|

TD;LR
Secure enclaves protect AI data while it is being processed. They use CPU-level isolation to keep prompts, context, and intermediate inference data inaccessible to operating systems, cloud infrastructure, and administrators, closing the long-standing gap around data-in-use security.
AI inference creates security risks that encryption alone cannot solve. Large language models require plaintext data in memory, which exposes sensitive enterprise information to memory inspection, logging, and privileged access in shared or managed environments.
Zero-knowledge AI becomes possible with hardware-backed isolation. Secure enclaves ensure that sensitive data is decrypted and processed only inside protected execution boundaries, with remote attestation enabling enterprises to verify that trusted code is running securely.
Software-only AI security breaks down at enterprise scale. Without hardware isolation, enterprises cannot reliably prevent runtime exposure, insider access, or audit gaps when deploying AI systems in production.
Ollm applies secure enclaves as the foundation of enterprise AI execution. By combining hardware-backed isolation, end-to-end encryption, and a single API for hundreds of LLMs, Ollm enables zero-knowledge AI inference without expanding trust boundaries as AI usage scales.
What are Secure Enclaves?
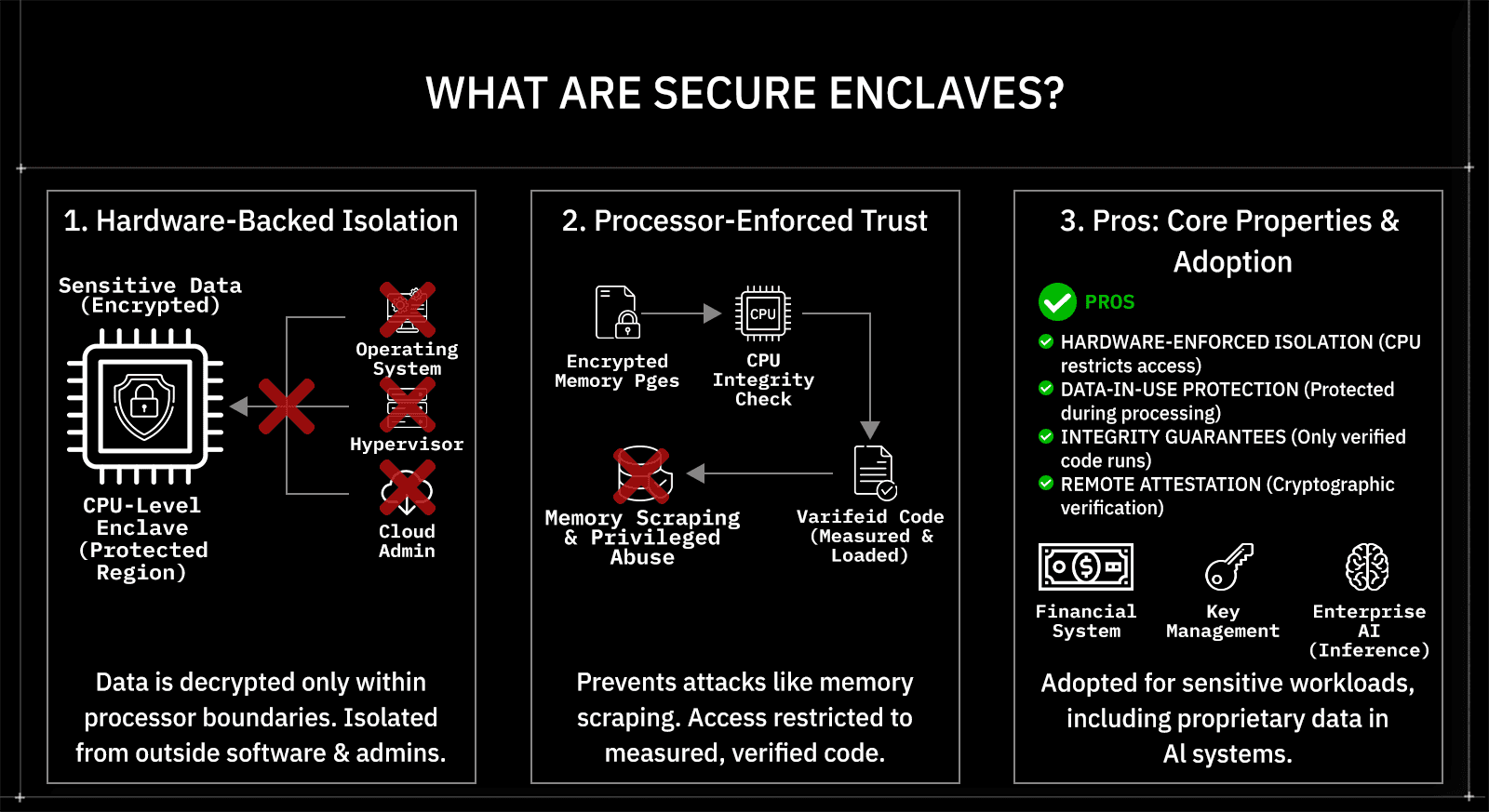
Secure enclaves are hardware-backed execution environments that keep code and data isolated while computation is actively happening. They are implemented at the CPU level and create a protected region of memory in which sensitive data is decrypted only within the processor's boundaries. Anything running outside the enclave, including the operating system, hypervisor, firmware, and cloud administrators, cannot read or modify the data inside it. This guarantees protection for data in use, not just data stored on disk or moving across the network.
Technically, secure enclaves change how trust is enforced during execution. Instead of relying on software permissions or infrastructure controls, enclaves rely on processor-enforced isolation. Memory pages belonging to the enclave are encrypted and integrity-checked by the CPU, and access is restricted to code that has been explicitly loaded and measured into the enclave. This design prevents common attack vectors such as memory scraping, privileged access abuse, and runtime inspection, even in multi-tenant cloud environments.
Several core properties define how secure enclaves work in practice:
Hardware-enforced isolation: The CPU ensures that only enclave code can access enclave memory.
Data-in-use protection: Sensitive data remains protected while being processed, not only when stored or transmitted.
Integrity guarantees: Only verified code is allowed to run inside the enclave.
Remote attestation: External systems can cryptographically verify that trusted code is running inside a genuine enclave.
Enterprises adopt secure enclaves when workloads must process sensitive data without expanding trust boundaries. Financial systems, cryptographic key management, and confidential computing workloads already rely on enclaves for this reason. As AI systems increasingly handle proprietary data, regulated information, and internal context during inference, the same hardware-backed isolation model becomes directly applicable to enterprise AI security.
Why AI workloads expose new security gaps
AI workloads introduce security risks that traditional enterprise controls were not designed to handle. Large language models process prompts, context, and intermediate results in plaintext during inference. This data often includes proprietary source code, internal documents, customer information, or regulated data. While encryption protects data at rest and in transit, it provides no protection once the model begins computation and the data is loaded into memory.
Inference expands the attack surface beyond what most security models assume. Prompts and responses may pass through shared infrastructure, third-party runtimes, or managed services before a result is returned. Memory, logs, debugging tools, and privileged system access are potential points of exposure. Even well-secured environments struggle to provide strong guarantees once data leaves the application boundary and enters model execution.
Several characteristics of modern AI systems make these gaps more pronounced:
Plaintext processing: Models require readable data to generate outputs.
Shared execution environments: Many LLM services run on multi-tenant infrastructure.
Extended data lifetimes: Prompts and context may persist in memory longer than expected.
Operational visibility: Logging and monitoring tools can unintentionally capture sensitive data.
As AI moves from experimentation to production, these gaps become unacceptable. Enterprises deploying internal copilots, customer-facing AI, or decision-support systems need stronger assurances that sensitive data is not exposed during inference. This shift is driving demand for security mechanisms that protect data while it is actively being processed, rather than relying solely on perimeter or transport-layer controls.
How secure enclaves enable zero-knowledge AI
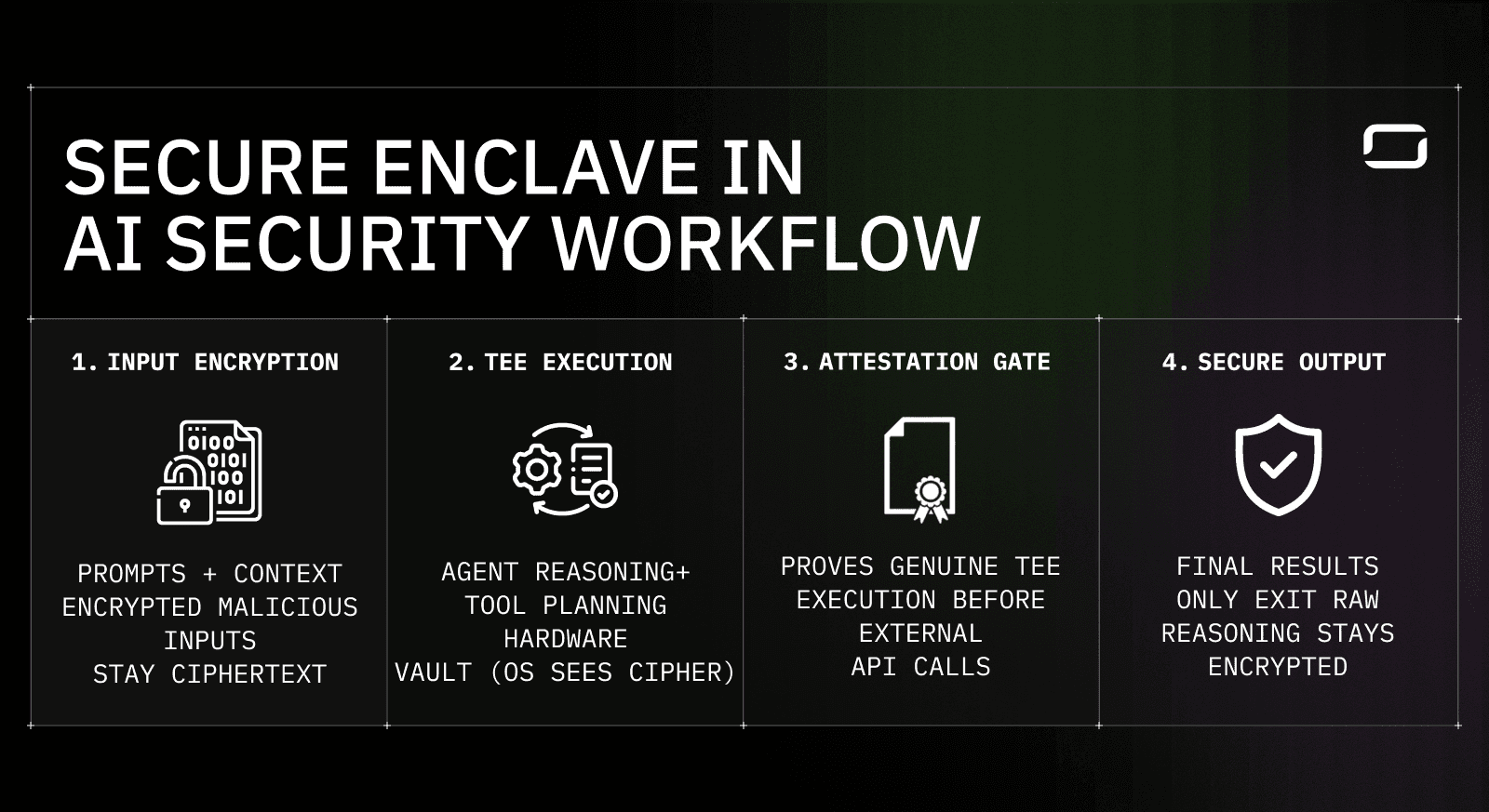
Secure enclave–based AI inference flow showing encrypted inputs, TEE execution, cryptographic attestation, and controlled output.
Zero-knowledge AI is enforced by controlling how data moves through the inference lifecycle. Secure enclaves ensure that sensitive data remains protected before execution, during inference, and after results are produced. The four stages below map directly to the workflow shown in the diagram.
1. Input encryption keeps prompts and context protected
Prompts, context, and sensitive inputs enter the system in encrypted form.
Until execution begins inside a trusted execution environment (TEE), this data remains ciphertext.
The operating system, host infrastructure, and surrounding services never see plaintext inputs.
What this prevents: early inspection, logging leakage, and pre-execution exposure.
2. TEE execution isolates reasoning and intermediate state
Decryption happens only inside the secure enclave.
Model reasoning, intermediate states, and tool-planning logic execute entirely within hardware-isolated memory.
The CPU enforces isolation, preventing OS- or hypervisor-level access to enclave memory.
What this prevents: memory scraping, privileged access abuse, and runtime inspection.
3. Cryptographic attestation verifies trusted execution
Before external API calls or downstream interactions occur, the enclave produces TEE attestation proofs.
These proofs confirm that approved code is running inside a genuine hardware-backed enclave.
External systems can verify execution integrity before allowing data exchange.
Why this matters: zero-knowledge guarantees become verifiable, not trust-based.
4. Secure output releases only final results
After inference completes, only the final response exits the enclave.
Intermediate reasoning, internal state, and execution traces remain encrypted.
No sensitive data is exposed through logs, telemetry, or debugging tools.
What this prevents: post-execution leakage and retrospective data access.
Together, these stages ensure that sensitive AI data never leaves hardware-enforced trust boundaries. Secure enclaves make zero-knowledge AI practical by protecting data throughout the entire execution lifecycle, giving enterprises verifiable guarantees during inference without relying on trust in the underlying infrastructure.
Why enterprise AI security breaks without hardware isolation
Enterprise AI security fails when runtime isolation is treated as a software problem. Most AI security controls stop protecting data once encryption ends and inference begins. At that point, prompts, context, and intermediate results exist in plaintext in memory. Software-based permissions, access controls, and monitoring tools cannot reliably prevent privileged access or runtime inspection in shared or managed environments.
Runtime exposure introduces risks that are difficult to mitigate with policy alone. Operating systems, hypervisors, debugging tools, and logging pipelines all have legitimate access paths that can be abused or misconfigured. Insider threats, misaligned privileges, and accidental data capture become realistic failure modes. Even well-governed environments struggle to prove that sensitive data was never accessible during execution.
Common failure points in software-only AI security include:
Memory inspection: Privileged processes can read application memory.
Operational tooling: Logs, traces, and crash dumps may capture sensitive data.
Infrastructure trust: Cloud administrators and service operators remain implicitly trusted parties.
Audit gaps: Inability to prove data isolation during inference.
Hardware isolation closes these gaps by shrinking the trust boundary. Secure enclaves enforce isolation at the processor level, ensuring that sensitive AI workloads remain protected even if surrounding systems are compromised. For enterprise AI, this shift from assumed trust to enforced isolation is critical for deploying models in production with meaningful security guarantees.
How Ollm applies secure enclaves to enterprise AI
Ollm applies secure enclaves as the execution foundation for enterprise AI, not as an optional security add-on. Its architecture is built so that AI requests are processed inside hardware-isolated environments from the moment sensitive data enters the system. Prompts, context, and intermediate inference data are decrypted only within secure enclaves, ensuring protection during runtime rather than relying solely on transport- or storage-level encryption.
This design allows Ollm to enforce zero-knowledge execution across aggregated LLM providers. Even though Ollm routes requests to hundreds of models through a single API, the data required for inference remains isolated from infrastructure, operators, and model providers. The surrounding systems handle routing, policy enforcement, and orchestration, while the enclave boundary ensures that plaintext data is never exposed outside the protected execution environment.
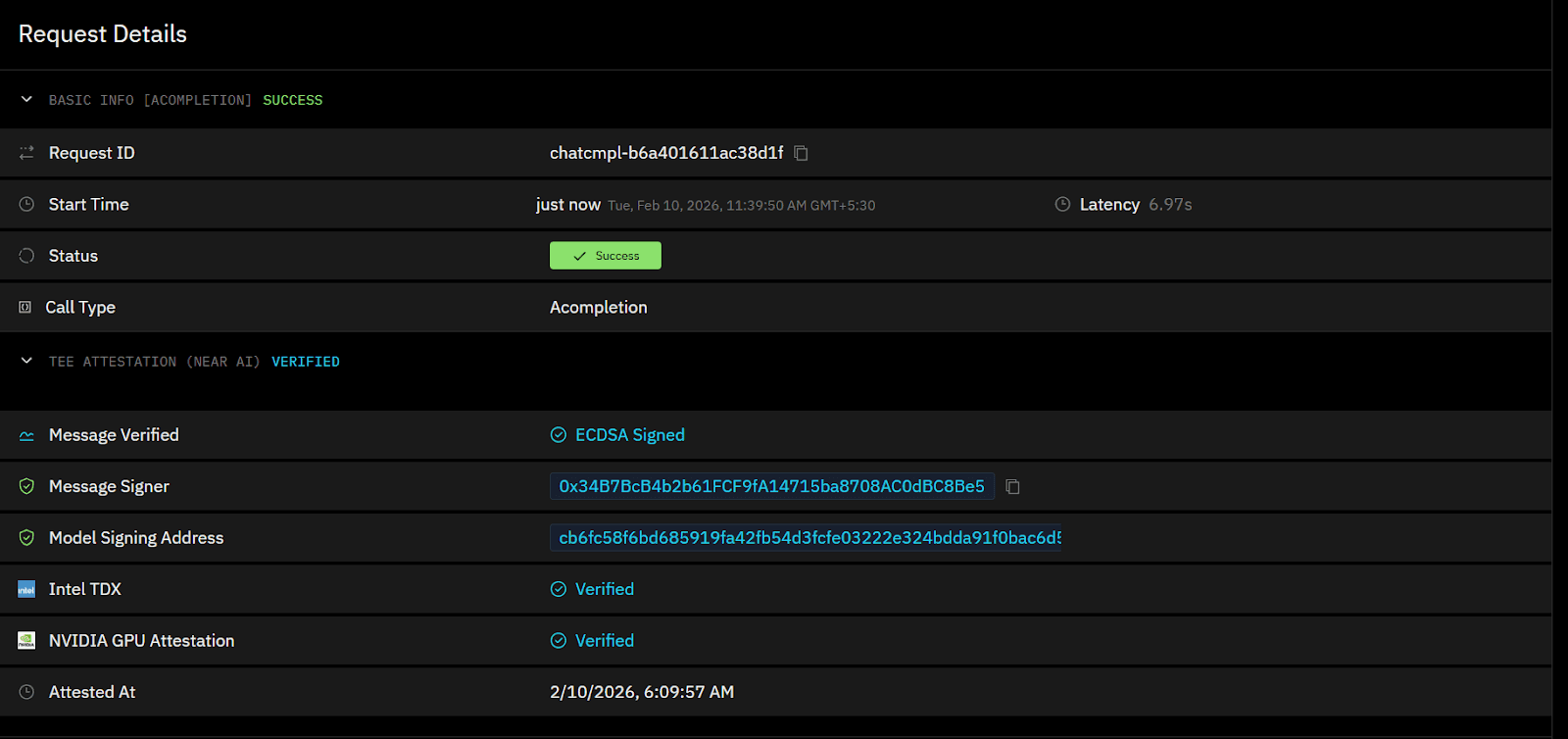
Ollm exposes hardware attestation signals so enterprises can independently verify how their AI requests are executed. Each inference request is backed by cryptographic attestation metadata tied to the underlying secure enclave environment, including CPU-level trusted execution and GPU-level isolation. This allows teams to confirm that requests are processed inside verified hardware-backed enclaves rather than relying on platform assurances alone.
Several architectural principles define how Ollm uses secure enclaves in practice:
Hardware-first isolation: Sensitive AI workloads execute inside CPU-enforced enclave boundaries.
End-to-end encryption: Data is encrypted in transit, encrypted at rest, and protected during execution.
Provider-agnostic execution: Models can be swapped or routed without expanding trust boundaries.
Verifiable privacy: Enclave attestation enables independent verification of the execution environment.
By anchoring its AI gateway in hardware isolation, Ollm reduces trust assumptions across the entire AI stack. Enterprises can adopt multiple LLMs without granting them access to sensitive data, making secure enclaves a core enabler for deploying AI safely in high-risk and regulated environments.
What makes Ollm’s secure enclave approach different
Ollm’s secure enclave approach is defined by how deeply isolation is integrated into the AI execution lifecycle. Secure enclaves are not limited to protecting a narrow function or a single model call. Instead, they are used to isolate sensitive data throughout inference, regardless of which underlying LLM provider is selected. This ensures that privacy guarantees remain consistent even as models, vendors, or routing strategies change.
Ollm enforces zero data retention by design. Prompts, responses, and inference context are not stored after execution, which removes the risk of sensitive data being accessed later through logs, databases, or internal systems. By eliminating persistent storage of AI inputs and outputs, Ollm reduces exposure not just during inference, but also after execution has completed.
Compliance is supported through verifiable TEE attestation proofs, not policy assurances. Ollm provides cryptographic evidence that inference is executed inside approved hardware-backed enclaves. This allows security and compliance teams to validate runtime isolation during audits, rather than relying on contractual claims or documentation alone.
Encryption and isolation are enforced continuously rather than selectively. Requests that enter Ollm encrypted are decrypted only inside hardware-protected enclaves, and are never exposed to external systems in plaintext. Memory, execution state, and intermediate results remain protected against inspection or leakage. This reduces reliance on operational discipline and contractual assurances, replacing them with hardware-backed guarantees.
Several characteristics distinguish this approach at an architectural level:
Isolation at the hardware layer: Security is enforced by the CPU rather than by software policy.
Uniform trust boundaries: All models operate under the same enclave-backed constraints.
Independent verification: Attestation enables enterprises to confirm that approved code is running in a protected environment.
Scalable aggregation: Hundreds of models can be accessed without weakening security guarantees.
Hardware attestation visibility: Each request includes verifiable attestation data for the enclave environment, including CPU-based trusted execution and GPU isolation, allowing customers to confirm that inference ran inside encrypted, hardware-protected boundaries.
For enterprises, this means security properties do not degrade as AI usage scales. As teams adopt new models or expand AI-driven workflows, Ollm maintains consistent data protection without increasing exposure or operational risk.
Ollm is designed to scale with enterprise AI demand without changing its security model. Usage can be increased by adding capacity as workloads grow, while organizations anticipating sustained or high-volume inference can work with Ollm to reserve capacity in advance. This allows teams to scale AI adoption predictably while maintaining the same enclave-backed isolation and zero-knowledge guarantees.
Why secure enclaves are becoming foundational for enterprise AI
Secure enclaves are shifting from a specialized security feature to a foundational requirement for enterprise AI. As organizations move AI systems into production, the data involved increasingly includes core intellectual property, regulated information, and customer data. Traditional security models that rely on perimeter controls, in-transit encryption, or trust in providers are no longer sufficient once inference begins and data is in memory.
Regulatory and compliance pressures are accelerating this shift. Enterprises are expected to demonstrate not only that data is encrypted but also that it is inaccessible to unauthorized parties during processing. Hardware-backed isolation provides a concrete way to prove this. Attestation and verifiable execution enable security teams to validate how AI workloads run, rather than relying on policy statements or contractual assurances.
Enterprise AI adoption is also changing the risk profile of infrastructure. AI systems are becoming embedded in decision-making, automation, and customer interaction flows. Failures or data leaks at this layer have a greater impact than those in earlier experimental deployments. Secure enclaves reduce this risk by narrowing trust boundaries and enforcing isolation at the processor level.
As AI becomes a core enterprise capability, hardware-enforced security is emerging as a baseline expectation. Secure enclaves provide the technical foundation for deploying AI systems with confidence, making them central to the next generation of enterprise AI architectures.
Conclusion
Secure enclaves provide the missing security layer for enterprise AI by protecting sensitive data during execution. Throughout this article, we examined how AI workloads expose data in memory, why software-only controls fail to close that gap, and how hardware-backed isolation enables zero-knowledge AI inference. Secure enclaves shift enterprise AI security from trust-based assumptions to verifiable, processor-enforced guarantees, making them suitable for regulated and high-risk environments.
For enterprises deploying AI beyond experimentation, the next step is architectural, not incremental. Evaluating how AI requests are routed, where inference occurs, and whether data is protected while in use is critical. Platforms like Ollm apply secure enclaves at the core of AI execution, enabling organizations to adopt multiple models without expanding data exposure.
Enterprises exploring production-grade AI should assess whether their current AI stack can provide verifiable runtime isolation. If sensitive data, internal context, or regulated information is involved, secure enclave–based architectures are a practical foundation for moving forward with confidence.
FAQ
1. How do secure enclaves protect AI data during inference?
Secure enclaves protect AI data by isolating prompts, context, and intermediate inference states inside hardware-encrypted memory. Data is decrypted only within the CPU boundary and cannot be accessed by the operating system, hypervisor, or cloud administrators. This provides protection for data in use, closing the gap left by encryption at rest and in transit.
2. What is zero-knowledge AI inference and why does it matter for enterprises?
Zero-knowledge AI inference ensures that sensitive data is never visible to infrastructure providers or model vendors during execution. Enterprises can run LLM inference while preventing third parties from inspecting prompts or outputs. This model is critical for regulated industries and proprietary workloads that require verifiable data isolation.
3. How is Ollm different from traditional AI gateways in terms of security?
Ollm is built around secure enclaves as the execution foundation rather than relying on software isolation. Prompts and inference data are processed inside hardware-protected environments, enabling zero-knowledge execution across multiple LLM providers. This reduces trust assumptions and provides verifiable privacy guarantees that software-only gateways cannot offer. Ollm also exposes hardware attestation metadata, including CPU and GPU enclave verification, so enterprises can independently validate how each inference request was executed.
4. Can Ollm support multiple LLM providers without exposing sensitive data?
Yes. Ollm aggregates hundreds of LLMs behind a single API while maintaining consistent security guarantees. Secure enclaves ensure that sensitive data remains isolated during inference, regardless of which underlying model is used. This allows enterprises to switch or evaluate models without expanding data exposure.
5. Are secure enclaves required for enterprise AI compliance?
Secure enclaves are not always mandatory, but they are increasingly expected for high-risk and regulated AI workloads. Compliance frameworks often require proof that sensitive data is not accessible during processing. Hardware-backed isolation and attestation provide a practical way to meet these requirements as AI systems move into production.
"/><stop offset="1" stop-color="rgb(80, 78, 87)"/></linearGradient></defs><g d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z M 142.346 0.381 L 162 0.381 L 162 20 L 142.346 20 Z M 153.986 8.381 L 158.375 8.381 L 158.375 12 L 153.986 12 L 153.986 16.571 L 150.36 16.571 L 150.36 12 L 145.972 12 L 145.972 8.381 L 150.36 8.381 L 150.36 4.19 L 153.986 4.19 Z" fill="transparent" height="20px" id="cWM2PbaAz" width="162.00000833847133px"><path d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z" fill="url(%23UyELkL66Q-1582027827-linear-gradient)" height="20px" id="UyELkL66Q" width="134.52277004415487px"/><path d="M 0 0 L 19.654 0 L 19.654 19.619 L 0 19.619 Z" fill="rgb(176, 0, 0)" height="19.618991595424752px" id="t30DbKa7C" transform="translate(142.346 0.381)" width="19.653710120697895px"/><path d="M 8.014 4.19 L 12.403 4.19 L 12.403 7.81 L 8.014 7.81 L 8.014 12.381 L 4.389 12.381 L 4.389 7.81 L 0 7.81 L 0 4.19 L 4.389 4.19 L 4.389 0 L 8.014 0 Z" fill="rgb(255, 255, 255)" height="12.380917026238919px" id="bLcZkJmGc" transform="translate(145.972 4.19)" width="12.402826775197639px"/></g></svg>)