|

TLDR
Multiple LLM providers multiply complexity. Each integration introduces different SDK behaviors, rate limits, billing models, dashboards, and compliance standards.
Model selection logic quietly becomes infrastructure. Cost-based switching and rate-limit handling spread across services unless centralized at the execution layer.
Billing and observability fragments across vendors. Separate dashboards, quota systems, and invoices make cost control and forecasting harder.
Compliance and data retention diverge between providers. Zero-retention policies, logging defaults, and isolation guarantees vary, increasing audit surface and governance risk.
OLLM centralizes execution through one API. Quota enforcement, billing visibility, and fixed zero-retention controls are enforced from a single gateway. Prompt and response content is never stored; only minimal, fixed data is retained: user email, user-agent, token usage, and TEE attestation records, including Intel quotes. For supported providers and models, TEE-backed execution is available when that model is selected, with Intel TDX and NVIDIA GPU attestation surfaced as verification evidence.
Enterprise AI systems no longer run on a single model. Production stacks combine multiple LLM providers to balance reasoning quality, latency, cost efficiency, regional constraints, and uptime guarantees. What begins as one integration often expands into several, each with its own API keys, billing accounts, dashboards, and execution rules. Multi-provider architecture is quickly becoming the norm in large AI deployments.
This write-up examines what managing multiple LLM APIs actually involves in production. It explains how SDK differences complicate codebases, how billing and observability fragment across dashboards, how compliance and retention standards diverge, and how model selection and scaling logic become infrastructure concerns. It then outlines how OLLM, a centralized AI gateway, can consolidate these layers without reducing model flexibility.
What Is an LLM API?
An LLM API (Large Language Model Application Programming Interface) is the interface an application uses to send prompts to a hosted language model and receive generated outputs. Instead of running model infrastructure internally, teams call a remote endpoint to perform inference and return structured responses.
To make this concrete, consider an AI-powered customer support platform.
The chat assistant sends user messages to an LLM API to generate responses.
A background summarization service calls another LLM API to summarize ticket threads.
A classification pipeline uses embeddings from a third LLM API to route tickets to the correct department.
Each of those features integrates with an LLM API through a backend service. The application does not host the model itself. It sends structured input and receives structured output over HTTP or an SDK.
Applications typically integrate LLM APIs into:
Backend services that handle request/response workflows
Customer-facing assistants
Internal automation tools
Search and retrieval systems
Data processing pipelines
Developer tools
At a minimum, an LLM API exposes:
A model identifier
An authenticated endpoint
A request schema (messages, inputs, parameters)
A response structure (tokens, completions, metadata)
Behind that endpoint sits a distributed inference system managing GPU allocation, scaling, rate limits, and logging. From the application’s perspective, it appears to be a simple API call. In practice, it is a remote execution environment operated by a provider.
When and Why Teams Integrate Multiple LLM APIs
A single LLM provider is often sufficient during early experimentation. The architecture becomes more complex when real production workloads introduce competing requirements.
Consider a SaaS helpdesk platform powered by AI.
The chat assistant needs high-quality reasoning for complex customer issues.
The ticket summarization pipeline must process thousands of conversations per hour at low cost.
The search layer relies on embeddings for semantic retrieval.
Enterprise customers in the EU require region-specific inference.
Financial-sector clients demand hardware-backed isolation and attestation.
At this point, a single LLM provider may not satisfy every constraint simultaneously. The team begins integrating multiple LLM APIs to address specific operational needs.
In practice, that often looks like:
Provider A handles high-accuracy reasoning for premium workflows.
Provider B processes high-volume summarization traffic at a lower cost.
Provider C supplies embeddings for search.
A provider that supports TEE-backed inference is used for regulated workloads.
Each addition solves a real problem. However, every new integration introduces another execution environment, quota model, billing system, and retention policy.
Once multiple providers coexist in the same system, the architecture changes. The application is no longer issuing requests to a single inference environment. It is coordinating across independent infrastructures with different rate limits, dashboards, retention defaults, and compliance guarantees.
That shift is where hidden complexity begins
What Happens When You Integrate Multiple LLM APIs
Multiple LLM APIs typically integrate into a system when different production constraints cannot be met by a single provider. For example, a SaaS platform may use one model for high-accuracy reasoning in customer-facing chat, another for low-cost bulk summarization in background jobs, and a third for embeddings powering semantic search. In that scenario, the backend is no longer interacting with a single inference endpoint. It is coordinating across multiple provider environments.
Managing multiple LLM APIs means operating several independent execution systems at once. Each provider introduces its own authentication scheme, SDK conventions, rate limits, error taxonomy, logging defaults, and pricing model. These differences surface directly inside backend services and worker processes that call the APIs.
In practice, that divergence often appears inside application service code.
For example, a request handler in a backend service might call one provider for interactive chat responses:
|
Meanwhile, a background summarization worker may integrate with a different provider optimized for batch processing:
|
These calls live in different services, use different SDKs, and rely on different authentication and quota systems.
The divergence extends beyond syntax. Streaming behavior may differ between providers. Retry and backoff logic may rely on different error structures. Timeout thresholds may not align. Rate-limit headers may expose different reset semantics. SDK release cycles may introduce breaking changes at different times. The result is inconsistent behavior across services that must be manually normalized.
To manage this inconsistency across authentication flows, retry semantics, quota enforcement, and response handling, teams often build internal abstraction layers. These wrappers translate provider-specific responses into a common format and centralize retry logic. Over time, the abstraction layer accumulates conditionals for edge cases, provider-specific exceptions, and compatibility patches. Maintaining that normalization layer becomes a separate engineering responsibility.
The complexity does not remain confined to code.
Multi-provider systems also introduce organizational fragmentation:
Separate billing accounts and pricing tiers
Independent usage dashboards and quota tracking
Different data retention defaults and logging controls
Separate compliance documentation and regional guarantees
Engineering monitors usage in one console. Finance reconciles invoices across vendors. Security reviews distinct data processing agreements. Compliance compares isolation guarantees between providers.
The decision to adopt multiple LLM APIs is usually rational. Capability diversity, resilience, cost control, and regulatory alignment all justify expansion. The complexity described earlier does not appear immediately. It forms gradually as additional providers are layered into the system.
How Multi-Provider Architectures Expand Incrementally Over Time
Multi-provider architectures rarely begin as multi-provider systems. They evolve from a simple starting point. A team typically launches with a single LLM integration that powers one core workflow. The architecture is clean: one API key, one SDK, one billing account, and one dashboard to track usage and costs.
Over time, new requirements emerge. Rather than replacing the existing provider, teams add another. Then another. The system expands in response to concrete operational needs.

Expansion happens gradually, and it almost always follows a recognizable progression:
Phase 1 – Single provider integration: One model handles the majority of inference traffic.
Phase 2 – Fallback provider introduced: A second provider protects against outages or quota exhaustion.
Phase 3 – Cost or latency-based model selection added: Teams explicitly select models based on pricing tiers or performance requirements.
Phase 4 – Compliance-sensitive workloads isolated: Certain requests use providers that meet stricter data or regional requirements.
Phase 5 – Cross-team experimentation: Different teams integrate additional models for specialized workloads.
Each phase improves capability. Redundancy increases uptime. Better model selection improves performance and helps control costs. Segmentation supports governance. None of these decisions is a mistake. The complexity emerges from accumulation.
By Phase 3 or 4, the system no longer performs a simple API call. It makes conditional decisions. It checks rate limits. It evaluates provider health. It enforces model selection rules. A once-simple call evolves into layered selection logic:
|
That logic often spreads while another optimizes cost. A third isolates regulated workloads. Meanwhile, billing data now lives in multiple dashboards. Rate-limit monitoring spans multiple consoles. Compliance reviews compare different provider guarantees.
At this point, the application is no longer making a simple model invocation. It is coordinating execution across multiple provider environments, each with its own availability signals, quota limits, and operational constraints. Without deliberate abstraction, this coordination becomes embedded across services, background workers, and internal tooling. What began as flexibility gradually turns into structural complexity that is difficult to centralize later.
How Multi-Provider LLM Integrations Become Hard to Manage
Operational fragmentation appears when provider-specific behavior spreads across services. Every new LLM integration introduces slight differences in authentication, request shape, error handling, streaming, and rate-limit semantics. In isolation, each difference is small. In aggregate, they form an execution surface that is difficult to standardize, test, and audit.
Over time, multi-provider systems typically fragment across two dimensions: execution behavior and data handling.
Execution Fragmentation Across Providers
Execution fragmentation occurs when model selection logic, retry handling, and quota management behave differently across providers. Each API exposes its own conventions. Some return structured error codes. Others return generic HTTP failures. Some expose rate-limit headers clearly. Others require parsing response metadata.
Applications must either normalize these behaviors or branch explicitly:
|
This branching logic spreads quickly. Authentication mechanisms differ. Key rotation policies differ. Model identifiers follow different naming conventions. SDKs introduce breaking changes at different times. Even version upgrades require provider-specific testing cycles.
Common execution divergences include:
Distinct authentication and key rotation models
Different rate-limit structures and reset logic
Inconsistent error taxonomies
Provider-specific model versioning schemes
As cost-aware model selection and latency-based decisions are introduced, this complexity increases. One service implements fallback logic. Another manages rate-limit mitigation. A third handles compliance-sensitive traffic. Without central coordination, model selection becomes a distributed infrastructure embedded across the codebase.
Data Handling and Logging Fragmentation Across Providers
Data fragmentation poses a greater risk than execution divergence. Each provider applies its own retention defaults, telemetry structure, and audit controls. When integrated directly, applications inherit those differences.
This divergence creates several structural gaps:
Inconsistent prompt and response retention policies
Separate audit trails across provider dashboards
Ambiguity between content logs and usage metadata
Multiple API keys stored across environments
In enterprise environments, the distinction between content and metadata is critical. In OLLM, zero retention means prompt and response content is never stored; this is a fixed infrastructure property, not a configurable default. What is stored is minimal and fixed: user email, user-agent, token usage, and TEE attestation records. There is no opt-in, opt-out, or logging toggle.
When prompt and response content are stored across multiple provider paths, the system effectively creates distributed prompt databases. Each provider dashboard becomes a potential retrieval surface. Each integration increases the attack surface that security and compliance teams must review.
At this point, architectural flexibility begins to conflict with governance clarity. Fragmentation at the data layer transforms multi-provider freedom into data management complexity.
How Compliance Requirements and Verifiable Execution Impact Multi-LLM Architectures
Compliance pressure changes the nature of the problem. When systems process financial records, healthcare data, proprietary models, or regulated customer inputs, execution guarantees must move beyond contractual assurances. Data isolation and execution integrity must be demonstrable, not implied.
In multi-provider environments, each vendor publishes its own compliance documentation, isolation claims, and regional hosting guarantees. Security teams review multiple SOC reports. Legal teams compare data processing agreements. Engineering teams implement provider-specific model selection rules for regulated workloads. Without central coordination, compliance logic spreads across services just like model selection logic did earlier.
The dashboard below shows inference requests with associated verification and attestation status surfaced at the gateway layer:
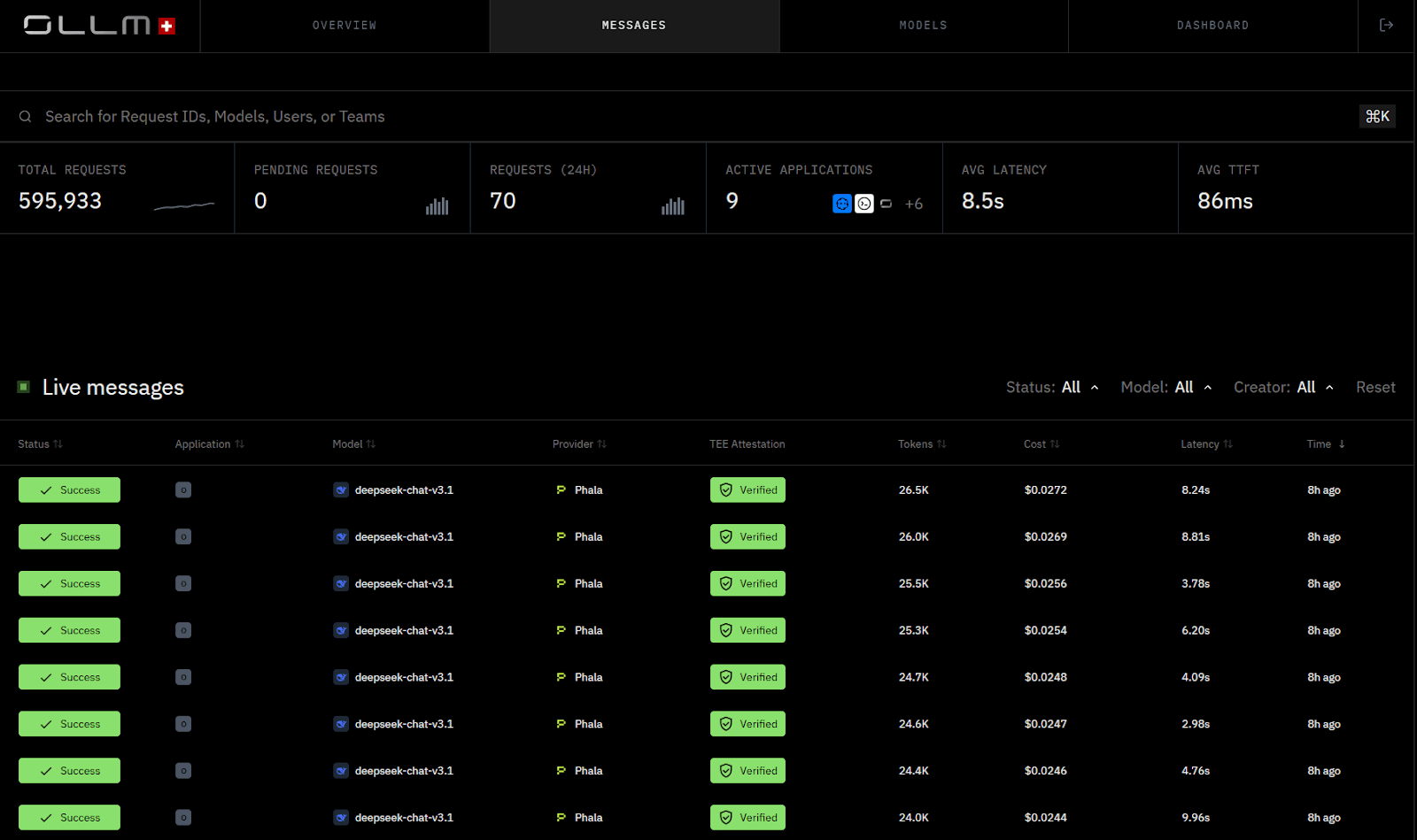
Trusted Execution Environments (TEEs) address the isolation requirement at the hardware layer. When a TEE-enabled model is selected, the request executes inside a hardware-isolated environment rather than a standard shared runtime. OLLM supports TEE-backed execution for supported providers/models (for example, Phala/NEAR paths), where inference runs in hardware-isolated environments.
Confidential infrastructure is increasingly expected in regulated environments. OLLM integrates Intel TDX-based confidential-VM isolation and NVIDIA GPU attestation (where supported), and can surface attestation results in a standardized format.
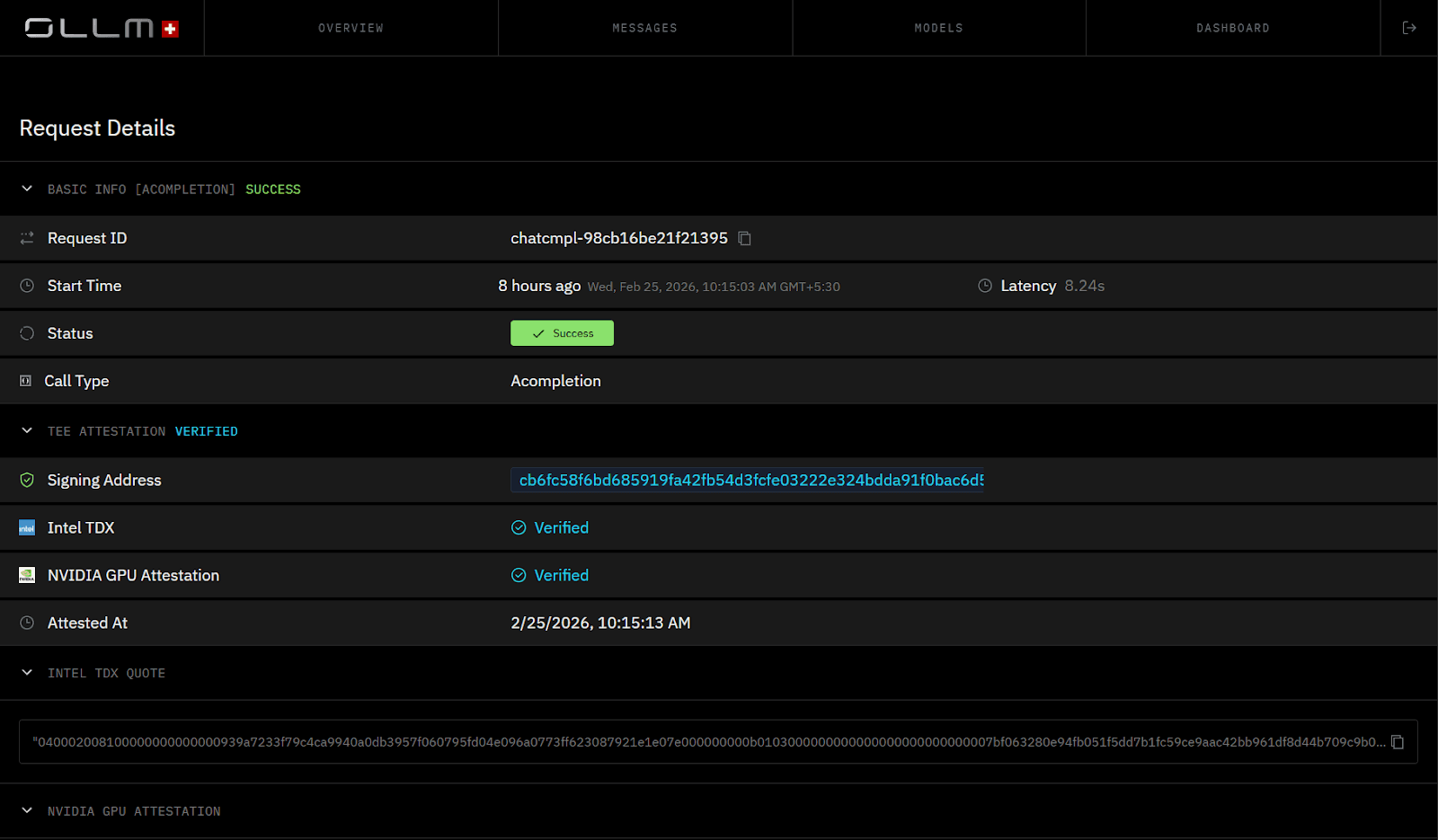
TEE-backed execution can enable cryptographic attestation. Depending on the stack, technologies such as Intel TDX (for the confidential VM) and NVIDIA GPU attestation (for the GPU/device state) can generate evidence about the execution environment, including :
The identity and integrity of the confidential VM/workload measurement (per the attestation policy)
That the workload ran in a TEE-backed environment consistent with the policy
That the host can’t directly read guest memory (within the TEE threat model)
Optionally, device/GPU claims when GPU attestation is available
These attestation artifacts enable systems to validate that inference occurred within a hardware-isolated environment. This model can replace purely trust-based isolation claims with cryptographically verifiable evidence about the execution environment. Hardware-backed isolation reduces the risk of certain co-tenant and host-access threats on shared infrastructure (within the TEE threat model).
In fragmented multi-provider architectures, compliance-sensitive workloads often require conditional routing logic embedded in application code. One path handles standard traffic. Another handles regulated traffic. Audit artifacts remain distributed across vendors. Centralizing execution through a gateway consolidates this decision layer. When a TEE-backed model is selected, it executes inside a secure environment and exposes attestation proofs as part of the verification chain.
Compliance then becomes an enforceable architectural control rather than a collection of policy documents spread across providers.
How Does Multi-LLM Routing Become a Maintenance Problem?
Routing decisions usually live inside backend services that directly call LLM providers. For example, a customer-facing chat service may decide which reasoning model to use, while a background document processor may choose a lower-cost model. In many systems, this selection logic is embedded directly inside application code.
For instance, a backend service might include logic like:
|
This type of routing logic is typically found inside API handlers, orchestration services, or worker processes responsible for inference calls. It determines which provider and model will execute a given request.
At first, embedding these decisions locally seems efficient. The service owns its workload and selects the model it needs. The issue emerges as additional constraints are introduced. Cost-based switching is added to one service. Latency-aware routing appears in another. Rate-limit mitigation logic is implemented separately by a third party. Compliance-sensitive traffic introduces additional branching rules.
The result is not incorrect behavior; it is fragmented behavior.
Each service now implements its own routing logic. Cost policies differ slightly between teams. Fallback conditions are inconsistent. Updating a global execution rule requires modifying code in multiple repositories.
When routing logic is distributed this way, the infrastructure responsibility of deciding how inference is executed becomes embedded across the application layer.
In OLLM, model selection is always explicit at the application layer: the application directly specifies the model alias. The gateway does not perform dynamic routing, load balancing, or model fallback. What centralizing execution through a gateway solves is removing provider-specific quota management, authentication, and observability logic from application code
Without centralization of execution policy, routing behavior becomes duplicated infrastructure scattered across services.
Centralization in this context refers specifically to centralizing:
Model-to-deployment mapping
Fallback rules
Rate-limit handling
Cost ceilings
Load balancing across deployments
When these controls are enforced at a single execution layer rather than within application services, routing becomes a configurable policy rather than embedded logic.
That shift reduces maintenance overhead and makes execution behavior auditable and consistent across the stack.
Model selection determines which provider executes a request. Scaling determines whether those requests can be sustained under load. Once multiple providers are involved, capacity management becomes as complex as model selection logic itself.
How Multi-Provider LLM Scaling Creates Billing and Capacity Chaos
Scaling across multiple LLM providers is not the same as scaling a single API. Each vendor enforces its own rate limits, quota resets, pricing tiers, billing dashboards, and capacity allocation rules. During traffic spikes, these differences surface immediately.
The screenshot below illustrates cross-provider usage and quota signals surfacing independently, a common scenario when scaling without centralized capacity control.
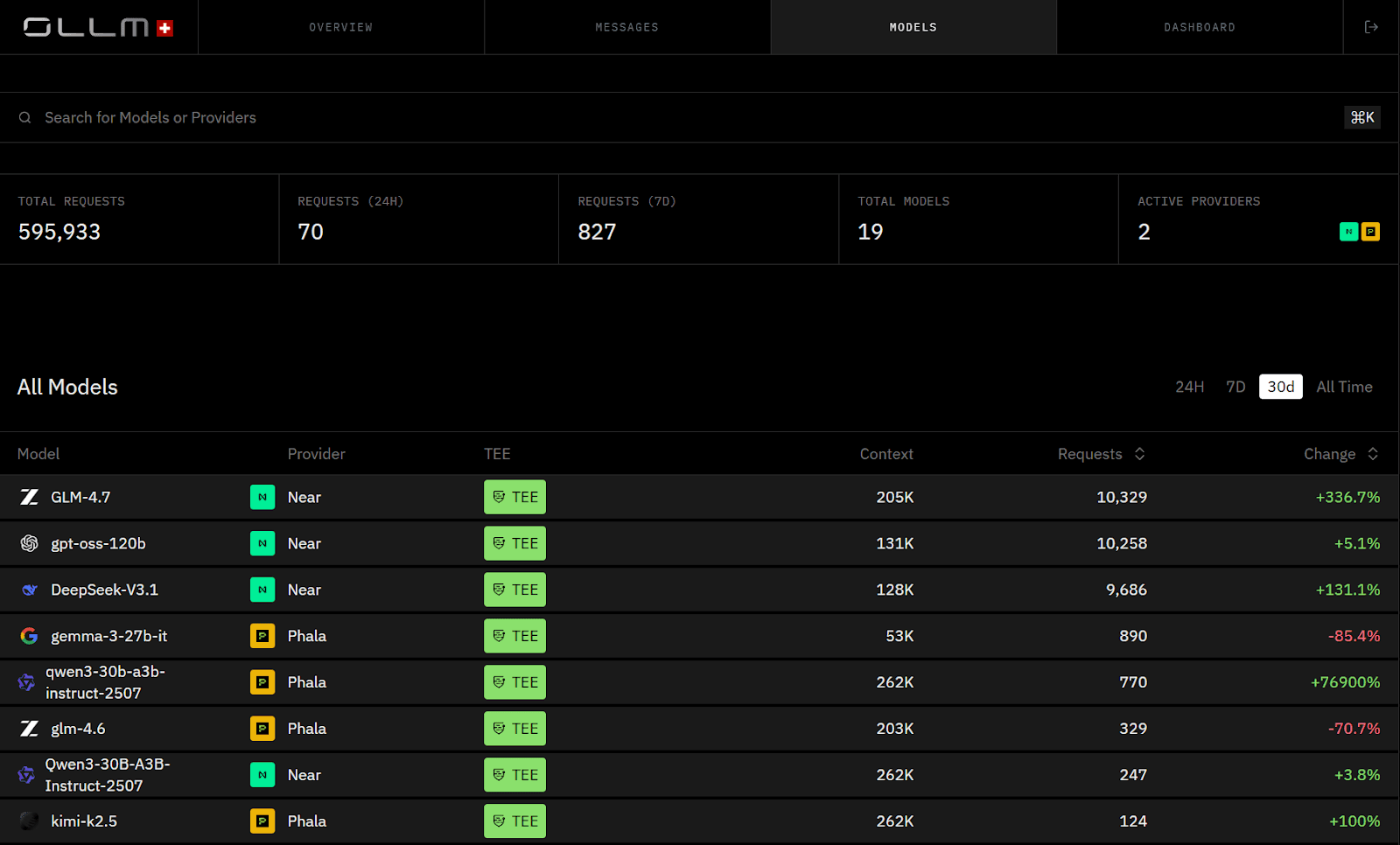
One provider may throttle at 60 requests per second. Another may reset the quota hourly. A third may require manual approval to raise capacity. Without centralized visibility, applications hit rate ceilings unevenly. Failover traffic shifts unexpectedly. Costs spike when routing defaults to higher-priced models.
Typical scaling friction points include:
Primary provider hitting rate limits during peak traffic
Fallback paths absorbing traffic without cost guardrails
Separate billing dashboards are obscuring real-time spend
Manual coordination is required to reserve additional capacity
No unified view of cross-provider quota utilization
Even financial operations become fragmented. Engineering monitors rate limits in one console. Finance reconciles invoices across multiple vendors. Forecasting requires aggregating usage reports from separate dashboards.
In practice, scaling often requires provider-specific adjustments. Teams load additional credits for prepaid accounts. They contact sales to reserve capacity ahead of product launches. They manually adjust routing logic to reduce pressure on constrained providers. These steps work, but they do not scale cleanly across multiple vendors.
Centralizing quota enforcement at the gateway changes the scaling model. Instead of embedding quota checks inside application code, capacity rules are enforced at the execution layer. Cost ceilings constrain behavior before it reaches providers. Teams can contact sales to reserve capacity ahead of demand spikes without modifying business logic. Predictable scaling depends on separating application behavior from provider mechanics, without that separation, each traffic spike becomes a multi-vendor coordination event
How OLLM Centralizes Multi-LLM Routing, Billing, and Verifiable Execution
OLLM replaces fragmented multi-provider integrations with a single enterprise-grade execution layer. Instead of wiring each LLM vendor directly into your application, you integrate with OLLM once and access many models through a unified API. Quota enforcement, billing visibility, and isolation policies are enforced centrally.
Without a gateway, applications embed provider-specific model selection and quota logic directly in code. With OLLM, the integration remains stable while the execution policy stays centralized.
Using the OpenAI-compatible SDK:
|
Or directly via HTTP:
|
The application calls one endpoint. OLLM handles the rest.
Model selection is explicit at the application layer — the application specifies the model alias directly, for example, near/GLM-4.6. OLLM does not perform dynamic routing, load balancing, or model fallback. The gateway handles quota enforcement and TEE-backed execution for the selected model when that execution path is available
Operational fragmentation also collapses. Instead of juggling multiple billing dashboards, quota systems, and provider consoles, usage flows through one interface. Scaling happens at the gateway layer through centralized quota enforcement across approved deployments.
Security and compliance consolidate at the gateway layer. OLLM never stores prompt or response content; this is a fixed infrastructure property, not a configurable default. What is stored is minimal and fixed: user email via Privy, user-agent data, token usage, and TEE attestation records, including Intel quotes. There is no opt-in, opt-out, or logging toggle.
For regulated workloads, OLLM supports TEE-backed execution paths for supported providers and models. When a TEE-enabled model is selected, the request executes inside a secure, hardware-isolated environment. Intel TDX and NVIDIA GPU attestation generate cryptographic proofs that verify enclave integrity and execution authenticity. Enterprises can validate attestation evidence as part of a trust policy, typically before provisioning secrets (and, in some designs, before sending sensitive prompts), and/or before accepting results. Attestation provides cryptographic evidence about the enclave or VM identity and integrity. It strengthens trust guarantees but does not independently prove end-to-end workflow security.
The architectural shift is structural:
Direct Multi-Provider Setup | OLLM AI Gateway |
Multiple SDK integrations | Single OpenAI-compatible API |
Model selection logic embedded in application code | Model selection explicit at application layer; gateway enforces quota and TEE execution |
Separate billing dashboards | Centralized observability and cost tracking behind a single API |
Divergent retention defaults across providers | Fixed zero storage of prompt/response content, user email, user-agent, token usage, and TEE attestation records only |
Trust-based isolation claims | Verifiable TEE-backed execution with attestation |
Provider-specific scaling workflows | Centralized quota management; reserved capacity available through sales |
In this reference architecture, model selection is always explicit at the application layer. The gateway handles quota enforcement and TEE-backed execution for the selected model; there are no configured routing groups or dynamic fallback paths.
OLLM does not reduce model diversity. It centralizes control. Quota enforcement, billing, compliance enforcement, fixed zero-retention, and TEE-backed execution operate from a single enforcement layer rather than being scattered across codebases and vendor consoles.
Conclusion: Centralizing Multi-LLM Infrastructure Without Sacrificing Flexibility
Multi-provider LLM adoption is rational. It improves resilience, capability coverage, cost optimization, and regulatory alignment. The complexity does not appear immediately. It accumulates across SDK differences, embedded model selection logic, fragmented billing dashboards, inconsistent retention policies, and provider-specific scaling workflows. Compliance requirements raise the bar further, requiring isolation to be cryptographically verified through TEE-backed execution and attestation rather than assumed through documentation.
OLLM consolidates these layers into a unified execution surface. One OpenAI-compatible API abstracts provider differences. Quota enforcement, scaling, billing visibility, fixed zero-retention, and TEE-backed execution operate from a single control plane. Hundreds of models remain accessible, but control becomes centralized. If your AI stack spans multiple LLM providers, the architectural question is no longer about model flexibility; it is about where execution policy, compliance guarantees, and operational control reside. Explore how OLLM's confidential AI gateway can consolidate quota enforcement, fixed zero-retention guarantees, TEE-backed execution paths, and attestation-backed validation into a single control plane.
FAQ
1. What are the main challenges of integrating multiple LLM APIs in a single application?
Integrating multiple LLM APIs introduces inconsistencies across SDK behavior, authentication schemes, rate-limits, error handling, streaming semantics, and model versioning. These differences lead to fragmented model selection logic, duplicated retry mechanisms, and provider-specific abstractions inside application code. Over time, billing dashboards, quota systems, and compliance policies also diverge, making cost control and governance harder to manage across vendors.
2. How do multiple LLM providers affect billing visibility and cost optimization?
Each LLM provider typically maintains its own pricing tiers, quota resets, and billing dashboard. This fragmentation makes real-time cost tracking and forecasting difficult. Cost management becomes complex when fallback traffic shifts to higher-priced models during rate-limit events. Without centralized usage aggregation, finance teams must reconcile invoices manually, and engineering teams lack unified visibility into spend across deployments.
3. Why is zero data retention important in multi-provider LLM architectures?
Zero data retention reduces the risk of creating distributed prompt databases across multiple provider dashboards. In OLLM, zero retention means prompt and response content is never stored; this is a fixed infrastructure property, not a configurable default. What is stored is minimal and fixed: user email, user-agent, token usage, and TEE attestation records. There is no configuration toggle. In multi-provider setups, inconsistent retention defaults increase audit surface and regulatory exposure, especially in healthcare, finance, or regulated AI deployments.
4. How does OLLM simplify multi-LLM routing and execution management?
OLLM provides an OpenAI-compatible API for supported endpoints. Applications integrate once, and reference model aliases explicitly; OLLM does not perform dynamic routing or fallback between models. What OLLM centralizes is quota enforcement, fixed zero-retention guarantees, TEE-backed execution for supported models, and billing visibility, removing provider-specific integration logic from application code.
5. How does OLLM support TEE-backed execution and cryptographic attestation?
When a TEE-enabled model is selected in OLLM, inference runs inside a hardware-isolated environment backed by Intel TDX and NVIDIA GPU attestation; there is no routing decision made by the gateway. Model selection is explicit at the application layer. Cryptographic attestation proofs verify enclave integrity and execution authenticity, enabling verifiable AI execution rather than relying solely on provider trust claims.
"/><stop offset="1" stop-color="rgb(80, 78, 87)"/></linearGradient></defs><g d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z M 142.346 0.381 L 162 0.381 L 162 20 L 142.346 20 Z M 153.986 8.381 L 158.375 8.381 L 158.375 12 L 153.986 12 L 153.986 16.571 L 150.36 16.571 L 150.36 12 L 145.972 12 L 145.972 8.381 L 150.36 8.381 L 150.36 4.19 L 153.986 4.19 Z" fill="transparent" height="20px" id="cWM2PbaAz" width="162.00000833847133px"><path d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z" fill="url(%23UyELkL66Q-1582027827-linear-gradient)" height="20px" id="UyELkL66Q" width="134.52277004415487px"/><path d="M 0 0 L 19.654 0 L 19.654 19.619 L 0 19.619 Z" fill="rgb(176, 0, 0)" height="19.618991595424752px" id="t30DbKa7C" transform="translate(142.346 0.381)" width="19.653710120697895px"/><path d="M 8.014 4.19 L 12.403 4.19 L 12.403 7.81 L 8.014 7.81 L 8.014 12.381 L 4.389 12.381 L 4.389 7.81 L 0 7.81 L 0 4.19 L 4.389 4.19 L 4.389 0 L 8.014 0 Z" fill="rgb(255, 255, 255)" height="12.380917026238919px" id="bLcZkJmGc" transform="translate(145.972 4.19)" width="12.402826775197639px"/></g></svg>)