|

TL;DR
AI model management is now an infrastructure problem. Enterprises are consolidating access to large language models behind confidential AI gateways to centralize governance.
Zero prompt and response retention is a fixed infrastructure property. OLLM never stores prompt or response content, what is stored is minimal and fixed: user email, user-agent, token usage, and TEE attestation records including Intel quotes. There is no opt-in, opt-out, or configuration choice.
Hardware-backed isolation strengthens execution trust. Supported models can run in TEE-backed environments using Intel TDX and NVIDIA GPU attestation, with cryptographic attestation artifacts exposed for validation.
Centralized quota enforcement replaces fragmented provider limits. Applications select model aliases directly, while OLLM handles quota enforcement and observability at the gateway layer.
Centralized scaling and observability improve enterprise control. Unified quota management, deployment-level visibility, and consolidated cost tracking enable reliable, auditable production AI operations.
Artificial intelligence now operates as production infrastructure, not experimental tooling. Enterprises deploy large language models across customer support, contract analysis, analytics workflows, and internal assistants. As usage spreads across departments, model integration stops being a feature-level decision and becomes an infrastructure governance problem. Different teams connect to different providers, each with its own logging defaults, retention policies, rate limits, and execution environments. Over time, visibility fragments and policy consistency erode.
Compliance requirements intensify this fragmentation. Regulated environments require enforceable retention controls, auditable execution paths, and clarity about where inference runs and what data persists. App-level conventions cannot guarantee those properties across distributed integrations. Enterprises are responding by consolidating model access behind confidential AI gateways that centralize quota enforcement, retention controls, isolation, and observability at the infrastructure layer.
Enterprises Reduce Data Exposure with Configurable Zero-Retention Controls
Retention boundaries are the first control surface enterprises examine. When application teams integrate providers independently, prompt and response handling varies by environment. Some services enable logging for debugging. Others rely on provider-side statements about storage behavior. Security teams cannot reliably prove whether sensitive inputs are durably stored.
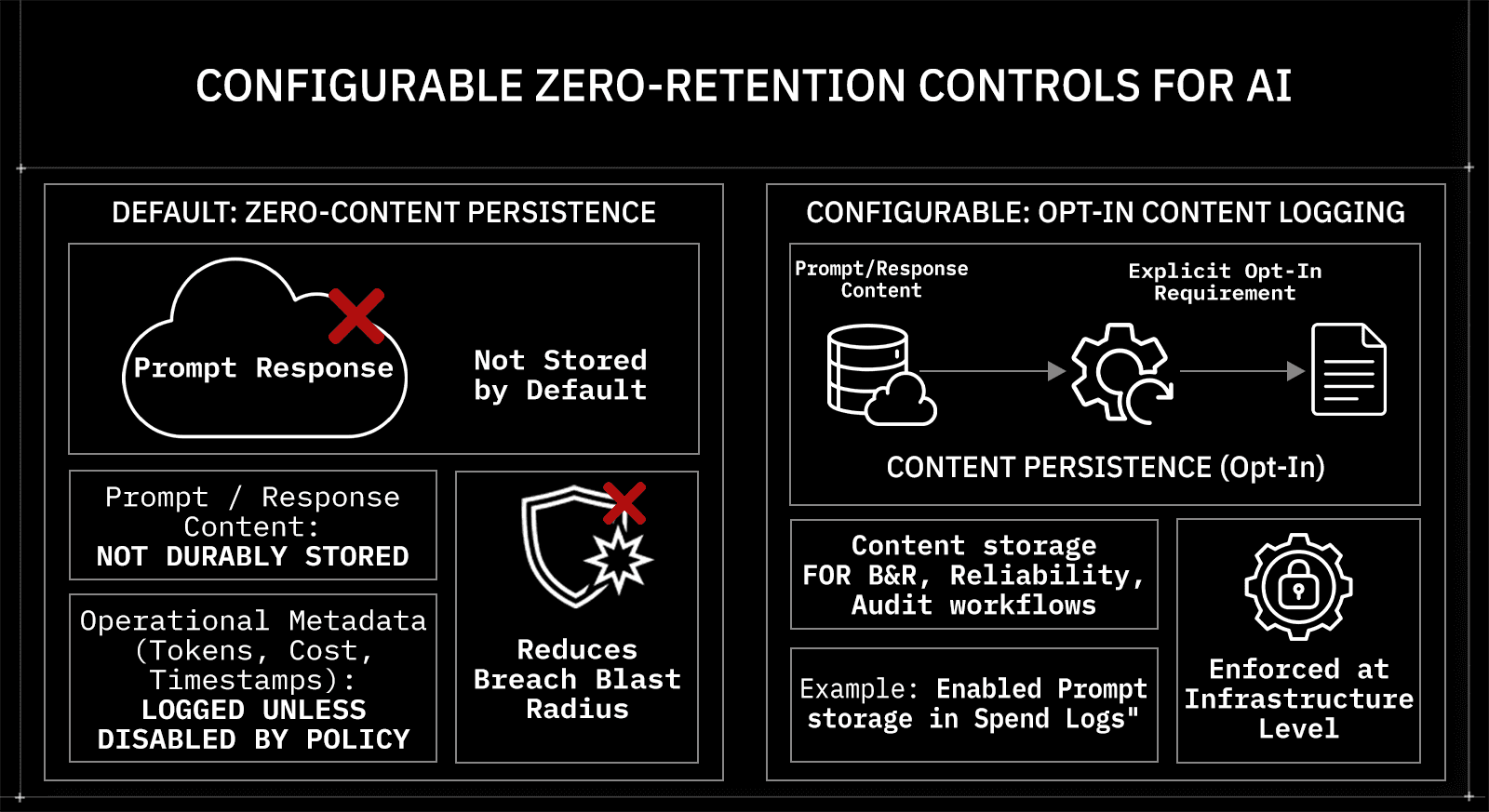
OLLM moves retention enforcement to the gateway layer. Prompt and response content are never stored, this is a fixed property of the infrastructure, not a configurable default. What OLLM does store is minimal and fixed: user email, user-agent data, token usage, and TEE attestation records including Intel quotes. There is no opt-in, opt-out, or logging toggle.
This separation is deliberate:
Prompt/response content: Never stored, fixed infrastructure property
What is stored: User email, user-agent, token usage, TEE attestation records and Intel quotes
Configuration choice: None, storage behavior is fixed, not configurable
Zero-retention in this context refers to the default non-storage of prompt and response payloads at the gateway. It reduces breach blast radius by removing durable content repositories from the inference path. Because there is no configuration choice, retention behavior is an infrastructure guarantee rather than a developer habit or administrator setting. That shift is a primary reason enterprises consolidate AI traffic behind a confidential gateway.
Trusted Execution Environments (TEE) for Hardware-Enforced AI Isolation
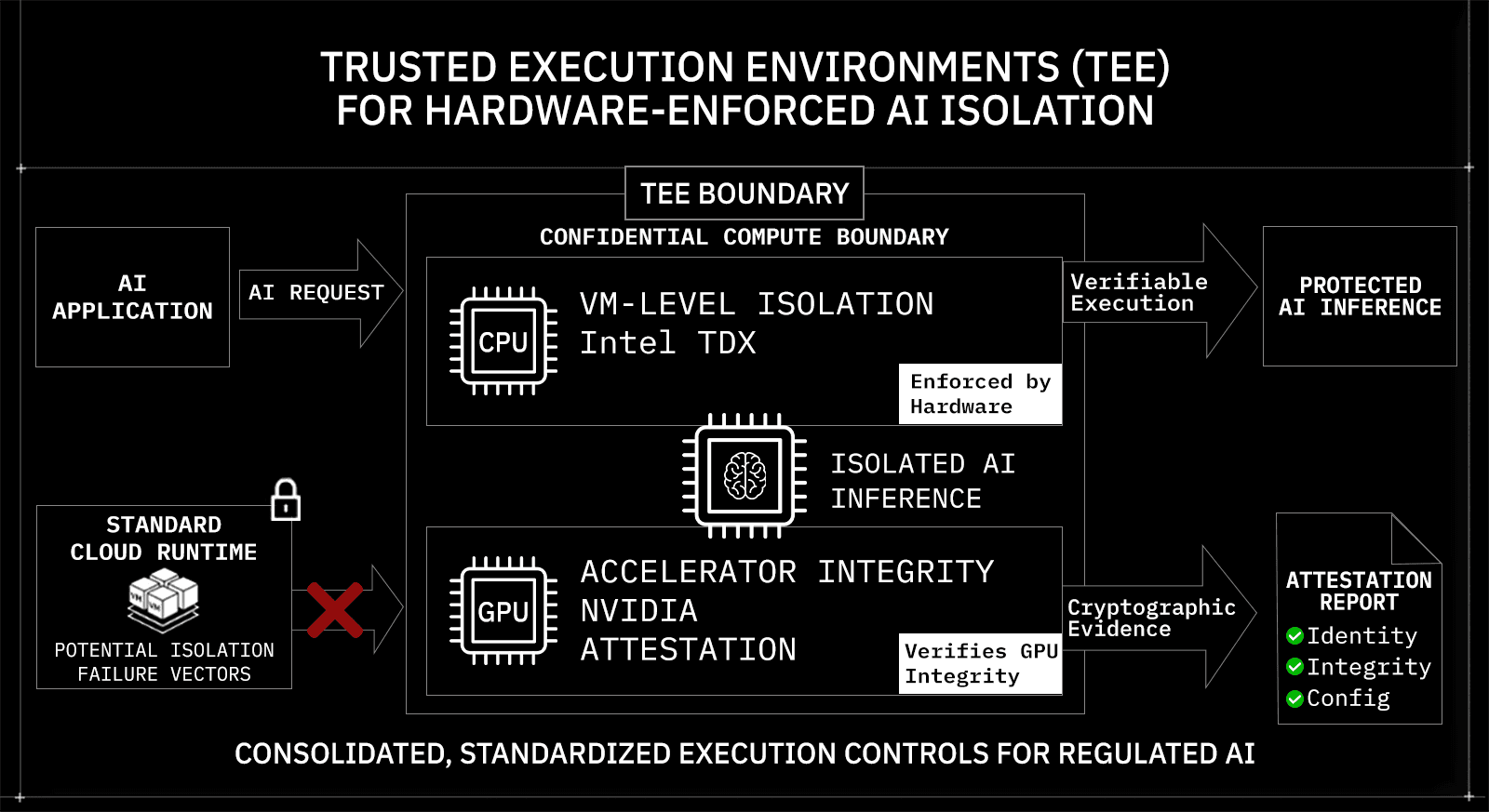
Enterprise security teams no longer stop at TLS; they want to know exactly where inference runs and what prevents co-tenant access on shared hardware. In multi-tenant cloud environments, the primary concern is not direct cross-tenant memory reads by default, but potential co-tenant side-channel or isolation-failure vectors on shared hardware.
OLLM supports TEE-backed execution for supported providers and models. When a TEE-enabled model is selected, the request is routed to a hardware-isolated execution environment. This isolation is backed by technologies such as Intel TDX for VM-level isolation and NVIDIA GPU attestation for accelerator integrity verification. Execution occurs inside a confidential compute boundary rather than a standard shared runtime.
Key isolation characteristics include:
Hardware-enforced isolation using Intel TDX-backed environments
GPU integrity validation through NVIDIA attestation mechanisms
Cryptographic attestation artifacts exposed for verification
Deployment-scoped configuration (TEE paths are model/provider dependent)
Attestation provides cryptographic evidence about the enclave or VM identity and integrity. It strengthens execution trust but does not guarantee end-to-end workflow security beyond the isolated boundary. That distinction matters in regulated environments. Enterprises switch to confidential gateways because hardware-backed isolation provides verifiable execution controls that exceed the assurances offered by standard cloud services.
Enterprises switch to confidential gateways because hardware-backed isolation provides verifiable execution controls that exceed the assurances offered by standard cloud services.
That verification doesn't stay buried in logs, it's surfaced directly at the request level.
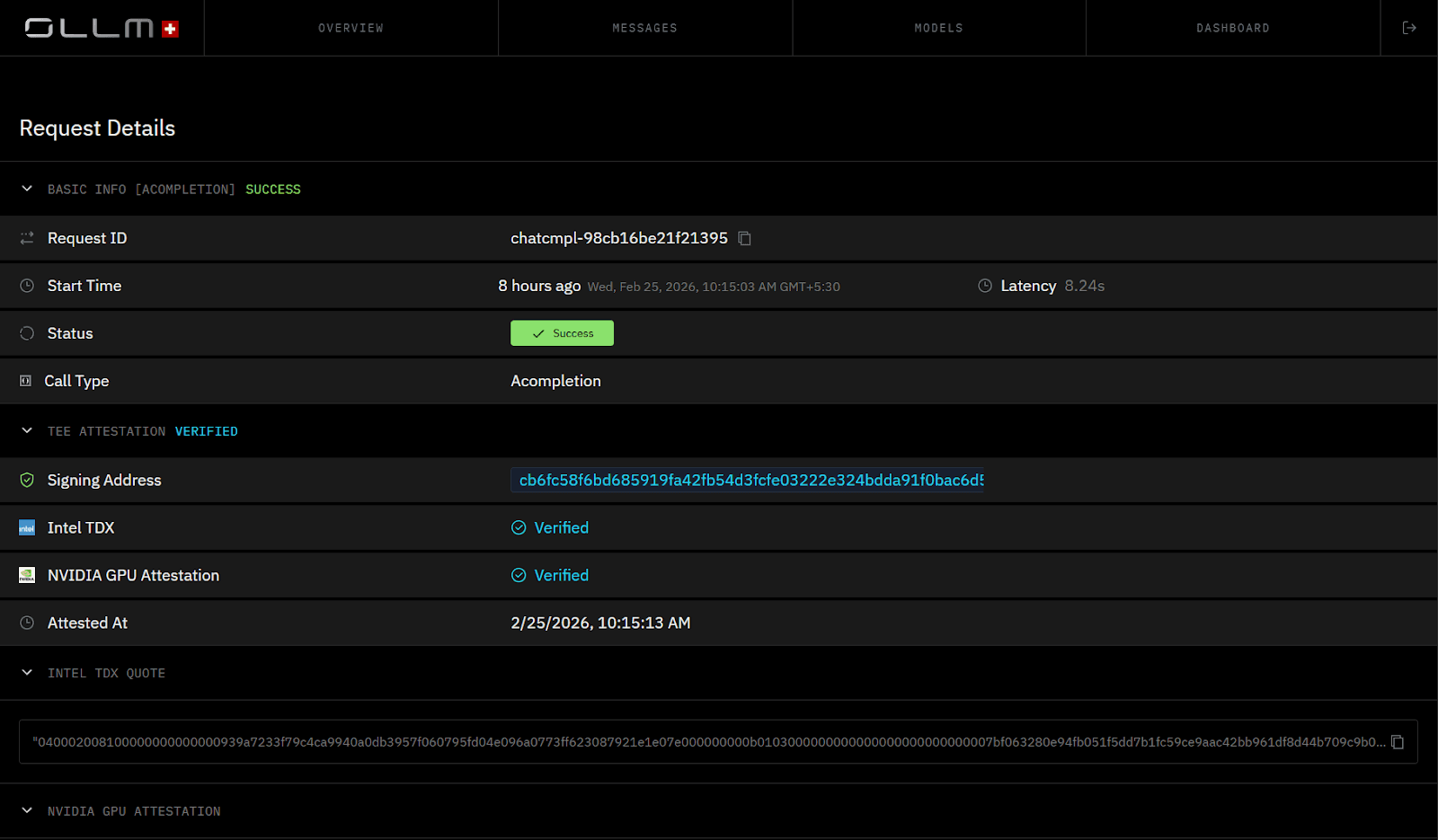
TEE Execution Is Visible at the Request Level
When a request runs in a TEE-backed environment, the dashboard surfaces the verification status alongside the request metadata. Intel TDX and NVIDIA GPU attestation appear as “Verified” when attestation evidence is present for the request“Verified,” with timestamps and signing addresses exposed for audit workflows.
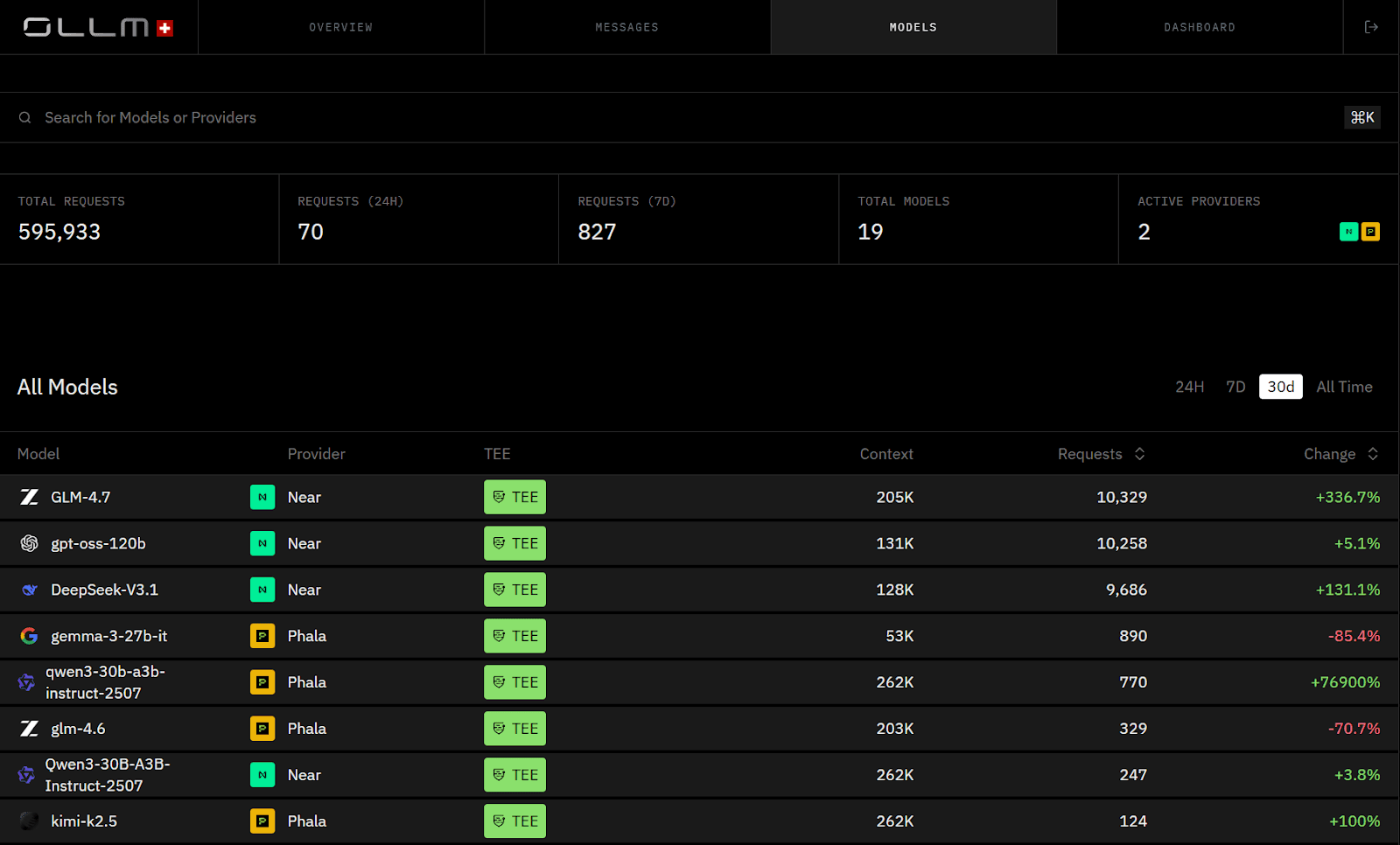
Enterprises Prefer Centralized Scaling Over Fragmented Provider Limits
Isolation and retention solve trust. Scaling solves reliability. As AI workloads move into production, rate limits and quota fragmentation become operational bottlenecks. When teams integrate providers independently, each service implements its own retry logic, backoff strategy, and throttling safeguards. Scaling then depends on negotiating separate provider limits and updating application code when usage grows.
This distributed approach does not hold under enterprise load. Traffic spikes, regional latency differences, and provider-side throttling introduce unpredictable failure patterns across services.
OLLM centralizes quota enforcement at the gateway layer. The application selects a model alias directly. Instead of hardcoding provider coordination into business logic, enterprises manage quota and capacity once at the control plane.
Scaling behavior is configuration-driven. In plan-specific arrangements, enterprises may increase credits or reserve dedicated capacity. Architecturally, scaling is achieved through centralized quota management at the gateway layer. That separation allows AI traffic to grow without requiring repeated changes to application logic.
Model Aliases Abstract Providers Without Changing Application Code
For example, near/GLM-4.6 represents a provider-scoped deployment exposed through the gateway. If the underlying deployment or provider changes, the application code remains unchanged. The alias stays constant while infrastructure policy evolves.
Applications Integrate OLLM Through a Unified OpenAI-Compatible API
Application integration remains minimal because OLLM exposes an OpenAI-compatible API surface. Teams do not rewrite provider-specific logic when switching models or enabling TEE-backed execution. They point to the OLLM base URL and select the approved model alias.
Python SDK example:
|
In this flow:
The application calls a single gateway endpoint
The model string references a provider-scoped deployment (
near/GLM-4.6)Quota enforcement and TEE-backed execution apply at the gateway
TEE-backed execution applies if configured for that model
No provider-specific SDK logic appears in business code.
Direct REST Invocation Through the Gateway
Teams that prefer raw HTTP calls can use the same endpoint.
|
This request:
Passes through OLLM for quota enforcement and TEE-backed execution when enabled
Enforces quota and rate-limit handling
Executes inside TEE-backed infrastructure when enabled
The integration surface remains stable even if the underlying provider changes.
Enterprises Consolidate Observability and Cost Governance Behind a Single Control Plane
Scaling and isolation solve reliability and trust. Governance requires visibility. As AI adoption expands across providers and business units, cost tracking and operational insight fragments quickly. Finance receives multiple provider invoices. Engineering teams inspect separate dashboards. Security teams attempt to correlate inference events with policy configuration across environments. The result is inconsistent reporting at precisely the moment AI spending accelerates.
OLLM consolidates observability at the gateway layer. All model requests pass through a unified API surface, allowing usage metadata to be recorded consistently across deployments. The gateway tracks operational attributes, including token consumption, timestamps, cost attribution, and deployment identifiers. Prompt and response content are never stored. Usage metadata that is retained is fixed: user email, user-agent, token usage, and TEE attestation records. There is no configuration toggle for it.
From a governance standpoint, consolidation delivers measurable benefits:
Cross-model token and cost visibility under a single reporting plane
Timestamped execution metadata for audit and incident correlation
Deployment-level insight into quota usage and execution metadata
Provider-agnostic reporting, independent of upstream dashboards
Upstream provider billing does not disappear, but observability and cost governance become centralized. Enterprises move toward this model because financial accountability and audit readiness must scale with AI usage. Fragmented dashboards cannot provide that control.
Confidential AI Infrastructure Is Becoming a Baseline Enterprise Expectation
Confidential computing is no longer positioned as an advanced security add-on. It is increasingly treated as a baseline requirement for production AI in regulated environments. Boards and risk committees now evaluate AI inference paths under the same level of scrutiny as financial processing systems and regulated data pipelines. The question is not whether encryption exists, but whether execution, retention, and validation controls are enforceable at the infrastructure layer.
This expectation reshapes AI architecture decisions. Retention behavior is enforced at the infrastructure level, prompt and response content is never stored, independent of developer or administrator action. Execution isolation must be hardware-backed where supported. Attestation artifacts must be available to enable enterprises to validate execution integrity under their internal trust policy. OLLM integrates Intel TDX-based isolation, NVIDIA GPU attestation paths, and fixed zero-retention enforcement across supported inference flows, exposing those controls at the gateway layer instead of distributing responsibility across teams.
The shift is structural. Enterprises are not switching because one model performs better than another. They are standardizing on confidential gateways because governance, isolation, and verification are becoming infrastructure defaults. Model flexibility remains important, but execution integrity and retention enforcement now define enterprise readiness.
AI Model Management Is Becoming Infrastructure, Not Application Glue Code
Enterprise AI management is shifting from developer-managed integrations to infrastructure-governed control planes. The difference is structural.
Old Pattern: Application-Centric Model Integration
Each service integrates providers independently
Retention behavior varies across teams
Rate limits handled inside business logic
Execution environment trust based on provider claims
Limited centralized audit visibility
New Pattern: Infrastructure-Centric Model Governance
Application selects a model alias
Zero prompt/response retention enforced at the infrastructure level: fixed, not configurable
TEE-backed execution available for supported providers/models
Attestation artifacts exposed for validation
Centralized quota and observability management
This transition reflects how enterprises now evaluate AI risk. The core question is no longer “Which model performs best?” The question is “Where does inference run, what gets stored, and how is execution verified?”
When AI workloads move into regulated or high-sensitivity environments, infrastructure guarantees matter more than model benchmarks. That is why enterprises are consolidating AI access behind confidential gateways like OLLM, where flexibility, isolation, and executions are centralized rather than distributed across application teams.
Why Enterprises Are Standardizing on Confidential AI Gateways
Enterprise decisions are converging around a few non-negotiables. The shift toward OLLM reflects architectural priorities rather than vendor preference.
Enterprises switch because they need:
Fixed zero prompt/response retention
Prompt and response content is never stored. What is retained is minimal and fixed: user email, user-agent, token usage, and TEE attestation records including Intel quotes. No configuration required or available.
Hardware-backed execution paths
Intel TDX-based isolation, and NVIDIA GPU attestation for supported providers and models.
Attestation-backed trust validation
Cryptographic evidence of enclave or VM integrity that can be integrated into enterprise trust workflows.
Centralized scaling and observability
Unified quota enforcement, deployment management, and cost tracking across providers.
AI governance is no longer handled inside application code. It is enforced at the infrastructure layer. Enterprises are switching to OLLM because confidential execution and centralized governance are becoming foundational requirements for production AI systems.
Conclusion: Enterprise AI Governance Is Moving to the Infrastructure Layer
Enterprise AI adoption has reached the point where model performance alone is not the deciding factor. Retention controls must be enforceable by configuration. Execution environments must support hardware-backed isolation where available. Attestation artifacts must provide verifiable evidence of runtime integrity. Quota enforcement, scaling, and observability must operate through a centralized control plane rather than being scattered across application code. These requirements are driving enterprises toward confidential AI gateways that combine model flexibility with infrastructure-level governance.
If AI workloads in your organization are expanding across teams, providers, and regulatory boundaries, it may be time to evaluate whether model management still lives in application logic or belongs at the infrastructure layer. Explore how OLLM’s confidential gateway architecture can consolidate quota enforcement, zero-retention guarantees, TEE-backed execution paths, and attestation-backed validation into a single control plane built for production AI.
FAQ
1. What does zero-retention mean in an enterprise AI gateway?
Zero-retention in OLLM means prompt and response content is never stored, this is a fixed infrastructure property, not a configurable default. What OLLM does store is minimal and fixed: user email via Privy, user-agent data, token usage, and TEE attestation records including Intel quotes. There is no opt-in, opt-out, or logging toggle. This eliminates the attack surface entirely rather than managing access to stored data.
2. How does OLLM use Intel TDX and NVIDIA GPU attestation for confidential AI inference?
OLLM supports TEE-backed execution for supported providers and models. When a TEE-enabled model is selected, inference is routed to hardware-isolated environments backed by Intel TDX for VM-level confidential compute. NVIDIA GPU attestation mechanisms help validate the integrity of accelerators. The gateway exposes cryptographic attestation artifacts, enabling enterprises to verify the identity and integrity of enclaves or VMs as part of internal trust policy workflows.
3. How does application-level model selection work in OLLM?
In OLLM, model selection is explicit at the application layer, the application specifies the model alias directly in the request, for example near/GLM-4.6. OLLM does not perform dynamic routing, load balancing, or fallback between models. What the gateway does handle is quota enforcement and TEE-backed execution for the selected model when that execution path is available. This means the application has full, explicit control over which model runs, while OLLM handles the execution integrity and quota governance around that selection
4. Why is hardware-backed isolation important for enterprise AI compliance?
Hardware-backed isolation reduces risks associated with shared multi-tenant cloud environments. Technologies such as Trusted Execution Environments (TEEs) provide VM or enclave-level isolation, protecting against potential co-tenant side-channel or isolation-failure vectors. For regulated industries, confidential computing, combined with cryptographic attestation, provides verifiable execution integrity, strengthening the audit and compliance posture.
5. How can enterprises scale multi-provider AI workloads without hitting rate limits?
Enterprise AI scaling in OLLM is handled through centralized quota enforcement at the gateway layer rather than through routing or load balancing. Instead of embedding quota management inside each service, organizations manage capacity once at the OLLM control plane. For teams on plans that require additional capacity, reserved capacity arrangements are available through sales.
"/><stop offset="1" stop-color="rgb(80, 78, 87)"/></linearGradient></defs><g d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z M 142.346 0.381 L 162 0.381 L 162 20 L 142.346 20 Z M 153.986 8.381 L 158.375 8.381 L 158.375 12 L 153.986 12 L 153.986 16.571 L 150.36 16.571 L 150.36 12 L 145.972 12 L 145.972 8.381 L 150.36 8.381 L 150.36 4.19 L 153.986 4.19 Z" fill="transparent" height="20px" id="cWM2PbaAz" width="162.00000833847133px"><path d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z" fill="url(%23UyELkL66Q-1582027827-linear-gradient)" height="20px" id="UyELkL66Q" width="134.52277004415487px"/><path d="M 0 0 L 19.654 0 L 19.654 19.619 L 0 19.619 Z" fill="rgb(176, 0, 0)" height="19.618991595424752px" id="t30DbKa7C" transform="translate(142.346 0.381)" width="19.653710120697895px"/><path d="M 8.014 4.19 L 12.403 4.19 L 12.403 7.81 L 8.014 7.81 L 8.014 12.381 L 4.389 12.381 L 4.389 7.81 L 0 7.81 L 0 4.19 L 4.389 4.19 L 4.389 0 L 8.014 0 Z" fill="rgb(255, 255, 255)" height="12.380917026238919px" id="bLcZkJmGc" transform="translate(145.972 4.19)" width="12.402826775197639px"/></g></svg>)