at the infrastructure level.
Hardware-Backed Security: TEE Isolation and Cryptographic Attestation
Most AI security conversations stop at encryption in transit. OLLM goes further, into the hardware layer, where inference actually happens.
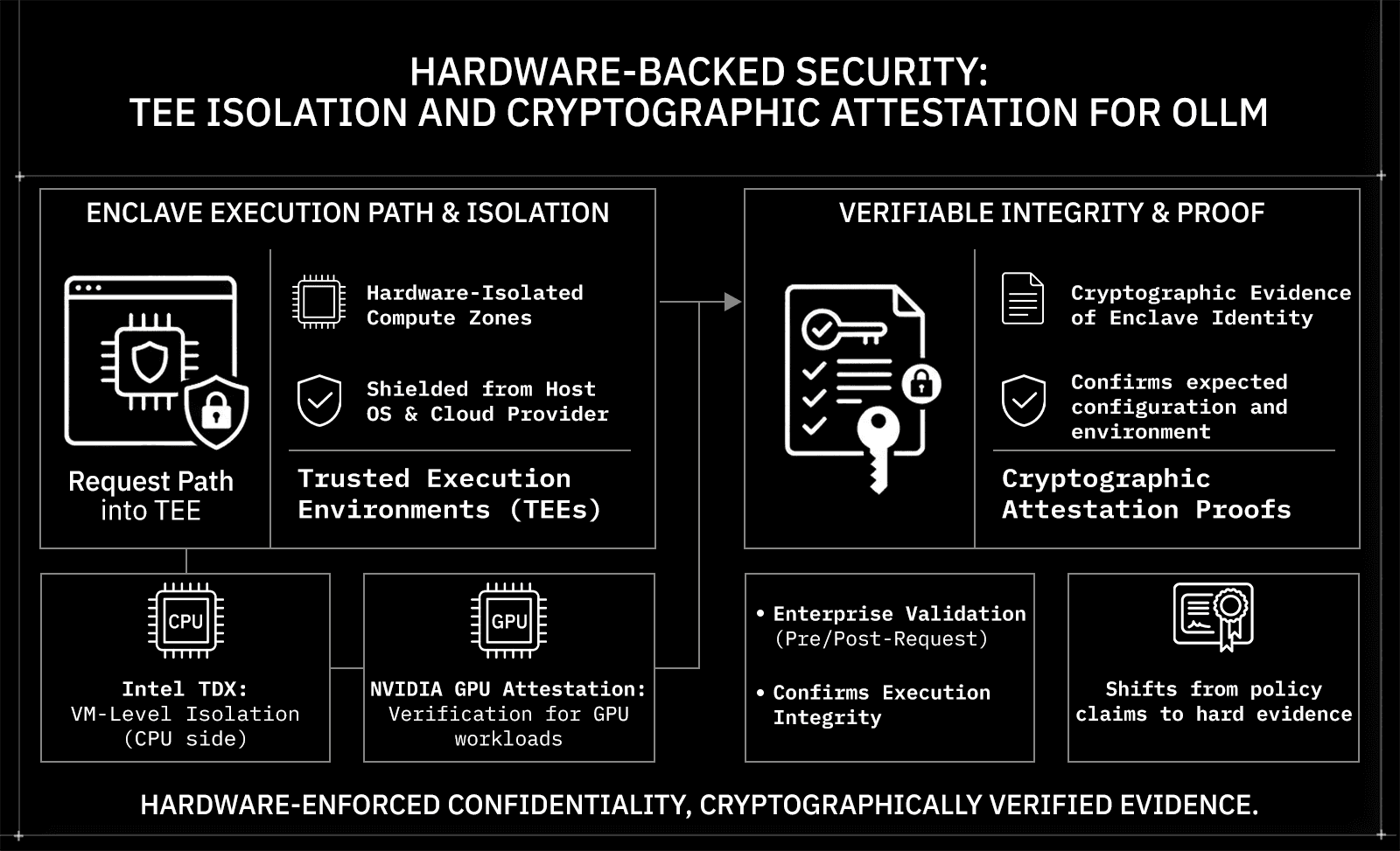
Trusted Execution Environments (TEEs)
A Trusted Execution Environment is a hardware-isolated compute zone in which code runs, shielded from the host OS, hypervisor, and other tenants. Even the cloud provider operating the underlying machine cannot read what is happening inside a TEE. When a TEE-enabled model is selected, the request is routed to a secure TEE-backed execution environment, meaning inference itself runs inside that isolation boundary, not just the network traffic around it.
OLLM supports TEE-backed execution for supported providers and models, for example, Phala and NEAR inference paths, where a provider supporting TEE-backed inference is used for regulated workloads.
Intel TDX and NVIDIA GPU Attestation
OLLM integrates two specific attestation technologies that matter for enterprise verification:
Technology | What It Does |
Intel TDX | Isolates VM-level execution in a hardware-enforced confidential boundary |
NVIDIA GPU Attestation | Extends trust verification to GPU workloads where supported; availability varies by stack and hardware configuration |
OLLM integrates Intel TDX-based confidential-VM isolation and NVIDIA GPU attestation (where supported), and can surface attestation results in a standardized format.
TEE-backed execution is not limited to a single model or a single provider. Across OLLM's model catalog, supported models from both NEAR and Phala carry a TEE designation, meaning hardware isolation is a property of the model-provider path rather than a special configuration you need to request.
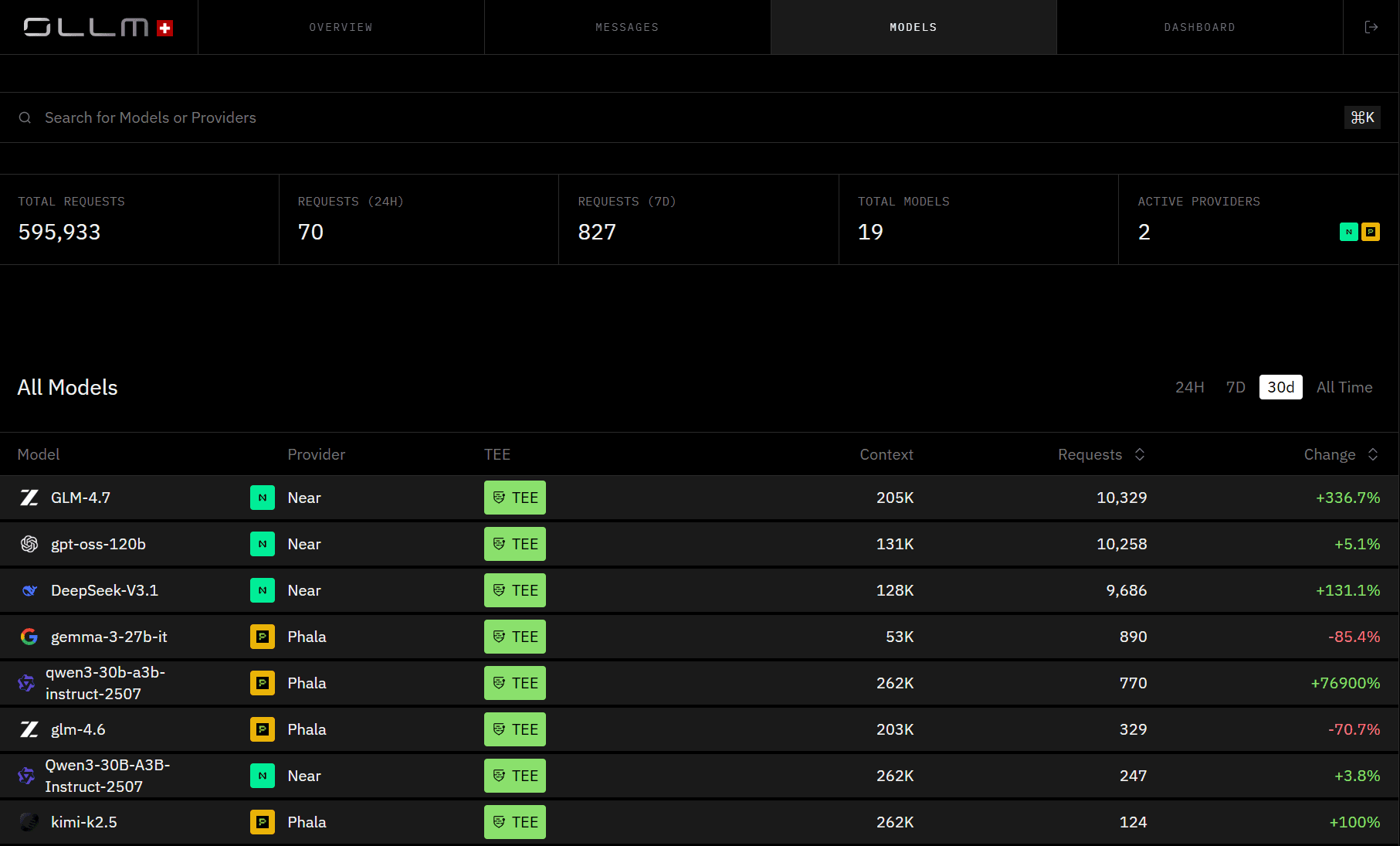
Models like GLM-4.7, DeepSeek-V3.1, and Qwen3, when run through NEAR or Phala, carry the TEE badge, each representing an inference path in which execution is hardware-isolated and attestation is generated per request.
Cryptographic Attestation Proofs
This is OLLM's most important differentiator. TEE-backed execution can enable cryptographic attestation. Depending on the stack, technologies such as Intel TDX (for the confidential VM) and NVIDIA GPU attestation (for the GPU/device state) can generate evidence about the execution environment, including:
The identity and integrity of the confidential VM/workload measurement (per the attestation policy)
That the workload ran in a TEE-backed environment consistent with the policy
That the host can't directly read guest memory (within the TEE threat model)
Optionally, device/GPU claims when GPU attestation is available
This model can replace purely trust-based isolation claims with cryptographically verifiable evidence about the execution environment.
Enterprises can validate attestation evidence as part of a trust policy, typically before provisioning secrets (and, in some designs, before sending sensitive prompts), and/or before accepting results.
For compliance-heavy environments, this shifts the conversation from "we promise your data is safe" to "here is the cryptographic evidence."
Zero Prompt and Response Retention Keeps Your Data Unexposed
Data breaches at the AI layer are uniquely dangerous because the exposure is silent. There is no corrupted file, no missing record, just prompt content that was stored somewhere it shouldn't have been, waiting to be accessed.
OLLM addresses this at the default configuration level, not as an opt-in feature.
What Zero-Retention Actually Means
By default, OLLM does not persistently store prompt or response content at the gateway layer. There is no database of inference requests accumulating over time, so there is no surface for that content to be extracted from.
It is important to be precise about what this covers:
Data Type | Default Behavior |
Prompt content | Not stored persistently by default |
Response content | Not stored persistently by default |
Usage metadata (tokens, cost, timestamps) | Logged for billing and reliability |
Content logging | Opt-in via configuration (e.g., |
This distinction matters. Zero-retention refers specifically to prompt and response content. Operational metadata, the kind needed for billing, audit trails, and reliability workflows, may still be retained depending on configuration.
Why This Reduces Breach Blast Radius
When prompt and response content is never durably stored, the blast radius of a gateway-layer breach shrinks dramatically. An attacker who compromises the gateway finds usage metadata, not a historical record of every sensitive query your organization has ever made.
This should be treated as an infrastructure default backed by enforceable configuration and policy guardrails, not just an application-level best practice that developers remember to follow. Prompt payload persistence and observability content capture should be explicitly turned off by policy to preserve the end-to-end confidentiality guarantee.
For enterprises handling sensitive data, client communications, internal strategy, and regulated PII, this default posture meaningfully reduces liability before any additional controls are applied.
One API Across Many Providers, Without Multiplying Your Risk
Accessing multiple LLM providers without a gateway requires managing multiple API keys, rate limits, failure modes, and data-handling agreements simultaneously. Every added provider is another integration to maintain and another risk surface to monitor. OLLM collapses that complexity into a single API endpoint, without collapsing the security controls that come with it.
How Model Selection and Routing Actually Work
OLLM's routing is flexible by design. Model selection can be application-driven, policy-driven, or hybrid:
Application-driven: The app specifies an explicit model alias; the gateway routes to the corresponding provider.
Policy-driven: The gateway selects among approved deployments based on latency, cost, or availability.
Hybrid: The app expresses intent via a model alias; the gateway handles fallback, load balancing, and rate-limit-aware routing across deployments.
Most enterprise setups use the hybrid approach. Rate-limit failures, provider outages, and latency spikes are absorbed at the infrastructure layer rather than pushed back to the application to handle.
The operational reality of a unified API is that integration should require minimal change to existing workflows. OLLM provides an OpenAI-style, OpenAI-SDK-compatible API for supported endpoints, meaning teams already using the OpenAI SDK or standard REST clients can switch to OLLM's confidential inference path without adopting a new library or rewriting existing code.
from openai import OpenAI |
The only difference from a standard OpenAI call is the base_url. The model alias, in this case near/GLM-4.6, tells the gateway which provider path to use. From there, TEE-backed execution, zero-retention defaults, and attestation generation happen at the infrastructure layer, with no additional code required from the application.
Centralized Observability and Cost Tracking
A single API also means a single observability surface. Instead of reconciling usage data across multiple provider dashboards, OLLM centralizes token usage, cost tracking, and request metadata in one place, giving engineering and finance teams a coherent picture of AI spend without requiring upstream provider invoices to disappear.
Privacy-Preserving Defaults Carry Across Every Provider
OLLM's privacy defaults, zero prompt/response retention, TEE-backed execution paths for supported models, configurable logging, apply uniformly regardless of which underlying provider handles the request. The application does not need to implement different security logic per provider. These controls can be enforced at the gateway layer through configuration.
Compliance-Ready Infrastructure That Goes Beyond Policy Promises
Regulated industries, such as finance, healthcare, legal, and defense, are increasingly being asked to demonstrate how their AI systems protect sensitive data, rather than merely assert that they do. A privacy policy is no longer sufficient evidence. Auditors, regulators, and enterprise procurement teams want enforceable controls and verifiable proof.
Attestation as Audit Evidence
Cryptographic TEE attestation proofs are not just a security feature; they are a compliance artifact. When inference runs inside a hardware-isolated environment, the attestation report generated by Intel TDX or NVIDIA GPU Attestation provides verifiable evidence that:
The confidential VM/workload measurement matches the expected values defined in the attestation policy, confirming the environment has not been tampered with
The workload ran in a TEE-backed environment consistent with the policy
The host can't directly read guest memory (within the TEE threat model)
Optionally, device/GPU claims when GPU attestation is available
This moves compliance conversations from self-attestation to cryptographic proof that auditors can verify themselves.
Enforceable Configuration, Not Application-Level Hope
A common failure mode in enterprise AI deployments is treating security as an application-layer responsibility, expecting developers to remember to turn off logging, avoid storing prompts, and route to compliant providers. That approach does not scale and does not hold up under audit.
OLLM enforces security posture at the infrastructure layer through configurable policy guardrails:
Prompt and response retention is turned off by default, opt-in only via explicit configuration
TEE-backed routing can be enforced at the gateway layer for supported providers and models
Attestation evidence can be validated as part of your trust policy, typically before provisioning secrets or sending sensitive prompts, and/or before accepting results
Confidential AI Is Becoming the Regulated Standard
Confidential infrastructure is increasingly expected in regulated environments, not as a differentiator, but as a baseline requirement. OLLM integrates Intel TDX-based isolation, NVIDIA GPU attestation, and standardized attestation reporting, with retention controls enforceable across the entire inference path. For organizations building toward SOC 2, HIPAA, or similar frameworks, that combination meaningfully reduces the compliance surface to defend.
Scaling OLLM Across Enterprise Workloads Without Losing Control
Security infrastructure is only useful if it can keep pace with production demand. An AI gateway that becomes a bottleneck under load or requires re-architecture to scale undermines the operational value it was meant to provide. OLLM handles scale at the gateway layer, not by pushing that complexity back to the application.
How Scaling Works at the Gateway Layer
OLLM's architecture handles growth through mechanisms that operate transparently to the application:
Centralized quota enforcement: Usage limits are managed at the gateway, not per-application
Rate-limit-aware routing: Requests are automatically redirected away from providers approaching their ceilings
Load balancing: Traffic is distributed across available deployments to maintain throughput
Failover: If a provider becomes unavailable, requests are rerouted without application-side handling
As inference volume grows, the gateway absorbs operational complexity, provider failures, rate-limiting ceilings, and traffic spikes without requiring changes to the application.
Practical Steps to Scale When Needed
For most use cases, scaling within OLLM is straightforward:
To increase capacity, load additional credits through your OLLM plan
For sustained high-volume workloads, document processing pipelines, customer-facing AI features, or internal tooling at scale, contact the OLLM sales team to discuss reserving capacity ahead of demand.
For enterprise requirements, guaranteed token limits, reserved capacity, or predictable fixed-cost pricing, contact the OLLM sales team to discuss a plan tailored to your organization's needs.
Reserving capacity in advance ensures rate limits do not become a production incident.
Centralized observability is not just an operational convenience; it is what makes scaling auditable. As inference volume grows across multiple providers and models, engineering and finance teams need a single source of truth for spend, latency, and token usage. OLLM's dashboard provides exactly that:
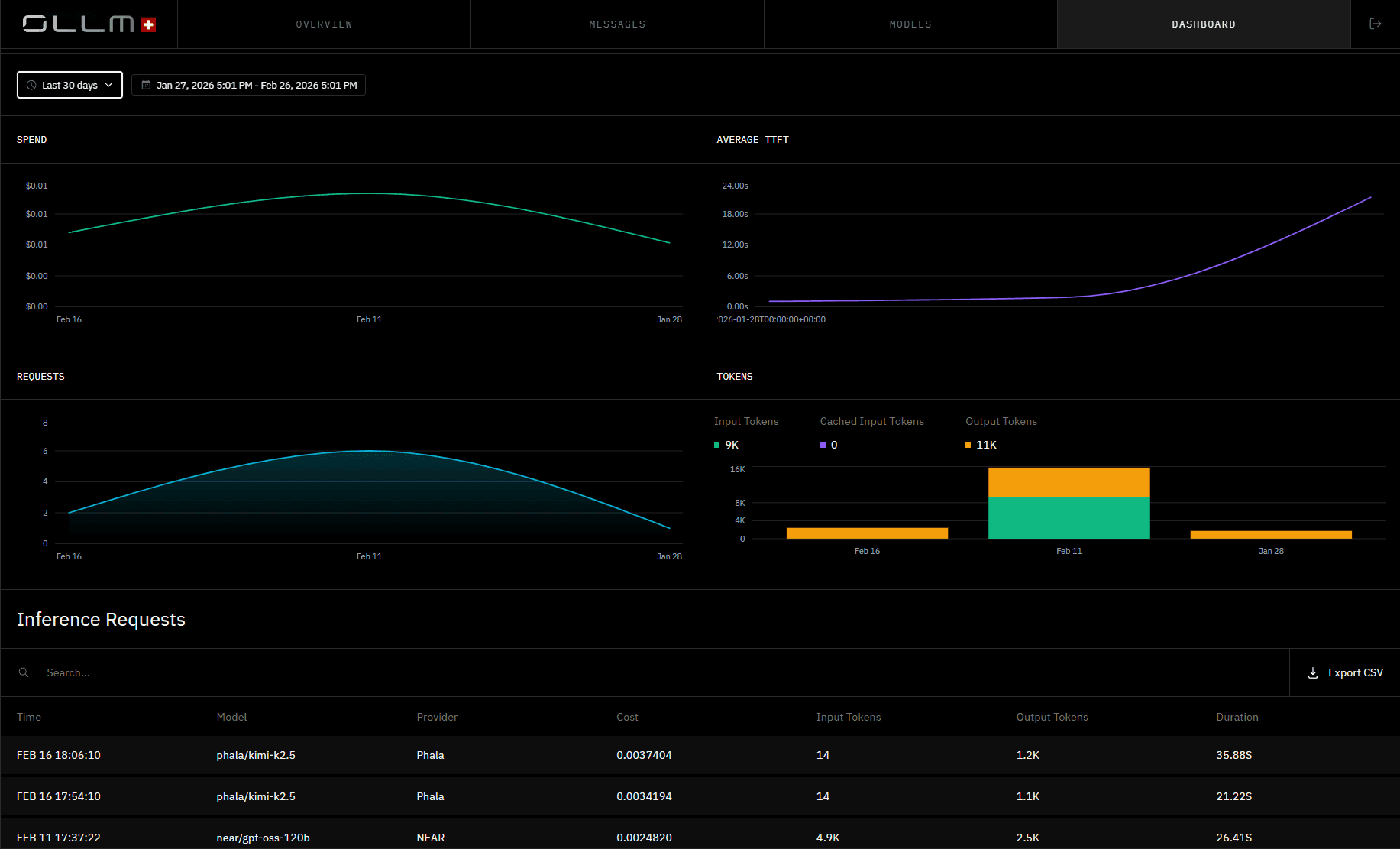
Spend trends, average time-to-first-token, request volume, and per-request cost breakdowns are all visible in one place, exportable to CSV for finance reconciliation or compliance reporting. As usage scales, this view scales with it, without requiring teams to stitch together data from multiple provider consoles.
Security Posture Holds at Scale
Gateway-layer scaling carries one important property: security controls scale with it. TEE-backed execution paths, zero-retention defaults, and attestation reporting apply at the request level, not at a fixed infrastructure boundary that gets bypassed under load. As volume increases, the same enforceable configuration guardrails remain in effect across every request.
Conclusion: Confidential AI Is No Longer Optional for Enterprise Use
The direction of enterprise AI is clear: sensitive workloads are moving into production, regulated industries are tightening requirements, and security can no longer live at the application layer. OLLM brings hardware-backed isolation, cryptographic attestation evidence, zero prompt/response retention by default, and gateway-layer scaling, all configurable at the infrastructure level, consistently across every provider and model.
To see how OLLM fits your enterprise security requirements, explore the documentation or reach out to the team at ollm.com.
FAQs
1. What is a confidential AI gateway, and how is it different from a standard LLM API proxy?
A standard LLM proxy forwards requests and handles authentication. A confidential AI gateway goes further, enforcing zero-retention defaults, routing to hardware-isolated execution environments, and generating cryptographic attestation proofs that verify inference integrity. The security is infrastructure-level, not application-level.
2. How does Intel TDX differ from NVIDIA GPU attestation in LLM inference security?
Intel TDX isolates execution at the VM level, protecting the CPU-side orchestration of a request inside a hardware-enforced confidential boundary. NVIDIA GPU attestation extends that trust to the GPU, where the actual matrix computation for LLM inference runs. Both are needed for end-to-end hardware-backed security across the full inference path.
3. Does OLLM support HIPAA or SOC 2 compliant AI infrastructure?
OLLM's architecture, TEE-backed execution, configurable zero-retention controls, and cryptographic attestation reporting directly support the technical controls required by frameworks like HIPAA and SOC 2. Specific compliance mapping depends on your deployment configuration and organizational requirements.
4. How does OLLM handle zero data retention across multiple LLM providers?
OLLM defaults to not persistently storing prompt or response content at the gateway layer, regardless of which underlying provider handles the request. Usage metadata such as tokens, costs, and timestamps may still be logged for billing and operational purposes.
5. What is TEE cryptographic attestation, and why does it matter for enterprise AI?
TEE attestation is a hardware-generated cryptographic proof that confirms a workload ran inside a genuine, unmodified trusted execution environment. For enterprises, it replaces provider self-reporting with independently verifiable evidence, which is critical in regulated industries where the auditability of AI infrastructure is a compliance requirement.
"/><stop offset="1" stop-color="rgb(80, 78, 87)"/></linearGradient></defs><g d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z M 142.346 0.381 L 162 0.381 L 162 20 L 142.346 20 Z M 153.986 8.381 L 158.375 8.381 L 158.375 12 L 153.986 12 L 153.986 16.571 L 150.36 16.571 L 150.36 12 L 145.972 12 L 145.972 8.381 L 150.36 8.381 L 150.36 4.19 L 153.986 4.19 Z" fill="transparent" height="20px" id="cWM2PbaAz" width="162.00000833847133px"><path d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z" fill="url(%23UyELkL66Q-1582027827-linear-gradient)" height="20px" id="UyELkL66Q" width="134.52277004415487px"/><path d="M 0 0 L 19.654 0 L 19.654 19.619 L 0 19.619 Z" fill="rgb(176, 0, 0)" height="19.618991595424752px" id="t30DbKa7C" transform="translate(142.346 0.381)" width="19.653710120697895px"/><path d="M 8.014 4.19 L 12.403 4.19 L 12.403 7.81 L 8.014 7.81 L 8.014 12.381 L 4.389 12.381 L 4.389 7.81 L 0 7.81 L 0 4.19 L 4.389 4.19 L 4.389 0 L 8.014 0 Z" fill="rgb(255, 255, 255)" height="12.380917026238919px" id="bLcZkJmGc" transform="translate(145.972 4.19)" width="12.402826775197639px"/></g></svg>)