|

TL;DR
AI gateways centralize LLM access behind a control plane. They standardize routing, TLS encryption in transit, policy enforcement, rate limiting, and telemetry across multiple model providers.
Not all enterprise AI gateways offer the same level of security. Many focus on governance and observability, while encryption-in-use (confidential compute) and strict non-retention are less common.
High-sensitivity deployments prioritize non-retention and TEE attestation. Non-storage of prompt/response content reduces breach surface, while Intel TDX and NVIDIA GPU attestation provide cryptographic proof of secure execution.
Other platforms focus on ecosystem alignment or observability. Portkey emphasizes governance and monitoring, OpenRouter prioritizes model flexibility, while Azure and AWS integrate AI routing within their native cloud security stacks.
Choosing the right AI gateway depends on the depth of compliance and scaling needs. Regulated enterprises should prioritize execution verification, non-retention architectures, and centralized policy enforcement before expanding production AI workloads.
Enterprise AI has moved from experimentation to production systems. Large language models now power customer support bots, internal copilots, workflow automation, and analytics tools. Integrating multiple model providers directly creates fragmentation. Each provider defines its own SDK, authentication model, rate limits, logging format, and data-handling policy. This sprawl increases engineering overhead and expands compliance risk.
AI gateways centralize and secure model access. An AI gateway sits between enterprise applications and model providers, routing requests through a single API while enforcing encryption, policy controls, rate limits, and audit logging. Advanced gateways add zero-data-retention architectures and trusted execution environments to prevent prompt storage and to verify secure execution. In production environments, the gateway becomes the control plane for secure, compliant, and scalable AI deployment.
What Makes an AI Gateway Enterprise-Ready and Security-Centric
Enterprise AI gateways must operate as security control planes. Production AI systems process sensitive customer data, proprietary models, financial records, and internal knowledge assets. A lightweight proxy that simply forwards API calls does not address these risks. An enterprise-ready gateway must enforce security policies, verify execution environments, and standardize controls across every model request.
Security architecture defines enterprise readiness. Zero data retention removes one of the largest risk vectors in AI deployments. When prompts and responses are never stored, no persistent database exists for attackers to target. Encryption at every layer further reduces exposure. Data must remain encrypted in transit and protected while in memory during processing. Without these controls, model traffic becomes another unmanaged data pipeline.
Execution verification strengthens compliance posture. Trusted Execution Environments (TEE) allow workloads to run inside hardware-isolated secure enclaves. Cryptographic attestation proves that code executes in an untampered environment. This proof can be independently validated, supporting regulated industries that require verifiable security guarantees rather than policy statements.
Operational control enables predictable scaling. Enterprise gateways must centralize rate limiting, traffic shaping, audit logging, and provider routing. Multi-model aggregation prevents vendor lock-in and reduces engineering overhead. Centralized observability simplifies incident response and compliance audits. When these capabilities are built into a single control plane, AI infrastructure becomes measurable, enforceable, and scalable.
The following capabilities typically define enterprise-grade AI gateways:
Capability | Enterprise Impact |
Zero data retention | Eliminates stored prompt databases and reduces breach surface |
Encryption in transit + TEE-backed execution (where supported) | Protects model traffic in transit and memory |
TEE cryptographic attestation | Verifies secure execution environments |
Multi-provider routing | Prevents vendor lock-in |
Centralized policy enforcement | Standardizes governance controls |
Rate limiting and capacity management | Supports high-volume production workloads |
Audit logging and observability | Enables compliance reporting and forensic analysis |
These characteristics determine whether an AI gateway can support regulated, high-scale enterprise deployments rather than experimental AI integrations.
Top AI Gateways Leading Secure Enterprise Deployments
The criteria above define the requirements for enterprise AI infrastructure. Security enforcement, zero retention, execution verification, and centralized control are no longer optional in regulated environments. The next step is to identify which platforms implement these requirements in production systems.
The following AI gateways stand out for secure enterprise deployments. Each provides model routing and abstraction, but their levels of security, compliance posture, and architectural guarantees differ significantly. The first platform on this list prioritizes verifiable privacy, zero data retention, and hardware-backed execution security.
1. OLLM: The World’s First Enterprise AI Gateway Aggregating High-Security Confidential Compute Providers

OLLМ positions itself as the world’s first enterprise AI gateway designed to aggregate high-security, confidential compute LLM providers behind a single API. It functions as a secure routing and enforcement layer rather than a simple proxy. Enterprises integrate once and gain access to multiple models while maintaining strict encryption, execution isolation, and zero-data-retention guarantees. This architecture reduces vendor sprawl while strengthening governance and compliance posture.
Core Confidential Compute and Zero Retention Architecture
Zero data retention defines OLLM’s privacy foundation. The platform does not store prompts or responses, and there is no centralized database of customer AI traffic. Once a request completes, no retrievable prompt history remains. This eliminates persistent storage risk and significantly reduces the exposure to breaches associated with stored LLM interactions.
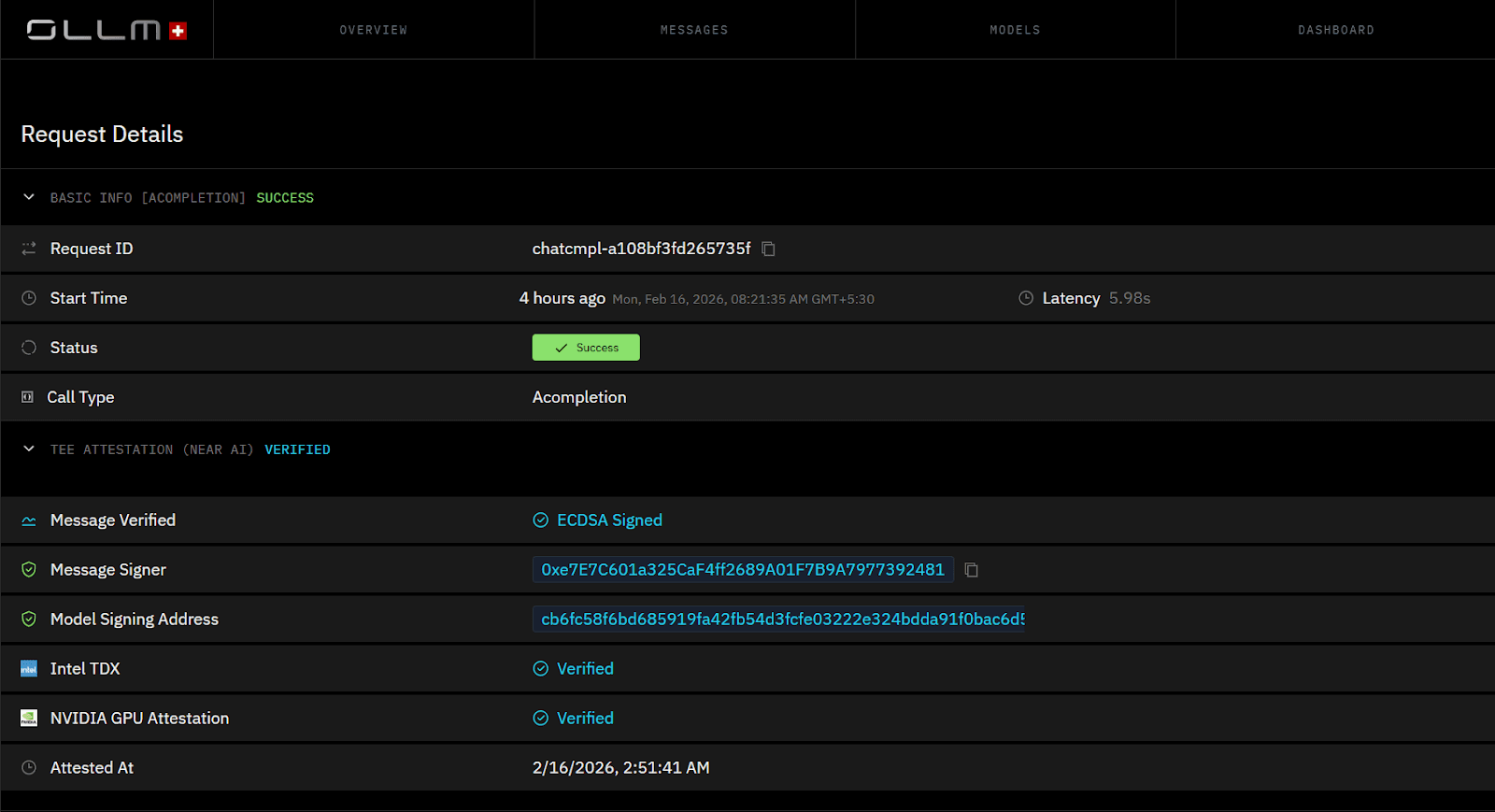
Confidential compute enforces runtime isolation. OLLM leverages hardware-backed Trusted Execution Environments with Intel TDX and NVIDIA GPU attestation. These mechanisms generate cryptographic proofs that verify that workloads execute within secure enclaves. Attestation verifies that:
The execution environment remains untampered
Prompt data is protected within the enclave memory
External processes cannot access runtime data
Encryption at every layer protects model traffic in transit and during processing inside secure environments.
Enterprise-Scale Model Aggregation Through One Secure API
Model aggregation simplifies enterprise AI infrastructure. OLLM provides a single, secure API for accessing multiple models from high-security providers. Engineering teams avoid managing multiple SDKs and authentication systems. Security teams enforce uniform governance controls across all model traffic.
Centralized routing enables dynamic provider selection. Enterprises can optimize for latency, geography, compliance requirements, or cost without modifying application code.
Practical and Predictable Scaling for Production Workloads
Scaling remains operationally straightforward. Teams can increase throughput by loading additional credits. For sustained or high-volume workloads, dedicated capacity can be reserved through commercial agreements. Centralized throttling and routing eliminate fragmented rate-limit management across providers and support predictable production performance.
Key Advantages
World’s first enterprise AI gateway aggregating confidential compute providers
Zero data retention architecture
Intel TDX and NVIDIA GPU TEE cryptographic attestation
Encryption at every layer
Multiple models accessible via one secure API
Centralized governance and scalable capacity controls
OLLМ operates as a confidential compute AI control plane for enterprises that require verifiable privacy, cryptographic execution guarantees, and production-grade scalability.
2. Portkey: Centralized Observability and Governance for Multi-Model AI Systems
Portkey positions itself as an AI gateway focused on observability, reliability, and governance. It sits between applications and model providers, providing a unified layer for routing, logging, and enforcing usage policies. Instead of building custom monitoring and rate-limiting logic for each provider, teams centralize model traffic through Portkey’s control plane.
Governance and Policy Enforcement Controls
Policy enforcement is a core strength of Portkey’s architecture. Teams can define usage limits, access rules, and routing policies across models from a single interface. Rate limiting, request validation, and fallback routing reduce runtime instability when providers experience latency or quota issues.
Centralized governance helps standardize model usage across teams. Instead of relying on application-level safeguards, controls are enforced at the gateway layer. This approach improves consistency across environments and reduces configuration drift.
Observability and Monitoring Capabilities
Observability defines Portkey’s operational value. The platform provides detailed logs, analytics dashboards, latency tracking, and request tracing across multiple model providers. Engineering teams gain visibility into performance bottlenecks, token consumption, and error rates without switching between vendor dashboards.
Centralized telemetry also simplifies incident response. When a model request fails or degrades, teams can trace the request path through a single interface rather than correlate logs across separate systems.
Multi-Provider Routing and Reliability
Multi-model routing allows dynamic provider selection. Portkey can distribute traffic across providers, implement fallback logic, and optimize for cost or performance. This flexibility reduces dependence on a single vendor and improves application resilience.
Key Strengths
Unified observability across model providers
Centralized rate limiting and policy controls
Multi-provider routing with fallback support
Usage analytics and cost visibility
Simplified operational management for AI workloads
Portkey fits organizations that prioritize monitoring, governance, and operational visibility across growing multi-model AI deployments.
3. OpenRouter: Unified Model Access for Flexible AI Experimentation
OpenRouter focuses on model aggregation and developer flexibility. It provides a single API to access multiple large language models across providers. Instead of managing separate credentials and SDKs, teams integrate once to access a broad model catalog. This structure simplifies experimentation and rapid iteration across model variants.
Broad Model Marketplace Through One API
Model diversity defines OpenRouter’s value proposition. Developers can switch between models with minimal integration changes. This flexibility enables comparative testing across providers without rewriting application logic. When cost, latency, or quality requirements shift, routing adjustments happen at the API level rather than at the application layer.
A unified endpoint also reduces integration friction during early-stage AI development. Teams can quickly prototype features while retaining the option to switch providers later.
Cost and Performance Optimization Flexibility
Dynamic model selection supports cost-performance tradeoffs. Teams can route traffic to lower-cost models for non-critical workloads and reserve higher-performance models for latency-sensitive tasks. This approach helps manage token consumption and usage-based billing across providers.
OpenRouter’s abstraction layer enables traffic distribution strategies without embedding deep vendor-specific logic in application code.
Key Strengths
Single API for multiple model providers
Flexible model switching without code rewrites
Rapid experimentation across LLM variants
Cost and performance optimization through routing
Reduced SDK and credential management overhead
OpenRouter suits teams prioritizing flexibility and speed in multi-model environments. Its aggregation-first design supports experimentation-heavy workflows and dynamic provider selection.
4. Azure AI Gateway: Enterprise AI Routing Within the Microsoft Ecosystem
Azure AI Gateway integrates model access directly into the broader Microsoft cloud stack. Organizations already operating inside Azure can route AI workloads through native identity, networking, and policy controls. This alignment simplifies governance for enterprises standardized on Microsoft infrastructure.
Native Integration with Azure Identity and Security Controls
Azure integration provides centralized identity enforcement through Azure Active Directory. Role-based access control, network segmentation, and private endpoints extend existing cloud governance policies to AI workloads. Instead of introducing a separate security layer, enterprises apply familiar Azure controls to model traffic.
This approach reduces friction during integration in Microsoft-centric environments. Security teams manage AI access through established Azure workflows rather than adopting a new governance stack.
Compliance and Enterprise Policy Alignment
Azure infrastructure supports enterprise compliance programs through standardized certifications and audit tooling. AI gateway capabilities operate within this broader compliance framework. Logging, monitoring, and policy enforcement integrate with Azure-native services, including monitoring and security analytics tools.
Organizations subject to strict data residency or regulatory requirements can leverage Azure’s regional deployment options to align AI workloads with geographic constraints.
Key Strengths
Deep integration with Azure identity and networking
Enterprise-grade RBAC and policy enforcement
Regional deployment controls for data residency
Native monitoring and logging within the Azure Stack
Simplified governance for Microsoft-first enterprises
Azure AI Gateway fits organizations that prioritize ecosystem alignment and centralized cloud governance over multi-cloud abstraction.
5. AWS Bedrock Guardrails and Routing Controls for Cloud-Native AI
AWS Bedrock extends access to AI models within the AWS cloud ecosystem. Organizations building on AWS can integrate foundation models through native IAM policies, networking controls, and regional infrastructure. This integration allows AI workloads to operate within existing AWS security and compliance boundaries.
Native IAM Enforcement and Network Isolation
IAM policies define access control for Bedrock-based workloads. Teams can restrict model usage by role, service, or account. VPC integration enables private networking configurations, which prevent public exposure of model traffic. These controls align AI deployments with established AWS security architectures.
Network isolation and IAM enforcement reduce the need for separate identity systems. AI traffic follows the same governance model as other AWS services.
Guardrails and Managed Model Access
Bedrock includes guardrail capabilities to help manage output moderation and usage controls. Enterprises can configure content filtering policies and apply standardized controls across workloads. Managed model access simplifies provisioning compared to direct third-party integrations.
Regional availability supports data residency requirements. Organizations can deploy AI workloads in specific AWS regions to align with jurisdictional constraints.
Key Strengths
Deep integration with AWS IAM and VPC controls
Regional deployment options for compliance alignment
Built-in guardrails for output governance
Managed model access within the AWS ecosystem
Simplified scaling through AWS quota management
AWS Bedrock suits organizations committed to AWS-native infrastructure that want to govern AI workloads with familiar cloud security controls.
How to Choose the Right AI Gateway for Your Enterprise Deployment Strategy
AI gateway selection depends on security depth, compliance requirements, and alignment with infrastructure. Not every organization faces the same constraints. Some prioritize cryptographic guarantees and zero data exposure, while others prioritize observability, alignment with the cloud ecosystem, or rapid experimentation. The right choice reflects deployment risk, regulatory posture, and operational maturity.
Security-first environments require verifiable privacy guarantees. Organizations handling financial records, healthcare data, or confidential enterprise knowledge benefit from zero data retention and hardware-backed TEE attestation. Cryptographic execution proofs materially strengthen audit defensibility in regulated industries.
Cloud-aligned enterprises may prioritize ecosystem integration. Azure-native or AWS-native organizations often prefer gateways embedded within their existing IAM, networking, and compliance frameworks. This approach reduces integration overhead and simplifies policy enforcement.
Experimentation-driven teams value flexibility and model diversity. Unified APIs that enable rapid switching across models support cost optimization and iterative development workflows.
The decision can be summarized as follows:
Maximum privacy and cryptographic verification: OLLM
Centralized observability and governance controls: Portkey
Flexible multi-model experimentation: OpenRouter
Microsoft ecosystem alignment: Azure AI Gateway
AWS-native governance and scaling: AWS Bedrock
AI gateways are becoming foundational infrastructure. As AI systems move deeper into production, security architecture, execution verification, and centralized control increasingly define competitive advantage.
How Enterprise AI Gateways Reduce Compliance and Data Exposure Risk
AI adoption is accelerating across regulated and data-sensitive industries. Customer support automation, internal copilots, document processing, and analytics pipelines increasingly rely on large language models. As these systems move into production, infrastructure choices begin to influence compliance exposure, operational resilience, and customer trust.
AI gateways reduce fragmentation while strengthening control. Instead of managing isolated integrations across multiple providers, enterprises consolidate model access behind a centralized enforcement layer. Encryption standards, policy rules, rate limits, and audit logging become uniform. Governance shifts from application-level safeguards to infrastructure-level guarantees.
Security architecture now differentiates enterprise AI platforms. Zero data retention eliminates the risk of stored prompts. Hardware-backed TEE attestation introduces cryptographic verification of execution environments. Centralized routing simplifies scaling and provider management. When these capabilities operate together, AI deployments become measurable, defensible, and scalable.
Enterprise AI is no longer an experimental feature set. It is core infrastructure. Organizations that treat AI gateways as strategic security layers position themselves to scale responsibly while maintaining verifiable privacy and operational control.
Security and Compliance Capabilities Compared Side by Side
Enterprise teams often evaluate AI gateways across a small set of critical security and operational criteria. Architectural differences become clearer when viewed comparatively. The table below summarizes how these platforms align across privacy, execution verification, aggregation depth, and scaling controls.
Gateway | Zero Data Retention | TEE Attestation | Model Aggregation | Enterprise Encryption | Scaling Controls |
OLLM | Yes | Yes (Intel TDX + NVIDIA GPU) | Multi-provider | Encryption at every layer | Credits + Reserved capacity |
Portkey | Limited / Logging-based | No | Multi-provider | Standard TLS | Rate limiting + routing |
OpenRouter | No | No | Multi-provider marketplace | Standard TLS | Usage-based scaling |
Azure AI Gateway | Cloud-dependent | Cloud/security-stack dependent (varies by service/config) | Limited to Azure-supported models | Azure security stack | Azure quota controls |
AWS Bedrock | No | Cloud/security-stack dependent (varies by service/config) | AWS-supported models | AWS security stack | AWS quota controls |
Architectural depth varies significantly across providers. Some platforms focus on observability and routing flexibility. Others integrate tightly within specific cloud ecosystems. OLLM distinguishes itself through zero data retention, hardware-backed TEE cryptographic attestation, and verifiable execution guarantees.
Conclusion: Enterprise AI Security Now Depends on Gateway Architecture
AI gateways now determine how securely and reliably enterprises deploy large language models. Direct integrations create fragmentation, inconsistent policy enforcement, and expanded data risk. Centralized gateways standardize encryption, routing, observability, and compliance controls. Platforms differ in depth, but architectures that combine zero data retention, hardware-backed TEE attestation, and unified model aggregation provide stronger verifiable guarantees for production-grade AI systems.
Enterprise teams evaluating AI infrastructure should prioritize execution verification, data non-retention policies, and scalable routing controls before expanding AI workloads further. A structured gateway assessment, focused on privacy guarantees, cryptographic attestation, and operational scalability, clarifies whether the current architecture can support regulated, high-volume deployment. Secure AI scaling begins with choosing the right control plane.
FAQ
1. What is an AI gateway and how does it improve enterprise AI security?
An AI gateway is an infrastructure layer that sits between enterprise applications and large language model providers. It centralizes routing, encryption, policy enforcement, audit logging, and rate limiting. Instead of integrating multiple LLM APIs directly, organizations use a single control plane to standardize governance. Enterprise AI gateways reduce vendor sprawl, minimize compliance gaps, and enforce consistent data protection controls across all model traffic.
2. How does zero data retention in OLLM reduce enterprise AI compliance risk?
Zero data retention in OLLM means prompts and responses are never stored in a persistent database. Once a request completes, no retrievable record remains within the gateway infrastructure. This architecture eliminates the need for stored prompt repositories, reduces exposure to breaches, and limits regulatory liability related to data residency, subpoena access, or unauthorized database extraction. For regulated industries, non-retention materially strengthens privacy posture.
3. What is TEE cryptographic attestation and how does OLLM use Intel TDX and NVIDIA GPU attestation?
TEE (Trusted Execution Environment) cryptographic attestation generates hardware-backed proofs that verify that workloads execute within isolated, secure enclaves. OLLM supports Intel TDX and NVIDIA GPU attestation to verify that model requests run in untampered environments. Attestation proofs confirm enclave integrity, prevent external memory access, and provide verifiable evidence for audits. This moves enterprise AI security from policy claims to cryptographic verification.
4. How do AI gateways help prevent vendor lock-in in multi-model LLM deployments?
AI gateways abstract provider-specific APIs behind a unified interface. This abstraction enables dynamic model routing across multiple LLM vendors without modifying application logic. Enterprises can switch providers based on latency, cost, or regulatory requirements. Multi-model aggregation reduces long-term dependence on a single provider and simplifies cross-provider performance optimization.
5. How do enterprise AI gateways handle scaling, rate limits, and high-volume workloads?
Enterprise AI gateways centralize rate limiting, traffic shaping, and quota management across providers. Instead of managing individual vendor limits separately, scaling occurs through a unified control layer. Some platforms support credit-based throughput expansion or reserved capacity agreements to guarantee predictable performance. Centralized scaling controls improve reliability during traffic spikes and sustained high-volume AI inference workloads.
"/><stop offset="1" stop-color="rgb(80, 78, 87)"/></linearGradient></defs><g d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z M 142.346 0.381 L 162 0.381 L 162 20 L 142.346 20 Z M 153.986 8.381 L 158.375 8.381 L 158.375 12 L 153.986 12 L 153.986 16.571 L 150.36 16.571 L 150.36 12 L 145.972 12 L 145.972 8.381 L 150.36 8.381 L 150.36 4.19 L 153.986 4.19 Z" fill="transparent" height="20px" id="cWM2PbaAz" width="162.00000833847133px"><path d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z" fill="url(%23UyELkL66Q-1582027827-linear-gradient)" height="20px" id="UyELkL66Q" width="134.52277004415487px"/><path d="M 0 0 L 19.654 0 L 19.654 19.619 L 0 19.619 Z" fill="rgb(176, 0, 0)" height="19.618991595424752px" id="t30DbKa7C" transform="translate(142.346 0.381)" width="19.653710120697895px"/><path d="M 8.014 4.19 L 12.403 4.19 L 12.403 7.81 L 8.014 7.81 L 8.014 12.381 L 4.389 12.381 L 4.389 7.81 L 0 7.81 L 0 4.19 L 4.389 4.19 L 4.389 0 L 8.014 0 Z" fill="rgb(255, 255, 255)" height="12.380917026238919px" id="bLcZkJmGc" transform="translate(145.972 4.19)" width="12.402826775197639px"/></g></svg>)