|

TL;DR
OLLM and the OpenAI API Gateway solve the same problem in different ways: both let applications use external LLMs in production, but they define the trust boundary and data visibility in fundamentally different ways.
OpenAI API Gateway prioritizes speed and simplicity: it is best suited for user-facing features and rapid iteration, where provider-managed execution and policy-based guarantees are sufficient.
OLLM prioritizes confidentiality and verification: it acts as a confidential AI gateway that minimizes provider visibility into prompts using hardware-backed execution and attestation.
The decision is about trust, not infrastructure: the real trade-off is how much sensitive data external providers are allowed to see, not who runs GPUs or hosts models.
Choose based on data sensitivity: managed APIs are well-suited for general SaaS workflows, while confidential gateways like OLLM are ideal for regulated or high-sensitivity production environments.
As AI moves from experimental features into production-critical workflows, the question is no longer just which model to use, but who can see the data those models process. For many teams, especially in regulated or enterprise environments, the primary concern is not inference quality or latency, but whether prompts, documents, and internal context remain confidential throughout the request lifecycle.
This is where the choice between OLLM and the OpenAI API Gateway becomes relevant. Both act as intermediaries between applications and large language models, but they define the trust boundary in very different ways. One approach treats the model provider as a trusted processor of application data. The other is designed to minimize provider visibility altogether, even while using external models.
The distinction matters most when AI is applied to sensitive internal workflows such as HR systems, financial analysis, legal review, or document intelligence. In these scenarios, teams want the benefits of modern LLMs while ensuring that private business data is not logged, retained, or exposed beyond tightly controlled boundaries. The decision is less about the speed of integration and more about confidentiality guarantees, compliance posture, and the degree of trust placed in external infrastructure.
Before comparing trade-offs in detail, it helps to view OLLM and the OpenAI API Gateway as two distinct system-level approaches to the same problem: generating LLM responses in production while balancing capability, risk, and operational simplicity. The way each platform handles data flow, encryption, and provider access directly shapes its suitability for real-world enterprise use cases.
What OLLM Is and How It Works as a Confidential AI Gateway
OLLM is a confidential AI gateway that routes application requests to external large language model providers while minimizing how much those providers can see. Instead of calling a model vendor’s API directly, applications send requests through OLLM, which enforces encryption, confidential execution, and verifiable privacy guarantees along the entire request path.
The key idea behind OLLM is not where models run, but where trust stops. In a typical API integration, prompts and context are visible to the provider operating the model. With OLLM, requests are executed inside confidential computing environments and verified using hardware attestation, so sensitive data is not exposed in plaintext or retained outside defined boundaries.
This approach is designed for production systems where AI touches sensitive inputs such as internal documents, HR data, financial records, or proprietary business logic. Teams still get access to modern, high-quality models, but with stronger assurances around data handling, auditability, and compliance.
From an application’s perspective, integration remains simple. OLLM exposes an OpenAI-compatible API, so existing SDKs and workflows continue to work. What changes is everything behind that API: request routing, provider selection, execution environment, and the guarantees around how data is processed.
How OLLM Is Structured: Layered Service Architecture
OLLM sits between applications and model providers, acting as a control and verification layer rather than a model runtime.

At a system level, the flow looks like this:
Application Layer
Web apps, backend services, or internal tools generate prompts and structured inputs as part of normal product workflows. These requests are sent to OLLM using a familiar API interface.
Confidential Gateway Layer
OLLM receives the request, applies encryption, and enforces confidential execution guarantees before forwarding it to the user-selected model provider.
Confidential Execution and Provider Routing
Requests are forwarded to supported model providers that run inside trusted execution environments (TEEs). Hardware-level attestation verifies that inference is performed on approved systems before execution proceeds.
Verified Response Path
Model outputs are returned through OLLM, preserving the same confidentiality guarantees. Operational metadata such as latency, token usage, cost, and attestation status can be inspected independently, without exposing or linking prompt contents or user data.
This design allows teams to use external LLMs in production while significantly reducing the risk of prompt leakage, data retention, or opaque processing within third-party infrastructure.
What OLLM Does at the Gateway Layer
OLLM is intentionally focused. It does not try to replace model hosting platforms or inference stacks.
What OLLM enables:
Confidential prompt execution using hardware-backed TEEs
Requests are executed within confidential computing environments, reducing the risk of plaintext exposure during inference.
Verifiable privacy through execution and GPU attestation
Hardware-backed attestation enables verification of where and how inference is performed, rather than relying solely on provider assurances.
Zero data retention by design
OLLM does not retain user prompts, files, or request content. Only minimal operational metadata, such as token usage and attestation records, is recorded, and it is exposed transparently for verification rather than stored as application data.
Provider abstraction through a single API
Applications can access multiple supported models through one OpenAI-compatible interface, without coupling directly to individual providers.
Operational visibility without data exposure
Teams can monitor latency, usage, cost, and execution status without inspecting or storing prompt contents or user data.
What OLLM does not do:
Host or run models on customer infrastructure
OLLM does not operate model runtimes or inference servers on behalf of users.
Manage GPUs, clusters, or inference runtimes
Capacity planning, hardware management, and model execution remain outside OLLM’s scope.
Provide fine-tuning or model training workflows
OLLM does not train, fine-tune, or adapt models on customer data.
Train on or retain user data
User prompts, files, and request contents are not stored or reused for training or analytics purposes.
Replace application-level orchestration or business logic
Prompt construction, workflow control, and application behavior remain fully under the application's control.
Understanding this boundary is important. OLLM defines the gateway layer in a production AI system, focusing on confidentiality, verification, and controlled access to external models rather than on operating model infrastructure.
How Teams Use OLLM in Sensitive Production Workflows
OLLM is typically adopted in environments where AI is applied to sensitive internal workflows, but teams still want to rely on external, high-quality language models. Common examples include HR systems, internal analytics tools, legal document review, and financial reporting pipelines, where prompts often contain private employee data, confidential documents, or proprietary business context.
In these scenarios, the goal is not to move inference in-house, which can be costly, operationally complex, and difficult to maintain at scale. Operating on-site data centers or dedicated GPU infrastructure introduces ongoing challenges around capacity planning, reliability, and security. Instead, teams route requests through OLLM to reduce the amount of sensitive data exposed to external model providers. By enforcing confidential execution and hardware-backed verification before inference, OLLM enables teams to use modern LLMs while maintaining stronger guarantees around data handling and auditability.
Using OLLM in this way enables several practical outcomes:
Stronger Data Protection
Sensitive inputs such as employee records, performance feedback, or internal documents are processed through confidential execution environments, reducing the risk of prompt logging or unintended data retention.Clear Trust Boundaries
Teams gain explicit visibility into where data is processed and under what guarantees, rather than relying solely on provider policy statements or contractual assurances.Minimal Changes to Application Architecture
Because OLLM exposes an OpenAI-compatible API, existing applications and SDK integrations continue to work without major refactoring.Operational Transparency Without Data Exposure
Request-level metrics such as latency, token usage, cost, and execution attestation can be inspected without revealing prompt contents, making it easier to operate AI features in production environments.
This pattern is increasingly common in enterprise settings where AI must operate on sensitive data, but full model hosting or self-managed inference infrastructure would introduce unnecessary complexity. OLLM allows teams to focus on building AI-powered features while tightening control over how data flows through external systems.
What the OpenAI API Gateway Is and How It Works
The OpenAI API Gateway is a managed interface for accessing OpenAI’s language and multimodal models from production applications. Teams integrate by sending structured requests over HTTP and receiving model outputs such as text generation, summarization, embeddings, code generation, or multimodal responses. All model execution and scaling are handled by OpenAI’s infrastructure.
From a system design perspective, the OpenAI API Gateway functions as a fully managed intelligence layer. Applications authenticate using API keys, submit input data such as text, images, or audio, and receive responses generated by OpenAI-hosted models. This approach removes the need for teams to manage inference infrastructure, capacity planning, or model lifecycle operations.
The gateway provides access to OpenAI’s latest models through a single, consistent interface, allowing product teams to ship AI-powered features quickly. As models improve, applications benefit without requiring retraining or redeployment. For many products, this makes the API Gateway an efficient way to add advanced AI capabilities without expanding the internal system surface area.
A representative example of this pattern is Indeed, which integrated OpenAI’s API to support features such as automated candidate outreach. By relying on a managed API rather than operating AI infrastructure in-house, the team could focus on product behavior and user outcomes, delegating reliability and scaling concerns to the platform.
How Requests Flow Through OpenAI API Gateway
Even though infrastructure is managed externally, the request flow still follows a clear layered pattern from the application’s perspective.
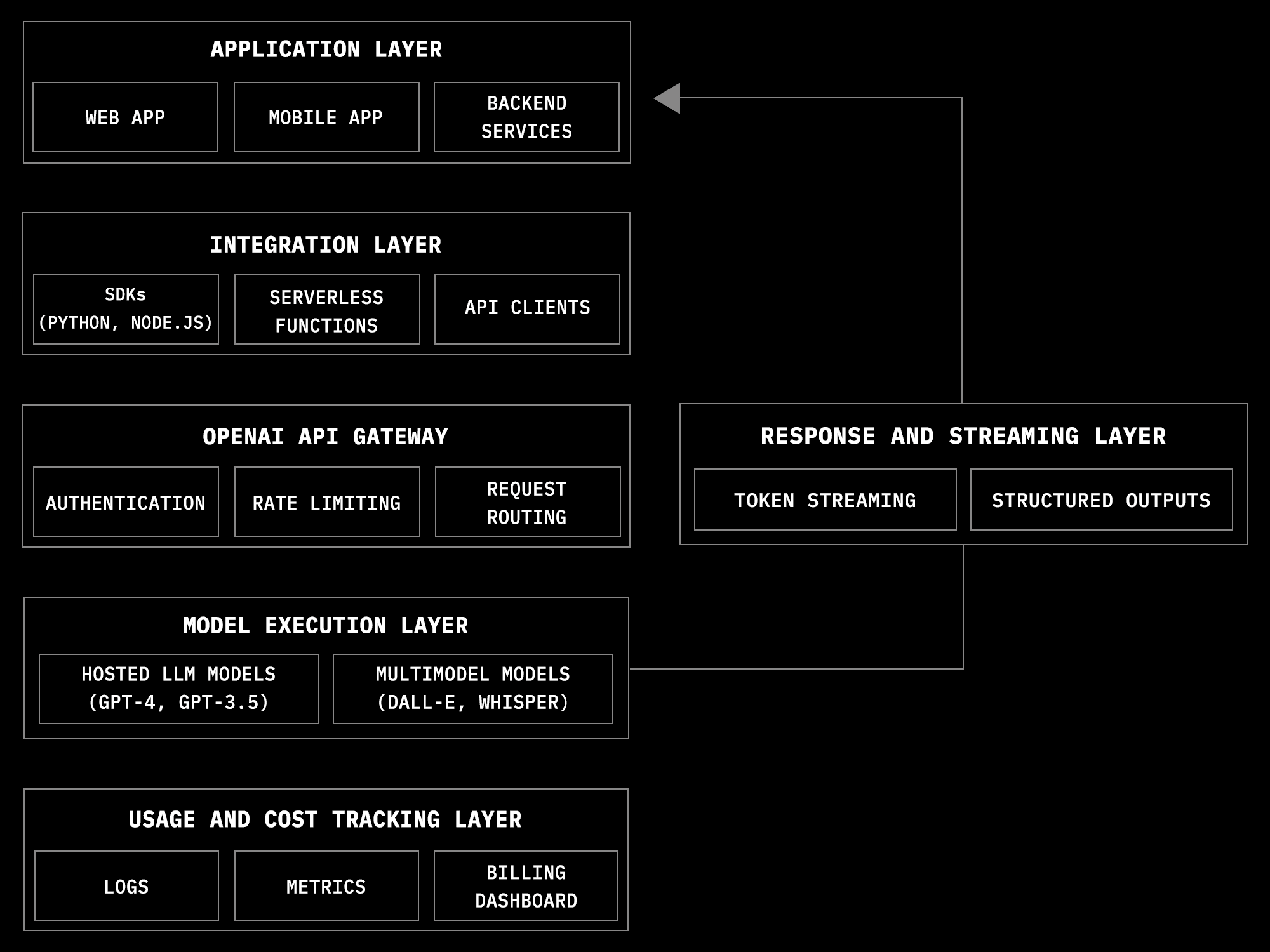
Application Layer
Web apps, mobile apps, and backend services generate prompts or structured inputs when AI features are triggered, such as summarizing text, generating responses, or creating embeddings.
Integration Layer
This includes SDKs, serverless handlers, or backend services that format requests, manage API keys, and apply application-specific logic like retries or response validation.
OpenAI API Gateway
Handles authentication, rate limiting, request routing, and policy enforcement before forwarding requests into OpenAI’s internal infrastructure.
Model Execution Layer
OpenAI’s hosted systems run the selected model version and perform inference at scale across distributed hardware.
Response and Streaming Layer
Generated tokens or structured outputs are streamed or returned to the application, where they are integrated into UI or business workflows.
Usage and Cost Tracking
Developers can monitor usage, latency, and billing through OpenAI-provided dashboards and logs, reducing the need for custom observability tooling.
This design allows product teams to focus on feature behavior and user experience while the AI platform provider manages scaling, reliability, and model lifecycle.
Key Capabilities of OpenAI API Gateway and What They Enable
The OpenAI API Gateway provides a managed way for teams to integrate advanced AI capabilities into production applications without operating their own infrastructure. Applications call OpenAI’s APIs from backend services or serverless functions, while model execution, scaling, and availability are handled by the platform.
This model works well when AI is treated as an external capability layer rather than a core system that must be deeply controlled or audited. The gateway exposes a set of capabilities that prioritize speed of adoption, operational simplicity, and access to the latest models.
These are the main capabilities that make OpenAI API Gateway attractive for product teams.
Key capabilities include:
Immediate Access to Advanced Models
Teams can use state-of-the-art language and multimodal models as soon as they are released, without training, hosting, or deployment work.Managed Scaling and Reliability
Request concurrency, traffic spikes, and throughput are handled by OpenAI’s infrastructure, reducing the need for capacity planning or custom autoscaling logic.Built-in Safety and Policy Enforcement
Content moderation, abuse prevention, and policy checks are applied at the API layer, simplifying compliance with usage guidelines.Support for Multimodal Workflows
The same API surface supports text, images, audio, embeddings, and structured outputs, enabling more complex application flows without multiple vendors.Usage and Cost Visibility
Token usage, latency, and billing data are available through dashboards and logs, allowing teams to monitor AI usage without building internal metering systems.
Taken together, these capabilities make the OpenAI API Gateway a strong fit for products where AI enhances user-facing features and rapid iteration matters more than deep control over execution or data handling.
OLLM vs OpenAI API Gateway: Side-by-Side Comparison
Once you understand how OLM and the OpenAI API Gateway work, the decision is less about infrastructure ownership and more about how AI requests are trusted, processed, and verified in production. Both platforms allow applications to access powerful external models via a simple API, but they differ fundamentally in the extent of visibility model providers have into application data.
The comparison below focuses on the dimensions that matter most when AI moves beyond experimentation and into sensitive, production-critical workflows.
Decision Area | OLLM (Confidential AI Gateway) | OpenAI API Gateway |
Primary Role | Confidential execution and verification layer | Managed access to OpenAI-hosted models |
Trust Boundary | Minimizes provider visibility using confidential execution | Provider is trusted to process prompts securely |
Prompt Visibility | Prompts are protected from plaintext exposure via TEEs | Prompts are visible within provider-controlled systems |
Execution Guarantees | Hardware-backed attestation verifies where and how inference runs | Execution guarantees are enforced through platform policy |
Provider Abstraction | Routes across multiple supported providers behind one API | Tied to OpenAI’s model ecosystem |
Integration Model | OpenAI-compatible API with additional privacy controls | Native OpenAI SDKs and APIs |
Operational Responsibility | Confidential execution enforcement and observability | Entire inference stack managed by OpenAI |
Compliance Posture | Designed for stricter confidentiality and audit requirements | Relies on provider compliance programs and contracts |
Iteration Speed | Fast integration with added privacy constraints | Fastest path to shipping AI features |
Best Fit Use Cases | Sensitive internal workflows, regulated environments, high-trust requirements | User-facing features, rapid experimentation, general SaaS workflows |
Conclusion
Both OLLM and the OpenAI API Gateway provide a practical way to use large language models in production, but they are built around different assumptions about trust and data exposure. The OpenAI API Gateway is a strong choice when AI is primarily used to enhance user-facing features and provider-managed execution is acceptable. It prioritizes ease of integration, rapid iteration, and operational simplicity.
OLLM addresses a different need. It is designed for production systems where AI operates on sensitive internal data and teams require stronger guarantees around confidentiality, execution, and auditability. By acting as a confidential gateway, OLLM allows teams to keep using external models while tightening the trust boundary. Choosing between the two ultimately comes down to how much visibility external providers should have into your data and what level of assurance your production workflows demand.
FAQ
1. What is OLLM and how is it different from a standard AI API gateway?
OLLM is a confidential AI gateway that routes application requests to external large language model providers while minimizing provider visibility into sensitive data. Unlike a standard AI API gateway, OLLM focuses on confidential execution, hardware-backed attestation, and verifiable privacy guarantees, making it suitable for production AI workloads that process sensitive or regulated data.
2. When should a company use OLLM instead of the OpenAI API Gateway?
OLLM is best suited for production environments where AI interacts with sensitive internal data such as HR records, legal documents, financial information, or proprietary business context. Teams typically choose OLLM when they need stronger confidentiality guarantees and tighter trust boundaries than those offered by standard managed AI APIs, while still relying on external models.
3. What is the OpenAI API Gateway used for in production applications?
The OpenAI API Gateway is used to integrate OpenAI’s language and multimodal models into applications through a managed API. It enables teams to add features like text generation, summarization, embeddings, and multimodal workflows without managing model infrastructure, scaling, or inference reliability themselves.
4. Is OLLM a self-hosted or on-premise LLM solution?
No. OLLM does not host or run models on customer infrastructure. It operates as a gateway layer that routes requests to external model providers using confidential computing techniques. The key difference is not where models run, but how data is protected and verified during execution.
5. How should teams choose between a confidential AI gateway and a managed AI API?
The choice depends on data sensitivity and trust requirements. Managed AI APIs like the OpenAI API Gateway work well for user-facing features and rapid experimentation. Confidential AI gateways like OLLM are better suited for regulated or high-sensitivity workflows where minimizing data exposure and ensuring verifiable execution are critical production requirements.
"/><stop offset="1" stop-color="rgb(80, 78, 87)"/></linearGradient></defs><g d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z M 142.346 0.381 L 162 0.381 L 162 20 L 142.346 20 Z M 153.986 8.381 L 158.375 8.381 L 158.375 12 L 153.986 12 L 153.986 16.571 L 150.36 16.571 L 150.36 12 L 145.972 12 L 145.972 8.381 L 150.36 8.381 L 150.36 4.19 L 153.986 4.19 Z" fill="transparent" height="20px" id="cWM2PbaAz" width="162.00000833847133px"><path d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z" fill="url(%23UyELkL66Q-1582027827-linear-gradient)" height="20px" id="UyELkL66Q" width="134.52277004415487px"/><path d="M 0 0 L 19.654 0 L 19.654 19.619 L 0 19.619 Z" fill="rgb(176, 0, 0)" height="19.618991595424752px" id="t30DbKa7C" transform="translate(142.346 0.381)" width="19.653710120697895px"/><path d="M 8.014 4.19 L 12.403 4.19 L 12.403 7.81 L 8.014 7.81 L 8.014 12.381 L 4.389 12.381 L 4.389 7.81 L 0 7.81 L 0 4.19 L 4.389 4.19 L 4.389 0 L 8.014 0 Z" fill="rgb(255, 255, 255)" height="12.380917026238919px" id="bLcZkJmGc" transform="translate(145.972 4.19)" width="12.402826775197639px"/></g></svg>)