|

TL;DR
Self-hosted AI gateways carry significant hidden TCO, including engineering maintenance, security patching, compliance documentation, and incident response, which rarely appear in initial cost estimates but consistently dominate the 12-month bill.
Encryption in transit isn't enough; the real security gaps in self-hosted setups are prompt/response persistence, lack of hardware-level isolation, and the absence of any cryptographically verifiable execution evidence.
TEE-backed inference (Intel TDX + NVIDIA GPU Attestation, where supported) runs workloads in hardware-isolated environments, producing cryptographic attestation evidence about execution integrity, something no self-hosted gateway can replicate at the application layer.
OLLM defaults to not storing prompt and response content at the gateway layer; usage metadata may still be logged, and content logging is opt-in via explicit configuration, making zero-retention an enforceable infrastructure default, not an app-level best practice.
Scaling with a managed confidential gateway is a procurement decision, not an engineering project. Rate-limit-aware routing, load balancing, and failover are handled at the gateway layer, with reserved capacity available for high-volume use cases.
As AI moves deeper into production workflows, the infrastructure layer handling model access has become a serious engineering and security decision. AI gateways, the layer sitting between your application and LLM providers, determine how requests are routed, how costs are tracked, whether sensitive data is retained, and whether any of those guarantees are verifiable. Choosing between self-hosting that layer and using a managed confidential gateway isn't just an infrastructure preference; it's a decision with real compliance, security, and cost consequences.
This piece breaks down the true total cost of ownership on both sides, covering infrastructure, engineering overhead, security depth, hardware-level confidentiality, and scaling, so you can evaluate the trade-off with the full picture in front of you.
Why Teams Self-Host AI Gateways
A self-hosted AI gateway is a privately deployed middleware layer that your team owns, operates, and maintains. It handles routing between your application and LLM providers, enforces rate limits, tracks usage, and manages authentication, all running on infrastructure you control. For teams with strict data residency requirements or those operating under HIPAA, SOC 2, or the EU AI Act, that level of control over the request path is a legitimate architectural requirement.
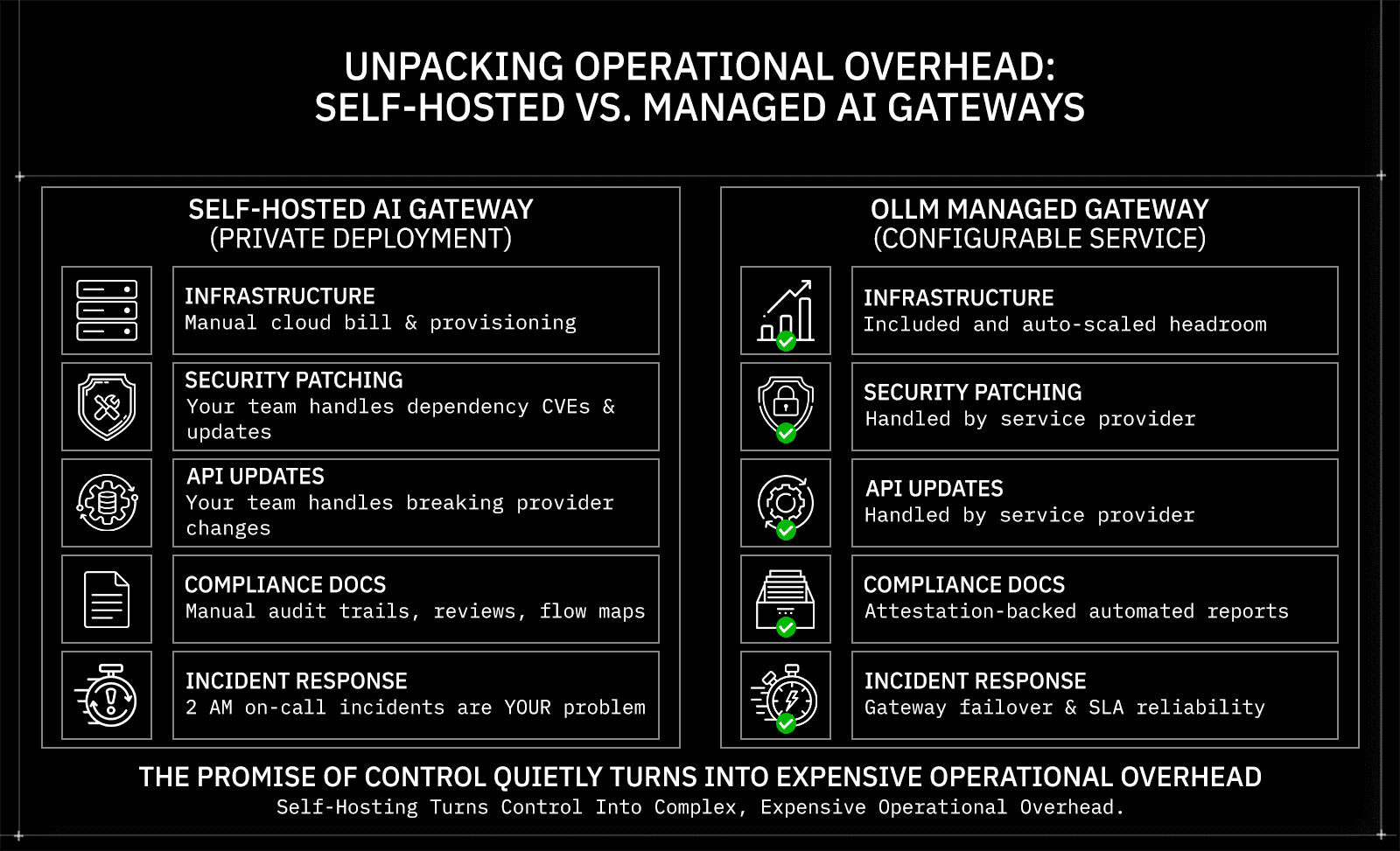
The gap shows up when you move from planning to production. A self-hosted gateway is not a deploy-and-forget system. When OpenAI ships a breaking change to their API response format, your routing logic needs to be updated before it silently breaks downstream. When a CVE drops against a dependency in your gateway stack, your team owns the patch cycle. When your inference traffic doubles because a new feature ships, someone needs to have already provisioned the headroom. None of that is accounted for in a compute bill. A mid-sized engineering team can easily spend 20 to 40 percent of a senior engineer's annual capacity keeping a self-hosted gateway operational before writing a single line of product code.
In regulated environments, the overhead compounds further. A healthcare platform handling patient-adjacent queries needs more than a correctly configured gateway. It needs documented audit trails, recurring security reviews, and a clear data flow map that can withstand a SOC 2 audit or an EU AI Act compliance assessment. That documentation doesn't generate itself. When something breaks at 2 am, whether a provider endpoint goes down, a rate limit triggers unexpectedly, or a TLS certificate expires mid-request, that is your team's incident to resolve, not a vendor's SLA to enforce.
Cost Category | Self-Hosted | OLLM |
Infrastructure | Your cloud bill | Included |
Security patching | Your team | Handled |
Provider API updates | Your team | Handled |
Compliance documentation | Manual | Attestation-backed |
Incident response | On-call engineering | Gateway-layer failover |
Control is valuable. But unaccounted operational overhead quietly turns a cost-saving decision into one of your most expensive infrastructure choices.
What an AI Gateway Actually Does
AI gateways sit between your application and the underlying LLM providers, handling the operational layer so your application doesn't have to. At the core, that means a unified API across hundreds of models, centralized cost tracking, rate-limit enforcement, and routing logic that keeps inference running even when a provider has issues.
Model selection in a gateway can work a few different ways:
App-driven: the application specifies a model alias explicitly, and the gateway routes to the correct provider and deployment
Policy-driven: the gateway selects among approved deployments based on latency, cost, or availability
Hybrid: the application specifies a model alias, and the gateway handles fallback, load balancing, and rate-limit-aware routing around it
Most self-hosted gateways support some version of this. The difference with a managed confidential gateway like OLLM is what happens underneath that routing layer, specifically, how the inference request is executed, whether prompt/response content is persisted, and whether any of those guarantees are cryptographically verifiable.
Connecting to OLLM works through an OpenAI-style, OpenAI-SDK-compatible API for supported endpoints. The model string tells the gateway both which provider to route to and which model to run, with TEE-backed execution handled automatically for supported paths:
from openai import OpenAI |
cURL
curl https://api.ollm.com/v1/chat/completions -H "Content-Type: application/json" -H "Authorization: Bearer your-api-key" -d '{ |
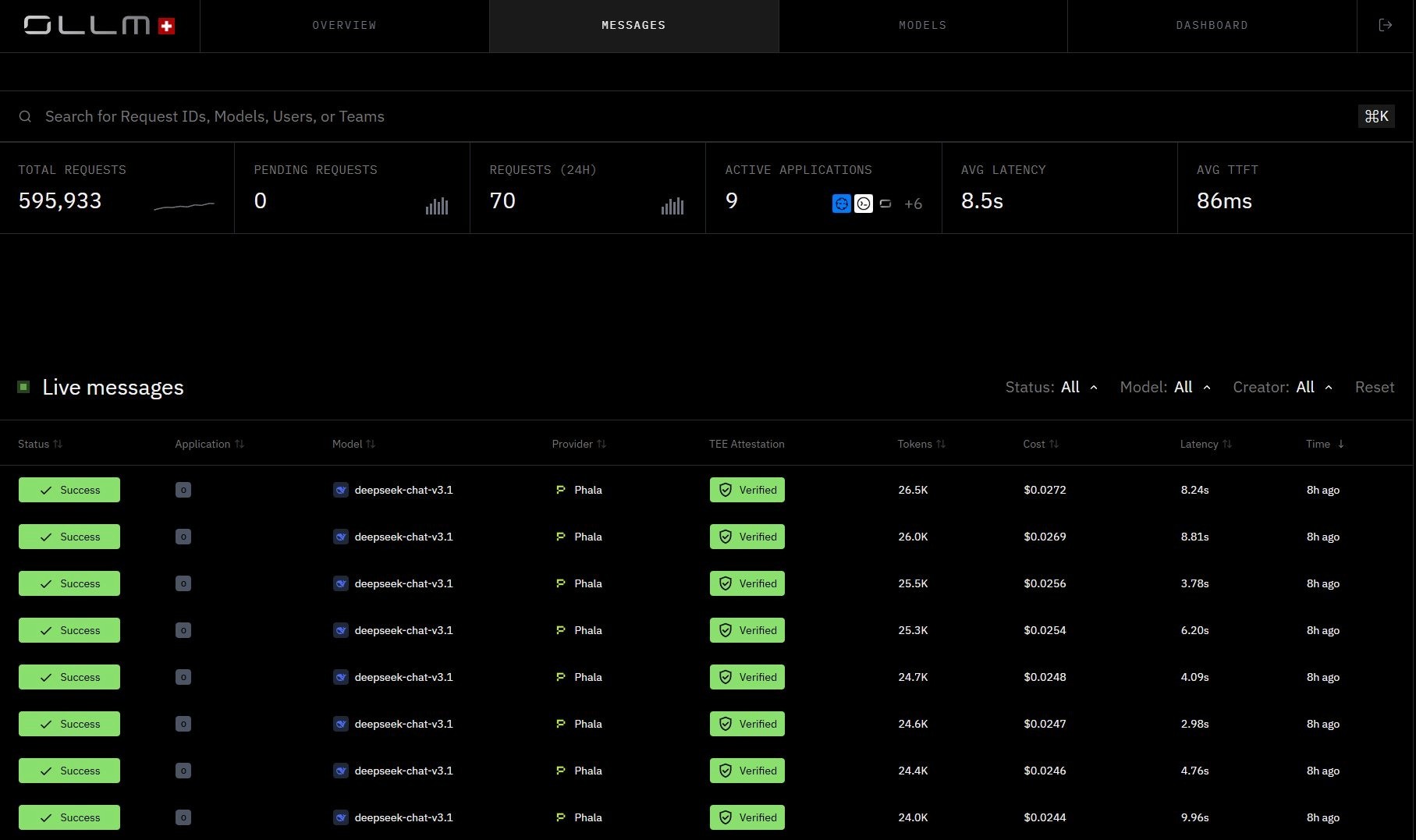
OLLM Messages view, live inference requests with per-request TEE attestation status, cost, latency, and token counts:
Capability | Self-Hosted | OLLM |
Unified API | Yes | Yes |
Multi-mode access | Yes | Yes, hundreds of models across providers via one API |
Failover | Depends on implementation | Available |
Zero-retention defaults | Manual configuration | Configurable by default; prompt/response content not stored unless explicitly enabled |
Hardware-backed execution | Not available | TEE-backed (supported paths) |
Cryptographic attestation | Possible on supported hardware (H100/H200), but requires custom implementation and maintenance | Built-in; Intel TDX + NVIDIA GPU Attestation included by default |
The Real Total Cost of Ownership
Infrastructure costs are the easy part to calculate. Everything else is where self-hosted gateways quietly get expensive.
A self-hosted gateway requires compute, but it also requires the engineering capacity to keep it production-ready. That means someone owns provider API compatibility when upstream changes ship, someone maintains the security posture when vulnerabilities are disclosed, and someone is on-call when routing breaks under load. In regulated environments, add compliance documentation, audit trails, and periodic security reviews on top of that.
The categories that rarely show up in initial estimates are engineering time, compliance overhead, observability pipelines, and scaling management. A mid-sized engineering team maintaining a self-hosted gateway can easily spend 20–40% of a senior engineer's annual capacity just keeping it operational, before writing a single line of product code.
With OLLM, the operational layer is handled at the gateway level. Observability and cost tracking are centralized. Routing, failover, and rate-limit enforcement are built in. Scaling happens through centralized quota enforcement and load balancing without provisioning new infrastructure. For higher-volume needs, reserved capacity is available through sales rather than requiring a new infrastructure deployment.
OLLM Dashboard, centralized spend tracking, request volume, average TTFT, and token usage across all providers in one view:
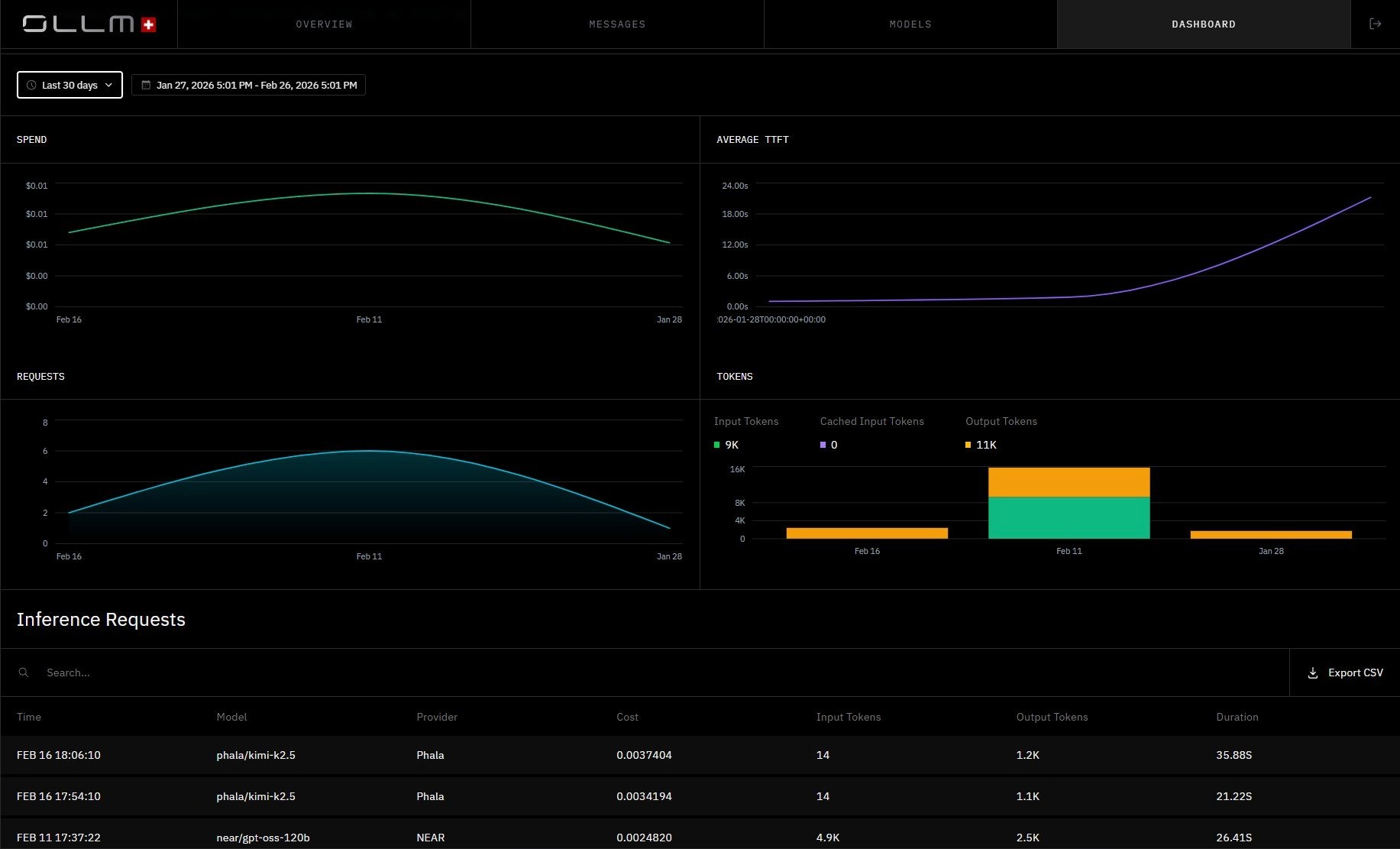
The computer bill is visible. The engineering burden is not, and that's what makes self-hosted TCO consistently underestimated.
Where Self-Hosted Gateways Fall Short on Security
Security is usually the primary argument for self-hosting. The assumption is that keeping infrastructure in-house ensures data safety. In practice, that assumption has some significant gaps.
The most common gap is the persistence of prompt and response. Many self-hosted gateway implementations log request and response content by default, for debugging, observability, or audit purposes. That creates a durable store of sensitive prompt data, making it a prime target for breaches. The question isn't just whether your gateway encrypts data in transit, but whether sensitive prompt-and-response content is being written to disk at all, and, if so, who can access it.
The second gap depends on your self-hosted architecture. If your gateway routes requests to third-party provider APIs, you control the gateway layer but have no visibility into what happens at the inference level on the provider's side, what hardware the model runs on, whether the execution environment is isolated, or whether prompt content is retained upstream. If you're running models directly on your own hardware, you control the full stack, and there are no co-tenants to worry about. But unless that hardware consists of confidential computing chips (such as H100s or H200s with the appropriate stack), you still have no cryptographic mechanism to prove execution integrity, you're relying on physical control of the environment, not verifiable evidence of what happened inside it.
The third gap is verifiability, and it applies in both cases. Even with full ownership of your infrastructure, there is no cryptographic way for an auditor, a compliance team, or a regulated client to independently verify that inference ran in an isolated environment, that prompt content wasn't persisted, or that the execution environment wasn't tampered with. Physical control and policy documentation are not the same as cryptographic proof, and in regulated environments, the difference increasingly matters.
These aren't edge cases. For teams operating under HIPAA, SOC 2, or the EU AI Act, these are exactly the questions that come up during security reviews.
How OLLM Handles Confidentiality at the Hardware Level
Most gateway-level security stops at the network layer, TLS in transit, access controls, and maybe encrypted storage. OLLM goes further by routing supported workloads to providers that run inference in hardware-isolated environments, pushing confidentiality controls down to the layer where inference actually happens.
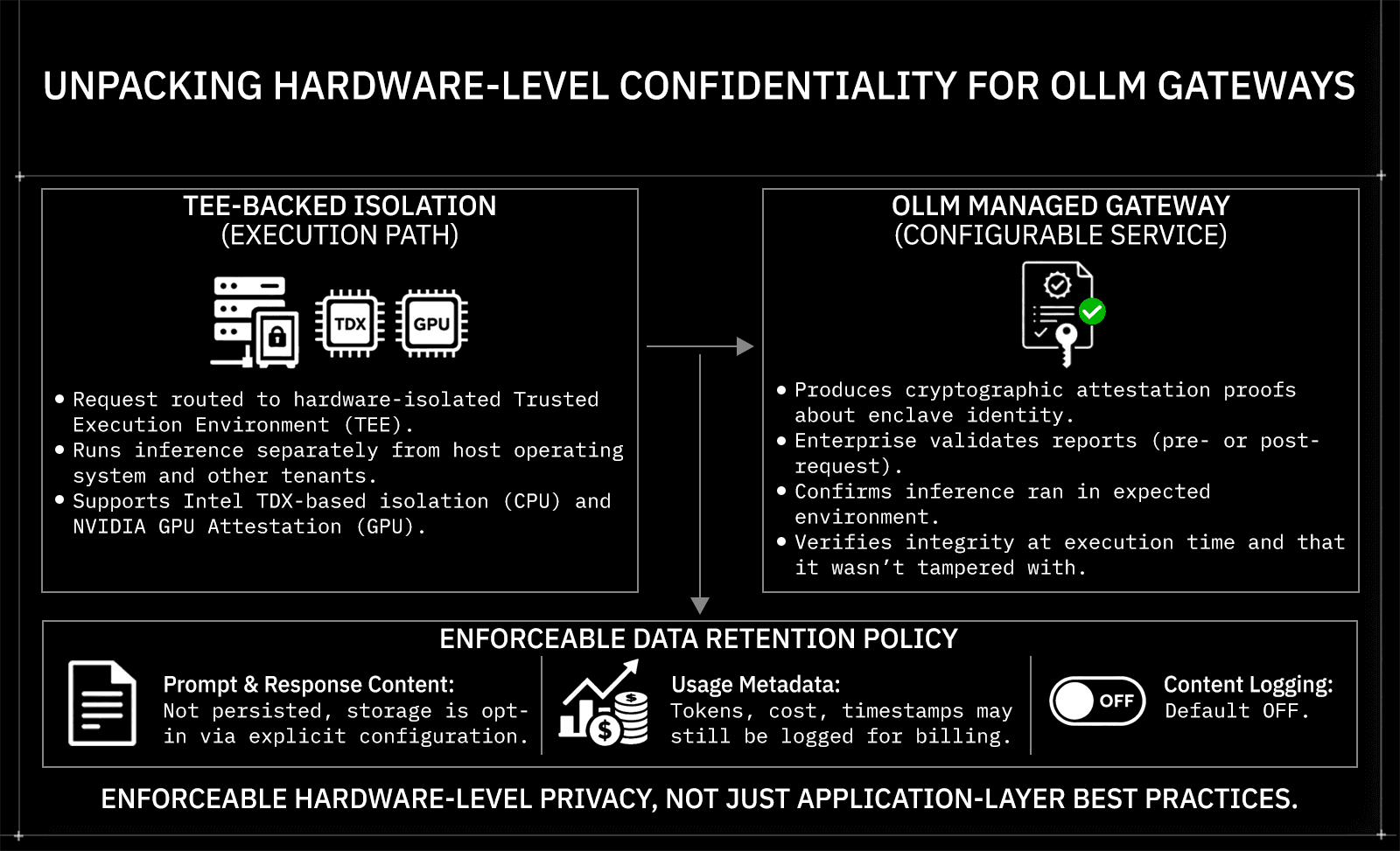
TEE-backed execution is the core mechanism. Every model available through OLLM runs on confidential hardware; inference workloads execute inside hardware-isolated enclaves, separated from the host operating system and inaccessible to the underlying infrastructure.
OLLM Models view: every listed model shows its provider and TEE status. All models shown here run via TEE-backed provider paths (NEAR and Phala), where Intel TDX-based isolation and NVIDIA GPU attestation are available, where the stack supports it:
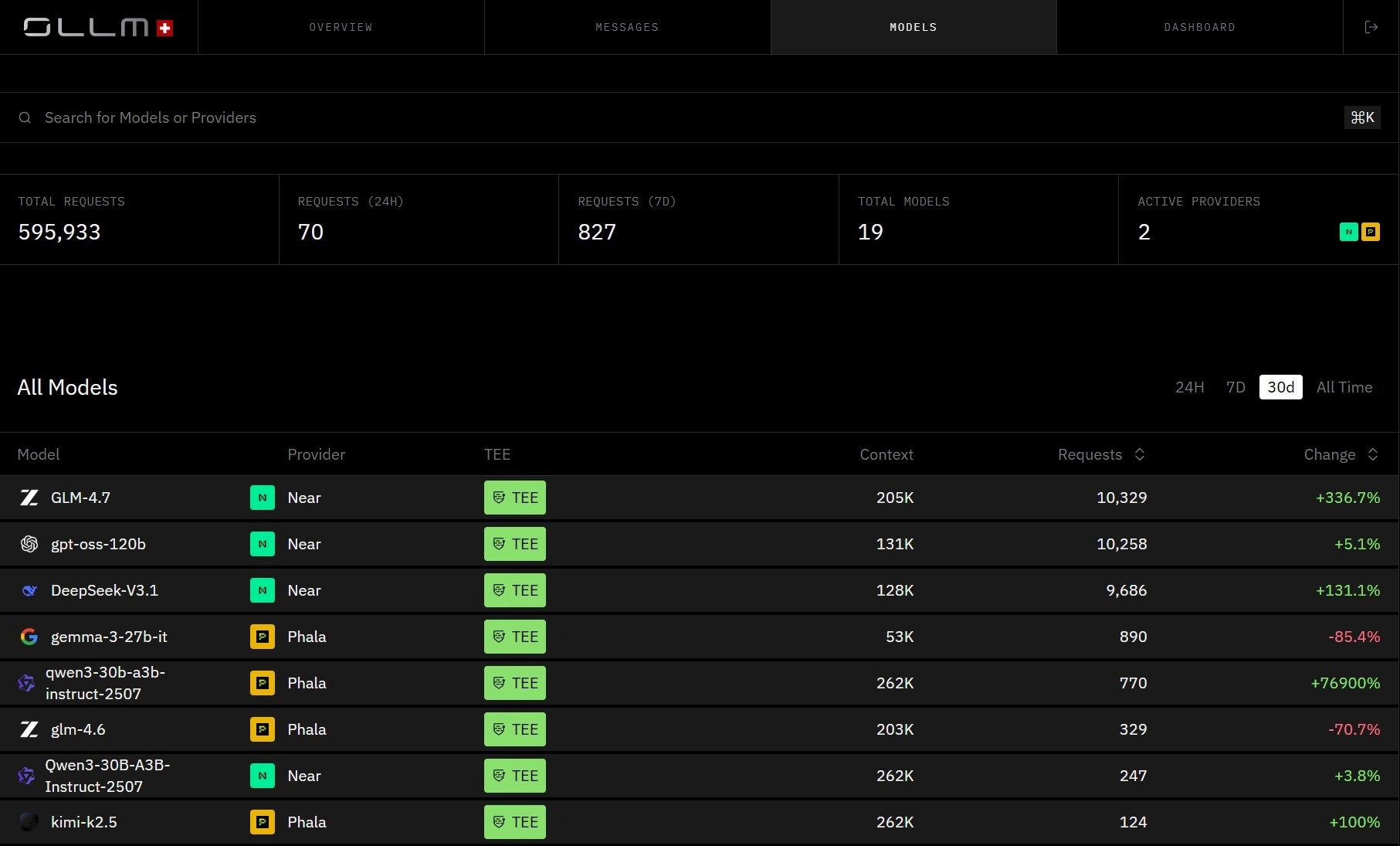
What makes this meaningful beyond marketing is attestation. TEE-backed execution can enable cryptographic attestation. Depending on the stack, technologies such as Intel TDX (for the confidential VM) and NVIDIA GPU attestation (for the GPU/device state) can generate evidence about the execution environment, including:
The identity and integrity of the confidential VM/workload measurement (per the attestation policy)
That the workload ran in a TEE-backed environment consistent with the policy
That the host can't directly read guest memory (within the TEE threat model)
Optionally, device/GPU claims when GPU attestation is available
Enterprises can validate attestation evidence as part of a trust policy, typically before provisioning secrets (and, in some designs, before sending sensitive prompts), and/or before accepting results. This model can replace purely trust-based isolation claims with cryptographically verifiable evidence about the execution environment, a fundamentally different standard than a vendor's compliance documentation.
On data retention, OLLM defaults to not storing prompt and response content at the gateway layer. To be precise about what that means:
Prompt/response content: not persisted by default; storage is opt-in via explicit configuration
Usage metadata: tokens, cost, timestamps: may still be logged for billing and reliability
Content logging: can be explicitly enabled when needed, but is off by default
This distinction matters because zero-retention isn't an absolute claim across all configurations; it's an enforceable default backed by policy and configuration guardrails, not just an app-level best practice.
Scaling Without the Operational Burden
Scaling an AI gateway sounds straightforward until you're actually doing it. With self-hosted infrastructure, scaling means capacity planning ahead of demand, provisioning new compute, managing failover configurations, and ensuring rate limits are enforced consistently across an expanding deployment. Every spike in usage is an infrastructure problem before it's a product problem.
OLLM handles scaling at the gateway layer. Rate-limit-aware routing, load balancing, and failover are built into how requests are executed, not something your team needs to configure and maintain separately. If a provider hits a rate limit or becomes unavailable, the gateway routes around it based on the execution policy, without requiring manual intervention.
For teams with predictable high-volume usage, the practical path is straightforward:
For immediate needs: load additional credits to increase capacity without any infrastructure changes
For sustained high-volume usage: contact sales to discuss reserving capacity, which ensures shared quota limits don't constrain availability during peak periods
The broader point is that scaling with OLLM is a procurement and configuration decision, not an engineering project. Teams don't need to size instances, pre-provision headroom, or build their own failover logic. That operational surface simply doesn't exist at the application layer; it's managed at the gateway level through configuration.
Making the Call: Is Self-Hosting Worth It?
Self-hosting trades operational burden for control, and that trade only makes sense if the control you gain is worth what you're giving up in engineering time, security depth, and verifiability. For teams in regulated environments, the security properties that actually matter, hardware-level isolation, cryptographic attestation evidence, and verifiable zero-retention, are difficult to replicate on self-hosted infrastructure, regardless of how well-configured it is.
To evaluate your true TCO, start by asking: what is the fully-loaded engineering cost of maintaining your gateway over 12 months; whether your current setup can provide cryptographic proof of execution integrity to auditors; and whether prompt and response payloads are being persisted anywhere in your logging pipeline. Those three questions alone quickly reframe the conversation.
Confidential AI infrastructure is increasingly expected in regulated environments, not optional. To see how OLLM's unified confidential gateway handles execution integrity, zero-retention defaults, and provider routing, explore the platform at ollm.com or reach out to discuss reserved capacity for your use case.
FAQs
1. What is the difference between TEE-based AI inference and standard encrypted inference?
Standard encrypted inference protects data in transit and at rest, but the data is decrypted during computation, meaning the host OS, hypervisor, or a compromised process can theoretically access it. TEE-based inference runs inside a hardware-isolated enclave (such as Intel TDX) where even the host cannot inspect the workload, and cryptographic attestation proofs verify that the environment wasn't tampered with before or during execution.
2. How does OLLM's zero-retention policy work in practice, and what data is still logged?
OLLM defaults to not persisting prompt and response content at the gateway layer. What is still logged by default is usage metadata, tokens consumed, cost, and timestamps, for billing and reliability purposes. Prompt and response content logging is opt-in via explicit configuration, meaning it won't appear in spend logs unless deliberately enabled.
3. What are the compliance implications of prompt data persistence in self-hosted AI gateways?
Under frameworks such as HIPAA and the EU AI Act, any durable storage of sensitive prompt data is a regulated data asset, subject to access controls, breach-notification requirements, and audit obligations. Self-hosted gateways that log request and response content by default can inadvertently create compliance liabilities that weren't accounted for in the original architecture decision.
4. How does Intel TDX attestation work in an AI inference pipeline?
Intel TDX (Trust Domain Extensions) creates hardware-isolated virtual machines called Trust Domains. During inference, an attestation report is generated that cryptographically captures the enclave's identity, configuration, and integrity state. This report can be validated as part of a trust policy, typically before provisioning secrets or sending sensitive prompts, and/or before accepting results by an auditor, compliance team, or automated verification workflow.
5. How does OLLM's single API simplify working with multiple LLM providers?
Rather than managing separate integrations, API keys, and data-handling agreements for each provider, OLLM gives you access to hundreds of models across multiple providers through a single OpenAI-compatible API. You explicitly select the model you want, OLLM authenticates the request, routes it to the correct provider's TEE-backed environment, and returns the response along with attestation artifacts. There is no automatic model substitution or background routing; model choice stays entirely in your control.
"/><stop offset="1" stop-color="rgb(80, 78, 87)"/></linearGradient></defs><g d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z M 142.346 0.381 L 162 0.381 L 162 20 L 142.346 20 Z M 153.986 8.381 L 158.375 8.381 L 158.375 12 L 153.986 12 L 153.986 16.571 L 150.36 16.571 L 150.36 12 L 145.972 12 L 145.972 8.381 L 150.36 8.381 L 150.36 4.19 L 153.986 4.19 Z" fill="transparent" height="20px" id="cWM2PbaAz" width="162.00000833847133px"><path d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z" fill="url(%23UyELkL66Q-1582027827-linear-gradient)" height="20px" id="UyELkL66Q" width="134.52277004415487px"/><path d="M 0 0 L 19.654 0 L 19.654 19.619 L 0 19.619 Z" fill="rgb(176, 0, 0)" height="19.618991595424752px" id="t30DbKa7C" transform="translate(142.346 0.381)" width="19.653710120697895px"/><path d="M 8.014 4.19 L 12.403 4.19 L 12.403 7.81 L 8.014 7.81 L 8.014 12.381 L 4.389 12.381 L 4.389 7.81 L 0 7.81 L 0 4.19 L 4.389 4.19 L 4.389 0 L 8.014 0 Z" fill="rgb(255, 255, 255)" height="12.380917026238919px" id="bLcZkJmGc" transform="translate(145.972 4.19)" width="12.402826775197639px"/></g></svg>)