|

TLDR
Most AI systems encrypt data at rest and in transit but expose it during inference, where prompts, intermediate tensors, and outputs exist in plaintext memory.
Trusted Execution Environments (TEEs) secure data while code is running and use hardware-backed attestation to prove where and how execution occurred.
Large language model inference breaks traditional TEE assumptions because execution spans CPUs and GPUs, and CPU-only isolation leaves GPU execution unverified.
OLLM enforces confidential inference per request using Intel TDX for CPU isolation, NVIDIA GPU attestation for model execution, and cryptographic binding of execution proof to responses.
By exposing execution mode, attestation status, and verification artifacts directly, OLLM turns confidential AI from a policy claim into verifiable, auditable runtime behavior.
What are Trusted Execution Environments
Trusted Execution Environments exist to protect the most exposed phase of modern systems: execution. In a typical production stack, security controls stop once computation begins. Data arrives encrypted, is stored encrypted, and is then decrypted into memory so the CPU or GPU can operate on it. At that point, the operating system, hypervisor, and cloud operator become part of the trust boundary by default. TEEs change this execution model by moving trust enforcement into the processor itself.
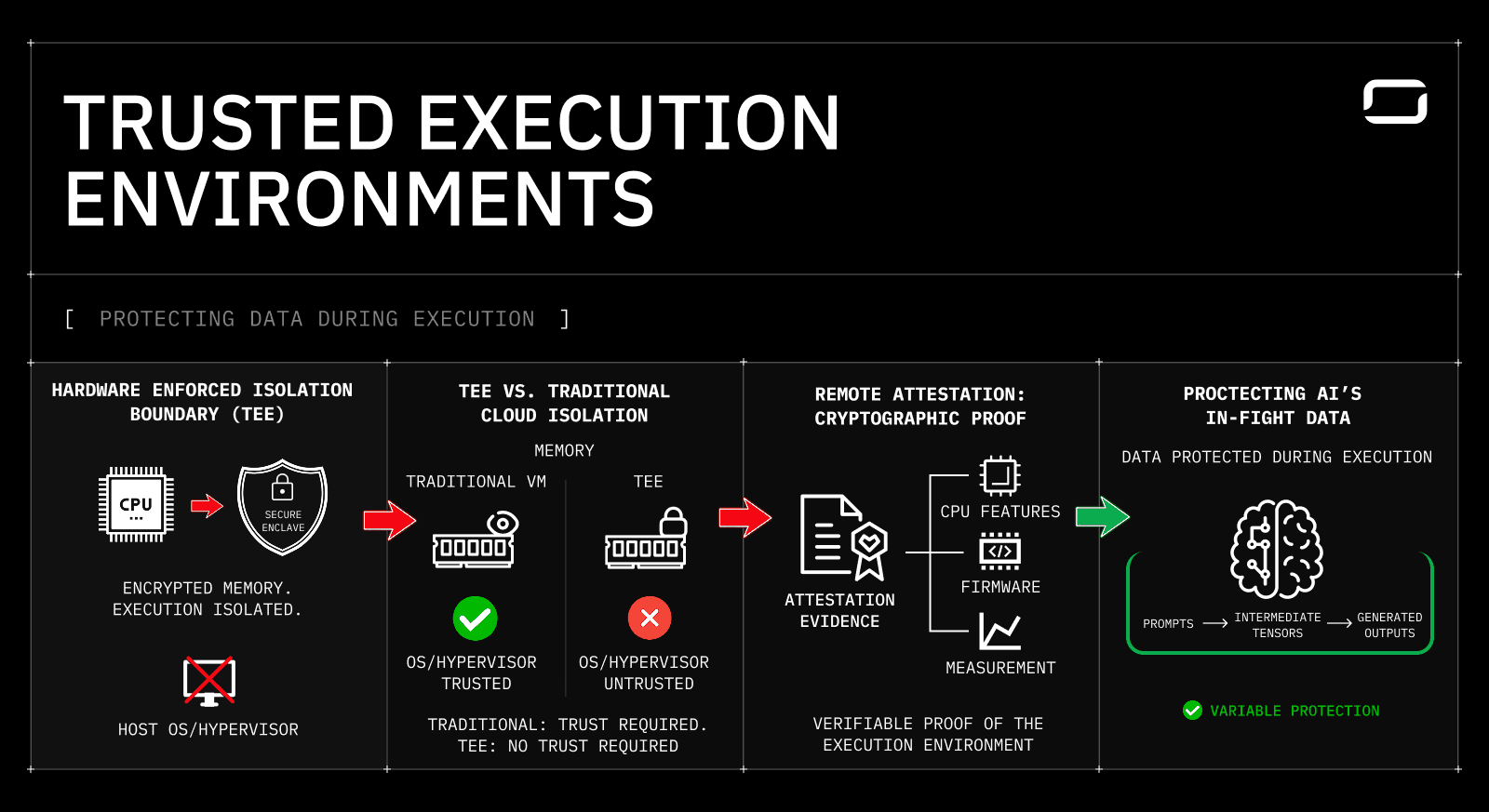
What a Trusted Execution Environment actually is
A Trusted Execution Environment is a hardware-enforced isolation boundary created by the CPU. Code within this boundary runs with guarantees that are independent of the host system.
At a systems level, a TEE provides:
Encrypted memory, with keys managed by the processor and never exposed to the host
Execution isolation, preventing the OS or hypervisor from inspecting the runtime state
A reduced trust boundary, where the CPU is trusted, and everything else is treated as untrusted
This model removes entire classes of attacks that rely on privileged access outside the processor.
How TEEs differ from traditional cloud isolation
Traditional isolation relies on software layers that still require trust.
Execution Layer | Traditional VM | Trusted Execution Environment |
Memory contents | Visible to host | Encrypted and inaccessible |
OS access | Full visibility | No inspection allowed |
Hypervisor trust | Required | Not trusted |
Cloud operator trust | Required | Not required |
This distinction is why TEEs matter specifically for workloads that handle sensitive data during computation.
Why attestation is part of the TEE model
Isolation alone does not help in distributed systems unless it can be proven. TEEs include remote attestation, which allows the hardware to produce cryptographic evidence about the execution environment.
Attestation typically proves:
Which CPU features were enabled
Which firmware and microcode were loaded
Which execution measurements were present at runtime
This evidence can be verified externally against known-good configurations, turning secure execution into a verifiable property rather than an internal claim.
What TEEs Actually Protect During Model Inference
AI inference handles sensitive data that exists only while the model is running. Unlike stored datasets or API payloads, this data is created dynamically and typically exposed in plaintext during execution.
In practice, this includes:
Prompts and inputs, such as incident logs, stack traces, source code snippets, customer messages, or internal documentation passed to an LLM for analysis.
Intermediate tensors and activations, which may encode sensitive patterns derived from the input, including proprietary logic, customer identifiers, or reconstructed data fragments inside the model’s hidden layers.
Generated outputs, such as remediation steps, summaries of private incidents, or responses that combine internal context with model reasoning.
All of this data exists only while inference is running. Traditional encryption does not cover this phase. Trusted Execution Environments protect these artifacts while they are actively processed and produce cryptographic evidence that the protection was enforced. In the earlier incident-triage scenario, this is the difference between trusting a provider’s privacy policy and being able to show exactly where and how the prompt was executed.
When “Private” AI Fails Under a Real Production Debug Session
A backend engineer wires an internal service to a large language model to help with incident triage. Logs, stack traces, and partial customer payloads flow through the prompt. The feature works, and latency is acceptable. Then a routine security review asks a question no dashboard can answer: Where exactly did this prompt execute, and who could see it while it was running?
The provider promises no logging. The cloud VM looks locked down. The GPU is shared. At that point, the issue is no longer about APIs or performance. It becomes a question of runtime trust that the system cannot prove.
Why runtime trust breaks down in modern AI systems
Most AI stacks encrypt data at rest and in transit, then quietly decrypt it for inference on CPUs and GPUs fully controlled by the operator. During execution, prompts, intermediate tensors, and outputs live in plaintext memory. This gap is invisible during development and painful in production, especially for teams handling proprietary code, customer data, or regulated workloads.
What’s missing is a way to cryptographically guarantee that sensitive data remains isolated while models are running, and to prove that guarantee after the fact. That is precisely the problem Trusted Execution Environments were designed to solve.
What this article covers
Drawing on real production mechanics from confidential AI gateways, this article explains how Trusted Execution Environments work at runtime, why GPU attestation matters as much as CPU isolation, and how engineers can move from policy-based trust to cryptographic proof. By the end, the original debugging story changes: instead of trusting provider claims, teams can point to concrete evidence showing where an inference ran, on what hardware, and under what guarantees.
Why Large Language Model Inference Stretches Traditional Trusted Execution Models
Large language model inference does not fit the execution model for which early Trusted Execution Environments were designed. Traditional TEEs were designed for small, CPU-bound workloads with limited memory and clearly scoped execution. LLM inference follows a much broader execution path, in which sensitive data flows across multiple components before a response is produced.
LLM inference spans multiple execution layers
A single inference request typically crosses:
CPU-side execution for request parsing, tokenization, routing, and batching
Model orchestration logic that prepares inputs and schedules work
GPU execution where model weights are loaded and computation occurs
Memory transfers between CPU and GPU address spaces
Sensitive inputs and intermediate data do not remain confined to one protected memory region. They flow across this entire path, increasing exposure if execution guarantees are not preserved end-to-end.
The CPU–GPU boundary is where confidentiality often breaks
CPU-based TEEs can encrypt memory and isolate request-handling logic, but inference usually requires handing data off to the GPU in decrypted form. Historically, GPUs have operated outside the CPU trust boundary:
GPU memory has not been confidential by default
Firmware and drivers run independently of CPU isolation guarantees
Schedulers can move workloads across heterogeneous hardware
This creates a structural gap where systems claim confidential execution while the most sensitive computation runs without verifiable protection.
Why partial TEEs are not sufficient for AI workloads
For AI inference, confidentiality must apply to the entire execution path, not just the entry point. A viable confidential inference model, therefore, needs to:
Protect CPU-side execution for request ingestion, routing, and metadata handling
Verify GPU execution using hardware-backed attestation of identity and firmware
Prevent silent downgrade paths that fall back to non-confidential hardware
When these conditions are not enforced together, runtime trust remains incomplete. When they are, confidential execution becomes a property of the full inference pipeline rather than a claim associated with a single component.
How OLLM Executes Confidential Inference End to End
OLLM’s confidential inference pipeline is designed around a simple but strict rule: trust is evaluated and proven on a per-request basis, not assumed at the platform level. Instead of abstracting away execution details, OLLM makes each stage of confidential execution explicit and observable to the developer. The easiest way to understand this is to follow a single inference request through the system.

1. Request entry into a confidential CPU boundary (Intel TDX)
Every request first enters a confidential execution boundary backed by Intel Trusted Domain Extensions (TDX). This is where request parsing, routing logic, and provider selection take place.
At this stage:
Memory is encrypted and inaccessible to the host OS or hypervisor
Hardware measurements are collected by the CPU
The execution context is bound to a specific confidential VM
What matters here is not just isolation, but measurement. OLLM does not rely on static configuration to claim secure routing. It collects hardware-backed evidence so the request can later be tied to a verified CPU execution environment.
What OLLM exposes to developers
CPU execution mode (TDX)
Attestation status for the request
Timestamped evidence tied to execution
2. GPU attestation before model execution
Once routing decisions are made, the request transitions to model execution. This is the point where most “confidential AI” designs weaken, and where OLLM is deliberately strict.
Before inference begins:
The GPU’s identity, firmware, and configuration are attested
Attestation determines whether execution can be cryptographically verified
Requests that do not meet GPU trust requirements may still execute, but are explicitly marked as failed for confidential execution
This prevents silent downgrade paths where inference falls back to cheaper or less secure GPUs under load.
What OLLM exposes to developers
GPU attestation status (verified or failed)
GPU architecture and provider
The specific model and provider selected for execution
3. Response binding and cryptographic proof generation
After inference completes, OLLM binds the execution context to the response itself. Attestation evidence from both the CPU and GPU layers is associated with the request, and cryptographic proofs are generated over execution metadata.
This step ensures that:
The response cannot be replayed or modified without detection
Execution proof remains valid after the request lifecycle ends
Verification does not depend on trusting OLLM as an intermediary
What OLLM exposes to developers
Cryptographic signatures over execution metadata
CPU + GPU attestation evidence bound to the response
Identifiers that allow independent verification
4. Developer-side verification instead of assumed trust
The final result is not just a model response, but a response accompanied by concrete, inspectable signals. Developers can see, per request:
Whether confidential execution was enforced
Where the request ran
On which hardware the model executed
Whether attestation succeeded or failed
OLLM does not hide this behind a single “secure” label. It exposes execution mode, attestation status, provider selection, and cryptographic proof directly in the interface. In the original incident-triage scenario, this is the point where the conversation changes. Instead of trusting a provider’s privacy claim, engineers can cite verifiable runtime evidence that describes exactly how the inference was executed.
What “Verified” Actually Means at the Level of a Single Inference Request
In OLLM, “Verified” is not a platform-level claim or a security label applied after the fact. It is the outcome of a single inference request that successfully executed under approved confidential conditions. Verification exists because trust failures occur at runtime, not at deployment, and OLLM records proof at execution time.
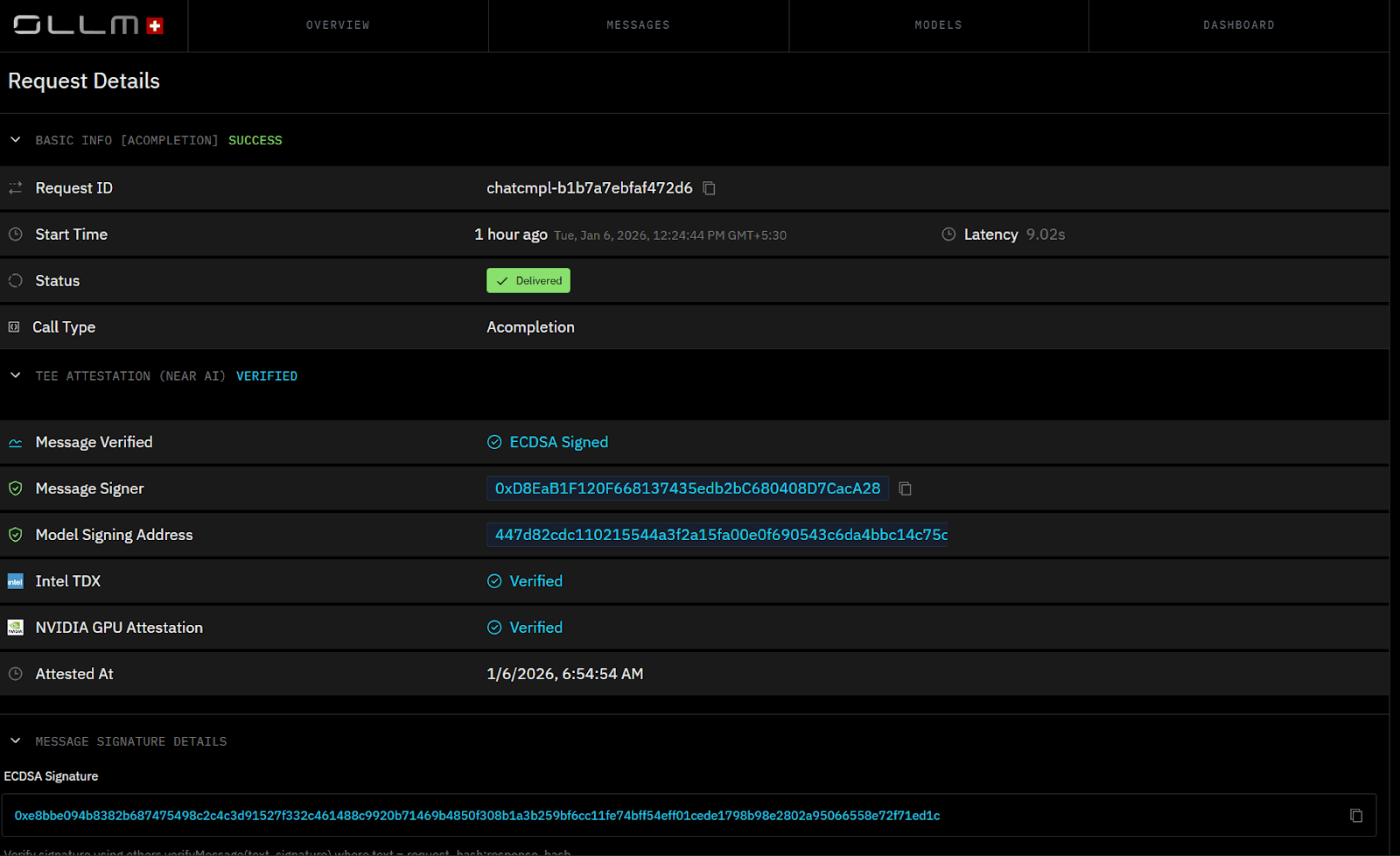
A request is marked as Verified only when OLLM can produce hardware-backed evidence that both CPU-side and GPU-side execution met confidentiality requirements. This evidence is collected during execution and bound to the request itself, rather than inferred from configuration or routing policy.
What “Verified” corresponds to in the OLLM UI
When you inspect a verified request in OLLM, you are not looking at a summary judgment. You are looking at concrete execution signals:
Execution mode, indicating confidential execution was enforced
CPU attestation source, showing Intel TDX was used for request handling
GPU attestation source, showing NVIDIA attestation was validated before inference
Attestation timestamps, tied to the actual execution window
Cryptographic artifacts, including signatures and identifiers that can be independently verified
These fields are exposed directly in the request details view. OLLM does not collapse them into a single green checkmark or abstract them away behind a trust score.
How OLLM Surfaces Trust Failures During Execution
Verification in OLLM is binary at the request level. If execution occurs on non-attested hardware, OLLM surfaces the trust failure instead of silently presenting the request as confidential. It fails verification explicitly. This is a deliberate design choice: trust violations are surfaced in the same way as latency spikes or execution errors.
For experienced engineers, this is the critical shift. “Verified” does not mean OLLM asserts the request was secure. It means the system can produce cryptographically verifiable evidence describing where the request ran, on which hardware, and under which execution guarantees. That evidence exists independently of OLLM itself, which is why it holds up in audits, incident reviews, and compliance workflows.
Message Integrity: Why OLLM Cryptographically Binds Proof to Inference Outputs
Attestation establishes where execution occurred, but it does not guarantee that the response returned to the client is the result of that execution. A CPU and GPU can both attest successfully, yet the output can still be replayed, modified, or substituted after inference completes. In security terms, attestation without response binding leaves a gap between verified execution and delivered output.
OLLM closes this gap by extending the trust boundary beyond execution and into the response itself. Inference outputs are not treated as opaque artifacts emitted by the system. They are cryptographically bound to the execution context that produced them.
How OLLM binds execution context to responses
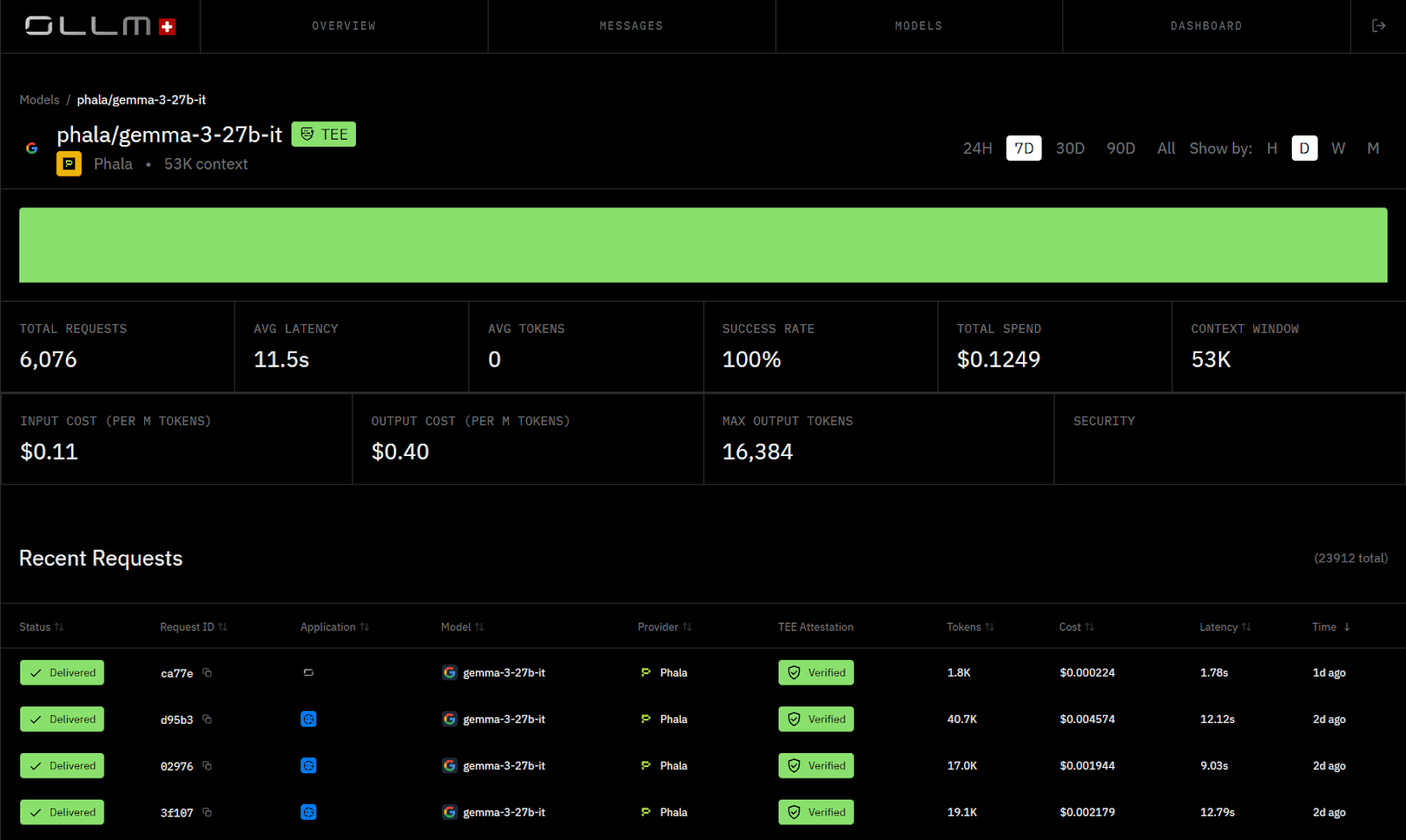
For every verified inference request, OLLM:
Computes hashes over the input prompt, execution metadata, and model output
Signs those hashes using ECDSA keys associated with the verified execution path
Links the signature to both CPU (Intel TDX) and GPU (NVIDIA) attestation evidence
This creates a tamper-evident chain between the execution environment and the returned response.
Failure modes this design eliminates
Responses cannot be replayed across requests without detection
Outputs cannot be modified downstream without invalidating the signature
Intermediaries cannot substitute responses silently
Verification does not depend on trusting OLLM as an intermediary. Consumers can validate signatures independently, after the fact, using the exposed cryptographic artifacts. This is the point where confidential inference becomes auditable rather than declarative.
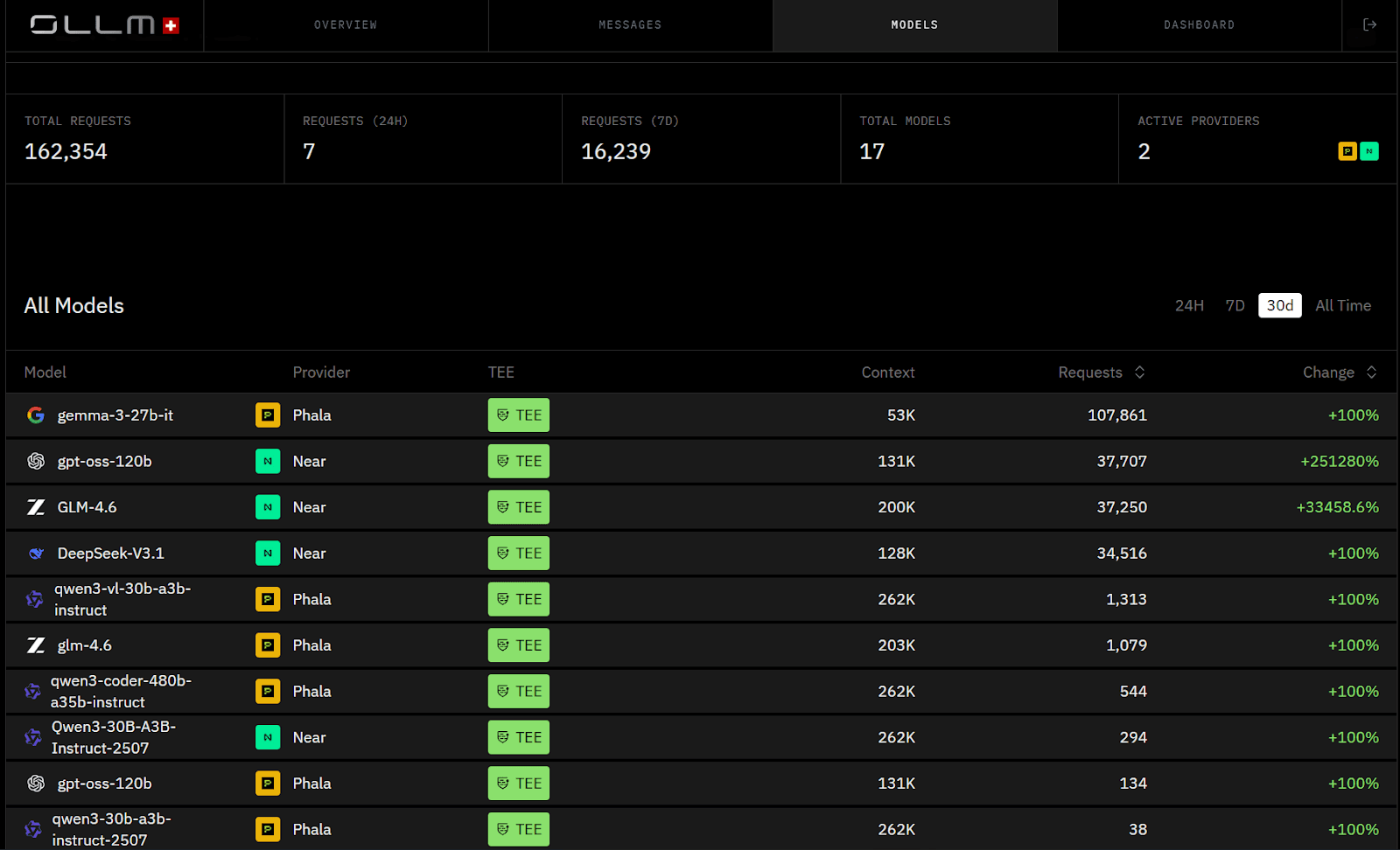
Why Model Aggregation Makes Confidential Execution Harder and Why OLLM Enforces It Anyway
Aggregating inference across multiple providers introduces structural trust risk. Each provider operates different infrastructure stacks, GPU generations, firmware versions, and operational controls. Without enforcement, routing decisions made for availability or cost can silently weaken confidentiality guarantees.
OLLM treats aggregation as part of the execution trust boundary rather than an abstraction layer.
Why aggregation complicates confidential execution
When requests are routed dynamically:
Hardware characteristics differ across providers
GPU confidentiality capabilities vary
Execution guarantees can degrade under load or failover
In many platforms, these differences are hidden behind a unified API. In OLLM, they are enforced and surfaced.
How OLLM enforces uniform execution guarantees
Across all routed requests, OLLM applies the same trust contract:
CPU-side execution must run inside Intel TDX
GPU execution must pass NVIDIA attestation before inference
Non-compliant execution paths are surfaced explicitly, not silently downgraded
Verification failures are exposed explicitly at the request level
What aggregation looks like from the developer’s perspective
Instead of opaque routing, the OLLM interface shows:
Which model and provider executed the request
Whether CPU and GPU attestation succeeded
Whether the execution met confidential requirements or failed
This turns model aggregation from an implicit risk into an auditable control plane. Engineers retain visibility into where inference runs, while security teams retain confidence that execution guarantees do not change silently as requests scale.
Conclusion: Confidential AI Only Works When Execution Is Verifiable
The production debugging incident that prompted this article was not due to API failures, latency, or model quality. It was a failure of evidence. The system worked, but it could not prove its correctness at runtime. Once sensitive data entered the inference path, trust depended on provider assurances rather than on verifiable guarantees. That gap is what blocks confidential AI from scaling into regulated and enterprise environments.
Trusted Execution Environments close that gap by shifting trust enforcement into hardware and pairing it with cryptographic proof. When applied correctly to AI inference, TEEs protect data while it is actively being processed and produce evidence that survives beyond the request lifecycle. But CPU isolation alone is not enough. Confidential inference requires GPU attestation, response binding, and strict handling of execution failures to ensure that guarantees do not degrade silently under load or routing changes.
OLLM demonstrates what this looks like in practice. It treats confidential execution as a request-level property, enforces both CPU and GPU attestation before inference, binds execution proof directly to model outputs, and exposes all of this to developers rather than hiding it behind abstractions. The result is not just “private AI,” but AI systems that can answer the question security teams actually ask: where did this inference run, on what hardware, and under what guarantees?
What to do next
If you are building or operating AI systems that handle proprietary code, customer data, or regulated workloads, the fastest way to evaluate this model is to try it directly. OLLM does not require upfront commitments or long-term contracts. You pay only for the inference requests you run, and every request surfaces the execution signals described in this article.
That makes it possible to test confidential inference the same way engineers test any other production system: by observing real behavior, measuring trade-offs, and verifying guarantees with concrete evidence rather than assumptions.
FAQ
1. How does OLLM use Trusted Execution Environments for AI inference?
OLLM enforces confidential AI inference at the request level using hardware-backed Trusted Execution Environments. CPU-side execution runs inside Intel TDX–protected virtual machines, while GPU-side execution requires NVIDIA GPU attestation before inference begins. Execution proof, attestation metadata, and cryptographic signatures are generated per request and exposed directly to developers, making runtime confidentiality verifiable rather than assumed.
2. Does OLLM store prompts or inference data when using confidential execution?
No. OLLM is designed as a confidential AI gateway that routes inference requests without retaining prompt or output data. Confidential execution ensures data remains protected at runtime, while cryptographic verification allows developers to verify how execution occurred without requiring data retention or trusting the provider.
3. What does TEE mean in AI systems?
In AI systems, a Trusted Execution Environment (TEE) is a hardware-enforced execution boundary that protects data while models run. Unlike encryption at rest or in transit, TEEs secure prompts, intermediate tensors, and outputs during computation and provide cryptographic attestation to prove that execution occurred inside a protected environment.
4. What is a trusted execution engine, and how is it used in practice?
A trusted execution engine is a hardware-backed mechanism that isolates execution from the operating system and hypervisor. Technologies such as Intel Trusted Domain Extensions (TDX) enable confidential virtual machines where memory is encrypted, and the runtime state cannot be inspected. In AI inference, trusted execution engines ensure that sensitive data is protected while models are processing it.
5. What is a Trusted Execution Environment also known as?
A Trusted Execution Environment is also commonly referred to as a secure enclave or confidential execution environment. These terms describe protected execution regions created by hardware that enforce isolation, memory encryption, and attestation to preserve the confidentiality and integrity of code and data during runtime.
"/><stop offset="1" stop-color="rgb(80, 78, 87)"/></linearGradient></defs><g d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z M 142.346 0.381 L 162 0.381 L 162 20 L 142.346 20 Z M 153.986 8.381 L 158.375 8.381 L 158.375 12 L 153.986 12 L 153.986 16.571 L 150.36 16.571 L 150.36 12 L 145.972 12 L 145.972 8.381 L 150.36 8.381 L 150.36 4.19 L 153.986 4.19 Z" fill="transparent" height="20px" id="cWM2PbaAz" width="162.00000833847133px"><path d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z" fill="url(%23UyELkL66Q-1582027827-linear-gradient)" height="20px" id="UyELkL66Q" width="134.52277004415487px"/><path d="M 0 0 L 19.654 0 L 19.654 19.619 L 0 19.619 Z" fill="rgb(176, 0, 0)" height="19.618991595424752px" id="t30DbKa7C" transform="translate(142.346 0.381)" width="19.653710120697895px"/><path d="M 8.014 4.19 L 12.403 4.19 L 12.403 7.81 L 8.014 7.81 L 8.014 12.381 L 4.389 12.381 L 4.389 7.81 L 0 7.81 L 0 4.19 L 4.389 4.19 L 4.389 0 L 8.014 0 Z" fill="rgb(255, 255, 255)" height="12.380917026238919px" id="bLcZkJmGc" transform="translate(145.972 4.19)" width="12.402826775197639px"/></g></svg>)