|

TL;DR
Direct model-specific integrations fragment architecture across providers, increasing code complexity, schema adapters, billing silos, compliance reviews, and the outage blast radius as LLM usage scales.
An AI gateway centralizes routing, authentication, rate limiting, observability, and cost tracking behind a single API, reducing integration sprawl while improving operational visibility and control across providers.
OLLM defaults to not persistently storing prompt or response content, minimizing historical inference exposure and reducing the scope of breach impact (metadata logging and prompt storage can be configured explicitly when required).
Hardware-backed Trusted Execution Environments with Intel TDX and NVIDIA GPU attestation provide cryptographic evidence of enclave and VM identity and integrity, strengthening runtime isolation guarantees beyond contractual assurances.
Scaling with OLLM occurs at the gateway layer through centralized quota enforcement, rate-limit-aware routing, load balancing, and multi-provider failover, reducing rate-limit friction and limiting provider outage blast radius without requiring application rewrites.
Artificial intelligence has moved from isolated experiments to production infrastructure. Enterprises now run customer support automation, internal copilots, data analysis pipelines, and agent workflows directly on large language models. At this stage, model access is no longer a prototype decision. It becomes an architectural decision.
Architecture determines how systems scale, how security is enforced, and how compliance is verified. Teams typically choose between direct, model-specific integrations or an AI gateway that aggregates and secures multiple providers behind a single API. Each approach carries tradeoffs in complexity, flexibility, and risk.
This comparison examines the trade-offs in detail, focusing on how OLLM approaches enterprise security, zero data retention, and verifiable runtime isolation.
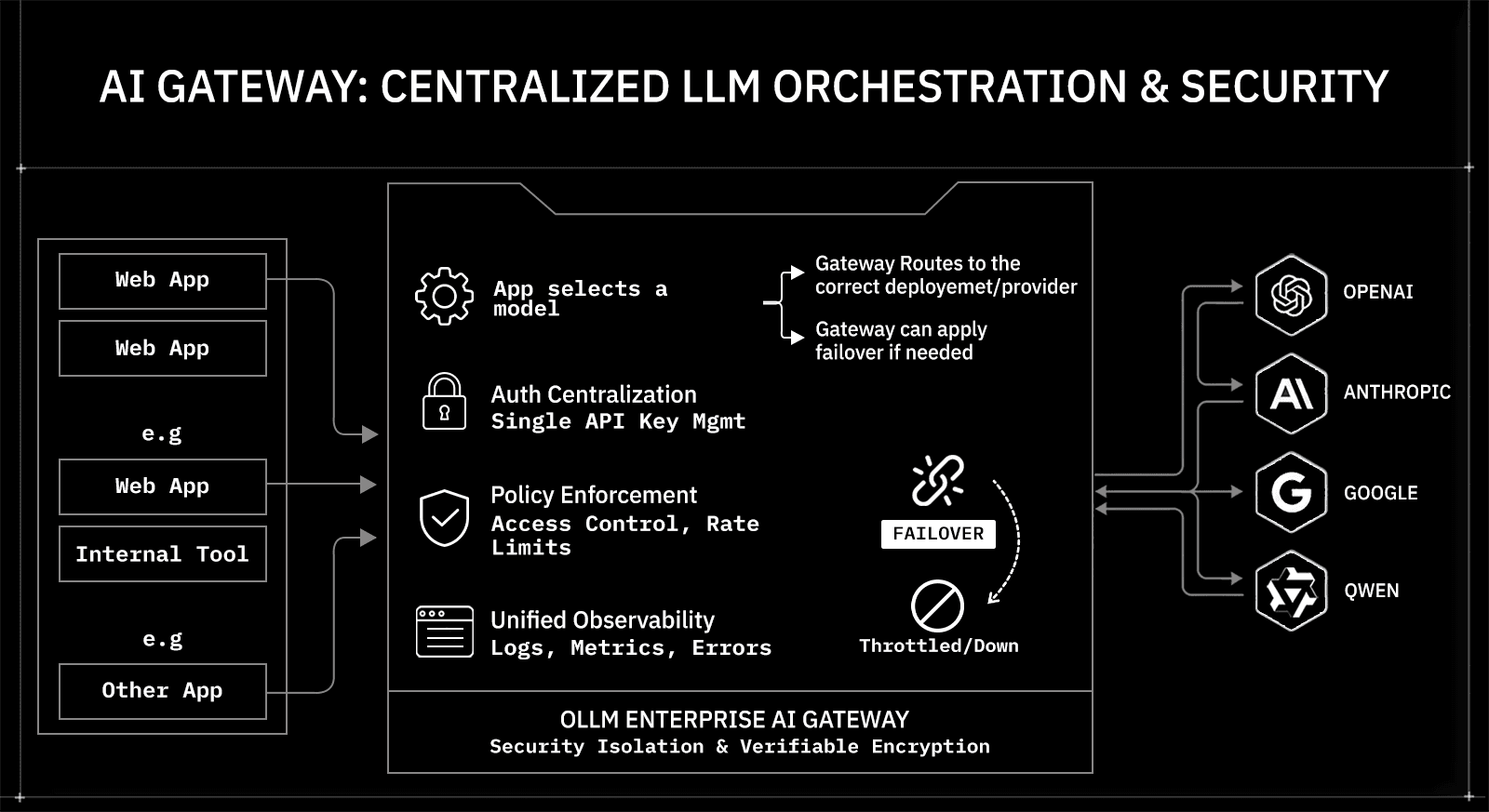
What Is an AI Gateway and How Does It Work?
An AI gateway sits between enterprise applications and multiple large language model providers, like GPT-class APIs, Claude-class APIs, open-weight models, and domain-tuned private deployments. It provides a unified API layer that routes inference requests, enforces security controls, and manages interactions with providers through a single endpoint. Instead of wiring each application directly to a specific model vendor, services call the gateway, which handles all the requests.
In production systems, this architecture supports concrete use cases:
Customer support automation: Route high-volume chat queries to a cost-optimized model, while escalating sensitive billing disputes to a higher-accuracy model with stricter isolation controls.
Internal copilots for engineering or legal teams: Restrict certain departments to approved models and prevent prompt data from reaching non-compliant providers.
Document processing pipelines: Send summarization workloads to a fast inference model while routing contract analysis to a model configured for longer context windows.
AI agent workflows: Select model aliases in the application (or via policy-configured routing groups), while the gateway enforces execution policies, such as fallback, load balancing, and rate limiting.
High-availability SaaS APIs: Automatically reroute traffic if a provider experiences rate limiting, regional degradation, or API outages.
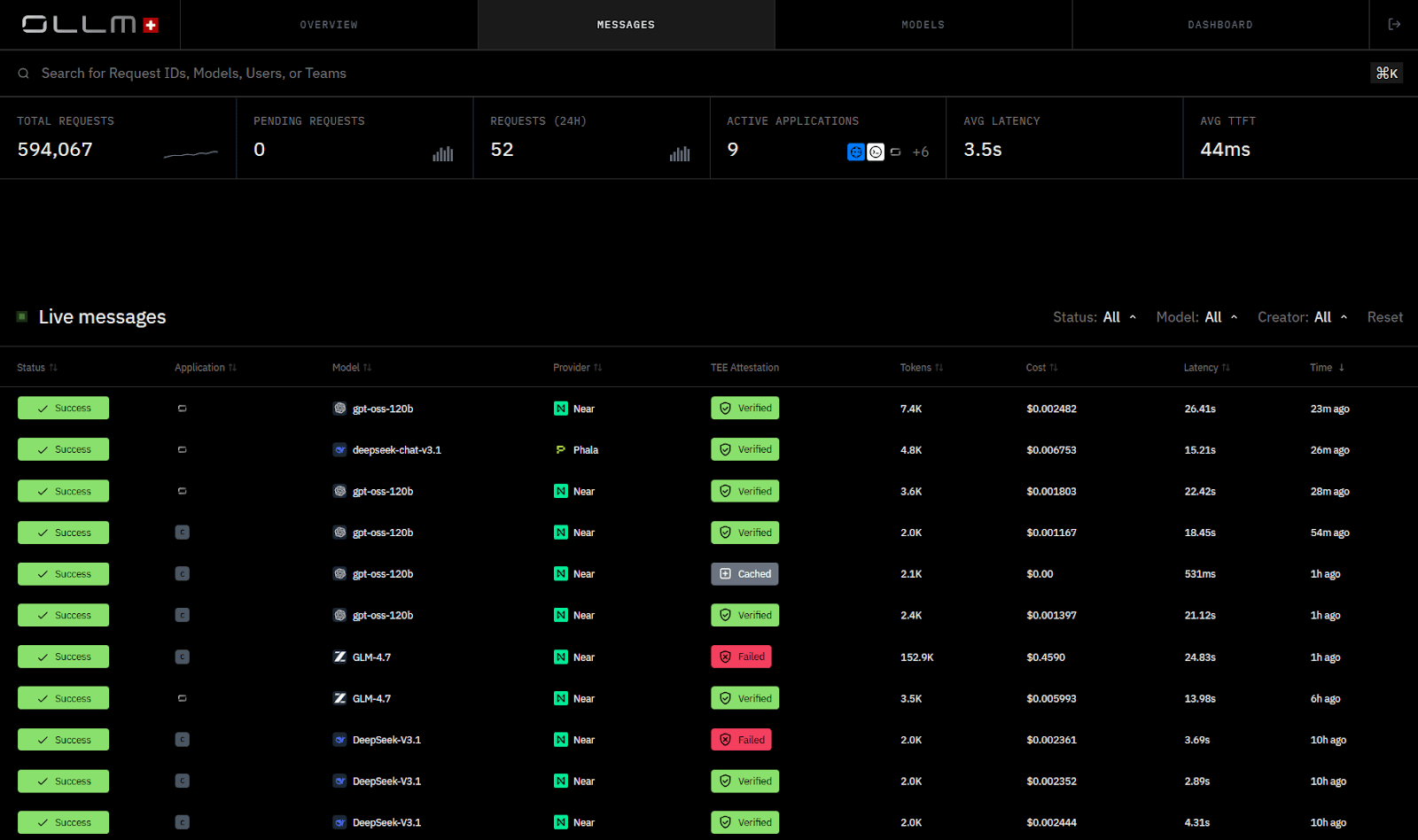
The gateway centralizes cross-provider concerns that would otherwise live inside application code. Credential management, routing policies, usage limits, observability, and failover logic operate within a single control layer rather than being replicated across services.
OLLM implements this pattern as an enterprise AI gateway with a strong emphasis on isolation and privacy. It aggregates high-security LLM providers behind a single API with privacy-preserving defaults and TEE-backed execution paths for supported providers and models. Retention and logging behavior are enforced through configuration controls.
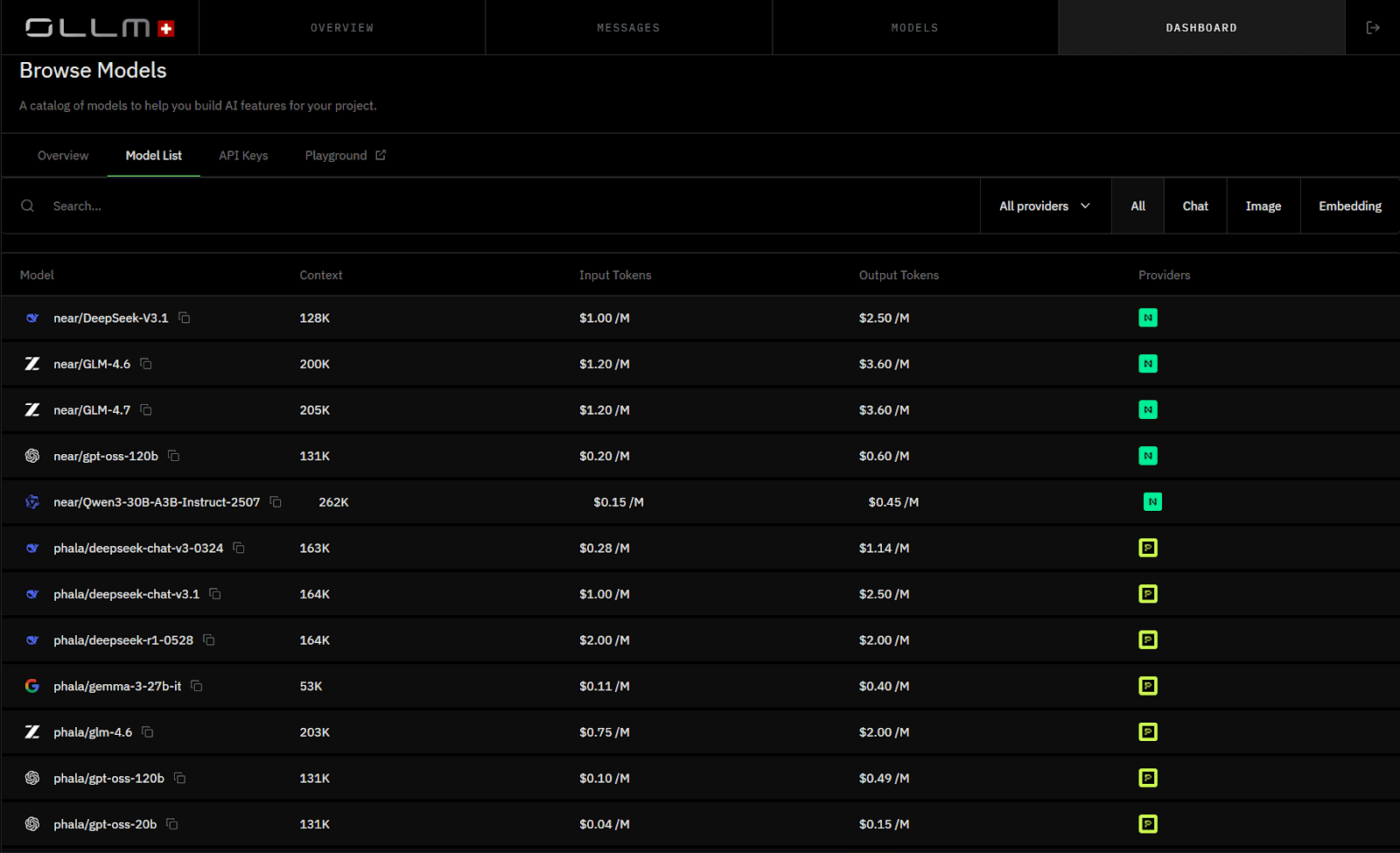
It routes requests to providers and model deployments that support confidential compute and attestation (for example, NEAR- or Phala-backed execution paths), while OLLM itself defaults to not persisting prompt or response content. Retention and logging behavior are governed through configuration controls.
How Model-Specific Integrations Work in Enterprise Production Environments
Direct model integrations connect a specific application to a specific LLM provider. For example, a customer support backend may call a GPT-class API for chat responses, a legal-tech platform may integrate directly with a Claude-class model for contract review, or a fintech analytics engine may use an open-weight deployment for transaction summarization. Engineers use the provider’s SDK or REST API, store credentials in backend services, and call the model endpoint from application logic.
A production system is a model that handles live user traffic, revenue-impacting workflows, or regulated data. Examples include:
A SaaS helpdesk responding to thousands of chats per hour
An HR platform screening resumes in real time
A healthcare application summarizing patient notes
A developer platform exposing AI capabilities through a public API
In these environments, the integration typically looks like this:
The application service calls Provider A’s API directly.
Authentication uses Provider A’s API keys or OAuth credentials.
Rate limits and quotas apply per provider account.
Logs, token usage, and latency metrics live in provider dashboards or custom monitoring systems.
When a second provider is introduced for cost optimization, latency improvements, or redundancy, the pattern is duplicated. Routing logic moves into application code. Engineering teams introduce conditionals such as if provider == X. Model switching requires configuration changes or refactoring. Failover logic must be built internally.
Most providers today expose OpenAI-style APIs, which makes initial integration straightforward. For example:
from openai import OpenAI |
The surface looks consistent. The complexity emerges when multiple providers are introduced behind similar interfaces.
API inconsistencies compound over time. Providers differ in streaming formats, function-calling schemas, token accounting rules, context window limits, and error structures. Engineering teams introduce adapters, normalization layers, and provider-specific retry logic to reconcile these differences.
Operational complexity extends beyond code. Billing becomes fragmented across vendors with separate invoices, pricing models, and usage dashboards. Cost spikes in one workload may not be visible when monitoring is siloed. Budget forecasting becomes harder as usage scales across providers.
Security and compliance reviews multiply as well. Each provider introduces different retention defaults, encryption guarantees, and isolation controls. Audit and vendor risk assessments expand with every additional integration.
The architecture works. However, as additional providers are added, operational responsibility spreads across engineering, finance, compliance, and reliability teams. Complexity grows not because the system breaks, but because control is distributed across multiple external dependencies.
Architectural Differences Between Direct Integrations and an AI Gateway
Architecture determines how complexity accumulates over time. The impact becomes visible when a single application begins using multiple models for different workloads.
Consider a SaaS platform that runs:
Customer support chat on one model
Resume scoring on another model
Contract summarization on a third model
With direct integrations, each workload embeds provider-specific logic inside its service. The support service implements streaming handling for Provider A. The HR service normalizes token limits for Provider B. The legal workflow implements custom retry logic for Provider C. Routing, credential management, fallback behavior, and rate-limit handling are implemented in separate codebases.
As additional providers are introduced for cost control or redundancy, the integration surface expands. Engineering teams maintain multiple SDKs, reconcile responses across different formats, and duplicate retry logic across services.
An AI gateway centralizes these responsibilities into a dedicated control plane. Customer support, resume scoring, and contract analysis services all send standardized requests to a single endpoint. The gateway executes policy for the selected model alias, resolving it to a configured deployment and applying load balancing, rate-limit-aware routing, and failover logic based on defined policies. The application code remains focused on business functionality rather than on provider coordination.
The architectural difference becomes clearer as workloads scale. Direct integrations distribute operational logic across services. A gateway consolidates it into one layer.
The comparison below highlights structural differences.
Category | Model-Specific Integrations | AI Gateway (OLLM) |
API Surface | Multiple SDKs and endpoints | Single unified API |
Vendor Lock-in | Migration requires refactoring and contract renegotiation | Provider switching is handled at the code level |
Model Switching | Code or config changes per provider | Only model specified changes in code/config |
Authentication | Separate credentials per vendor | Centralized credential management |
Rate Limits | Managed per provider account | Unified quota and policy control |
Failover | Implemented in the application logic | Built into the routing layer |
Observability | Provider dashboards + custom logs | Aggregated visibility across providers |
Operational overhead grows with each direct integration. A gateway reduces overhead by consolidating routing, authentication, and enforcement into a single layer. This consolidation does not remove provider dependencies, but it isolates them from application logic and reduces long-term maintenance complexity.
Operational consolidation is only one dimension of the difference. As LLM workloads begin processing regulated, confidential, or customer-sensitive data, architectural design directly affects security exposure. The next distinction moves from integration complexity to data risk: how inference data is handled during and after execution.
Zero Data Retention and Why It Changes the Risk Model
Data retention defines the blast radius of a security incident. If prompts and responses are stored, they become retrievable assets. If they are not stored, there is no historical dataset to extract.
OLLM operates with zero data retention. The gateway does not persist prompt or response data in logs, databases, or internal storage layers. After a request completes, no prompts or outputs remain stored in the system. There is no history of inferences and no retrievable conversation archive.
This approach differs from policies that state “we do not train on your data.” Training restrictions address model improvement. Retention policies address storage risk. Zero retention eliminates a data pool that could be queried, leaked, or subpoenaed.
For regulated environments, this changes the compliance posture:
No prompt database to secure.
No historical response logs to protect.
No internal data lake containing sensitive inference content.
Reduced the impact scope in breach scenarios.
Zero retention does not replace encryption or runtime isolation. It complements them. Encryption protects data in transit and at rest. Zero retention removes all exposure to long-term storage entirely.
Trusted Execution Environments and Cryptographic Attestation Explained
Runtime isolation determines who can access data during inference. Even if data is encrypted in transit and not retained after execution, it must exist in plaintext in memory while the model processes it. Trusted Execution Environments address that exposure window.
A Trusted Execution Environment (TEE) isolates code and data at the hardware level. The processor creates a protected enclave in which memory remains inaccessible to the host operating system, the hypervisor, and cloud administrators. Only verified code can execute inside that enclave.
OLLM incorporates hardware-backed TEEs and provides cryptographic attestation proofs of secure execution. These proofs verify that:
The workload ran inside a genuine TEE.
The enclave was not modified.
The expected code and configuration were loaded.
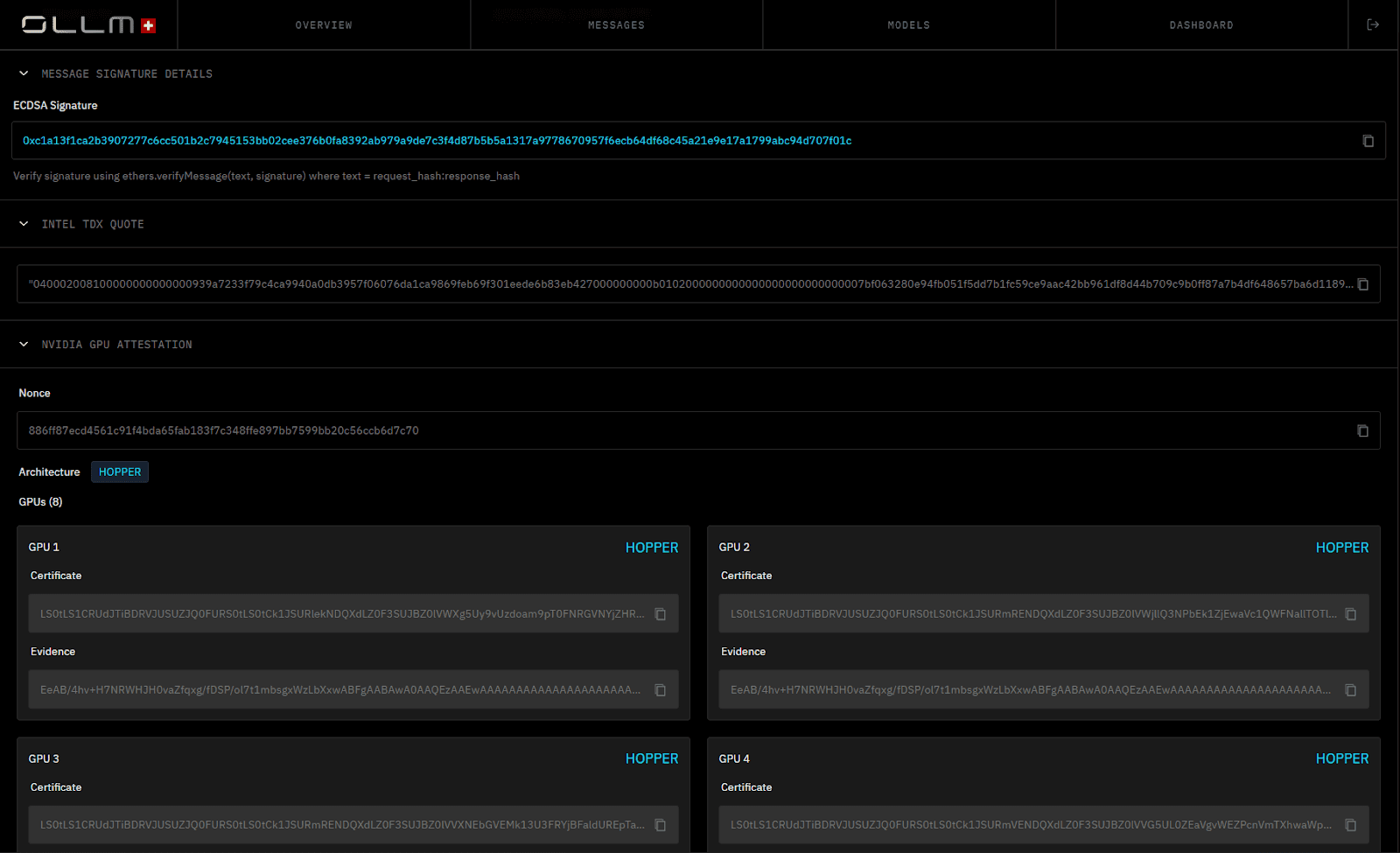
OLLM supports attestation mechanisms such as:
Intel TDX attestation, which validates secure virtual machine isolation at the CPU level.
NVIDIA GPU attestation, which verifies secure execution when GPU acceleration is involved.
Cryptographic attestation shifts compliance from contractual assurance to verifiable evidence. Instead of relying solely on vendor statements, teams can validate that inference occurred inside a hardware-isolated environment. This approach strengthens the audit posture and reduces reliance on trust assumptions at the infrastructure layer.
How Does an AI Gateway Reshape Infrastructure-Level Compliance?
Security architecture differs significantly between direct integrations and a hardened AI gateway. The difference is not only in encryption. It appears in retention policies, runtime isolation, and verifiability.
Direct integrations depend on each provider’s infrastructure controls. Some providers offer strong encryption and isolation. Others vary in retention defaults, logging practices, and hardware isolation guarantees. Compliance teams must review each provider independently.
An enterprise AI gateway, such as OLLM, standardizes these controls at a single enforcement layer. Zero data retention, hardware-backed isolation, and cryptographic attestation operate consistently across routed providers.
The comparison below highlights infrastructure-level differences.
Security Layer | Model-Specific Integrations | OLLM Gateway |
Data Retention | Provider-dependent policies | Zero data retention |
Prompt Storage | May log or retain by default | No persistent prompt storage |
Encryption | Typically in transit and at rest | Encryption at every layer |
Runtime Isolation | Varies by vendor | TEE-backed execution |
Attestation Proofs | Rarely exposed to customers | Cryptographic TEE attestation |
Compliance Verification | Contractual assurance | Verifiable hardware-backed proof |
Infrastructure standardization reduces audit complexity. Instead of validating controls across multiple vendors, organizations validate the gateway’s enforced posture. This reduces compliance surface area and creates a consistent security baseline across model providers.
How OLLM Scales Enterprise LLM Workloads Without Application Changes
Scaling LLM workloads requires both capacity flexibility and stable rate limits. Direct integrations scale per provider account. Each vendor enforces independent quotas, burst limits, and throttling rules. As usage grows, teams must either negotiate capacity separately or refactor the traffic distribution logic.
OLLM centralizes scaling through its gateway layer. Applications continue to call a single API, while capacity adjustments occur behind the abstraction layer. Scaling typically involves:
Loading additional credits to expand usage capacity.
Reserving dedicated capacity through sales agreements for predictable high-volume workloads.
Configuring routing rules to distribute traffic across multiple providers.
Leveraging multi-model failover to prevent downtime during provider throttling.
Centralized quota management simplifies forecasting. Instead of tracking limits across multiple vendor dashboards, usage and capacity are managed within a single control plane. If traffic approaches predefined thresholds, routing can shift to alternative providers without application-level rewrites.
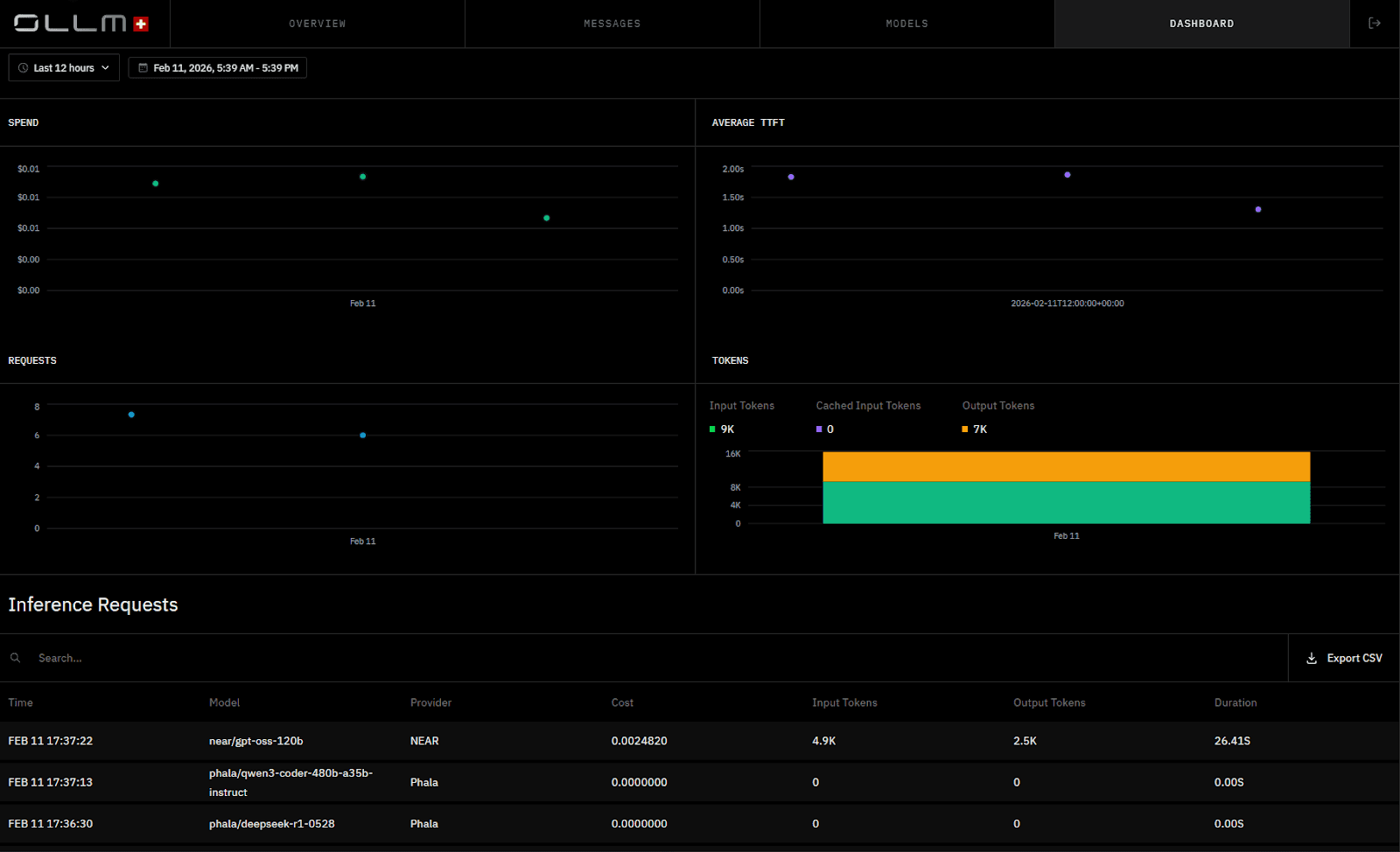
Centralized billing simplifies financial oversight. Instead of reconciling multiple provider invoices and dashboards, usage and spend are tracked through a single gateway layer. This improves budget forecasting and reduces the risk of unnoticed cost spikes across distributed model integrations.
A single-provider integration increases the blast radius of outages. If that provider experiences downtime or regional degradation, application availability depends entirely on that vendor’s infrastructure. A gateway-based architecture can reroute traffic across alternative providers to reduce outage exposure and maintain service continuity without modifying application code.
This architecture reduces operational friction caused by rate limit spikes and sudden demand increases. Scaling becomes a capacity configuration decision rather than a code change.
Engineering Overhead and Maintenance Costs in Multi-Provider LLM Integrations
Engineering overhead increases as the number of SDK integrations grows, with one for each model provider. Each model-specific integration introduces new SDK dependencies, authentication flows, logging pipelines, and rate-limit handling logic. Over time, these responsibilities expand beyond the initial implementation effort.
Direct integrations typically require:
Maintaining multiple SDK versions.
Updating provider-specific API changes.
Revalidating compliance posture per vendor.
Correlating request logs across multiple provider dashboards.
Tracing failed requests when routing logic spans vendors.
Aggregating audit trails during security investigations.
Implementing custom failover and retry logic.
Managing separate monitoring and alerting rules.
When incidents occur, distributed logging across providers complicates root cause analysis and slows response times.
This fragmentation also increases maintenance costs. Security reviews must examine each provider independently. Incident response must determine whether issues originate in application logic or a specific vendor integration.
An AI gateway shifts these responsibilities into a centralized layer. Application services interact with one API. Provider changes remain isolated within the gateway. Security controls and routing policies remain consistent across providers.
Long-term, the tradeoff becomes clear. Direct integrations may appear simpler initially. At scale, centralized abstraction reduces repetitive integration work, limits compliance surface area, and isolates provider-specific changes from business logic.
Choosing the Right Architecture for Enterprise AI Deployments
The choice of architecture depends on workload sensitivity, scale, and operational constraints. Direct integrations can work well for single-provider use cases with low regulatory exposure. A small team integrating a single model into a contained application may not require additional abstraction layers.
Direct integrations are typically suitable when:
Only one provider is used.
Data sensitivity is low.
Compliance requirements are minimal.
Model switching is unlikely.
Scaling needs are predictable and modest.
An AI gateway becomes more relevant as complexity increases. Multi-provider strategies, regulated data handling, and enterprise audit requirements introduce coordination overhead that benefits from centralization.
An AI gateway such as OLLM is more appropriate when:
Multiple LLM providers are required.
Sensitive or regulated data is processed.
Zero data retention is a requirement.
Verifiable runtime isolation is needed.
Capacity must scale without application rewrites.
The distinction is architectural rather than promotional. Direct integrations prioritize simplicity at a small scale. As deployments expand, an enterprise AI gateway prioritizes centralized control, verifiable security, and operational consistency.
Conclusion: Architectural Control Determines Long-Term Security and Flexibility
Architectural choices shape how AI systems behave at scale, under regulatory pressure, and under operational pressure. Direct model integrations provide speed for narrow use cases, but they distribute security, routing, and compliance responsibilities across multiple vendors. An AI gateway centralizes those responsibilities into a dedicated control plane. OLLM extends that model further by supporting zero data retention, hardware-backed Trusted Execution Environments, Intel TDX, NVIDIA GPU attestation, and cryptographic proof of secure execution. The difference is not only consolidation. The difference is verifiable isolation and reduced data exposure.
Teams evaluating LLM infrastructure should assess more than latency and cost. Evaluate data retention posture, runtime isolation guarantees, attestation capabilities, and scaling mechanics. If enterprise workloads require verifiable privacy, centralized policy enforcement, and flexible multi-provider routing, an AI gateway approach warrants serious consideration. Reviewing your current integration surface and compliance assumptions is the logical next step before further production usage expands.
FAQ
1. What is the difference between an AI gateway and direct LLM API integration?
An AI gateway abstracts multiple large language model providers behind a single API and centralized control plane. Direct LLM API integration connects an application to one provider’s SDK or endpoint. The key differences appear in routing flexibility, rate limit management, security enforcement, observability, and vendor lock-in. An AI gateway reduces integration sprawl and centralizes policy enforcement across providers.
2. How does zero data retention improve LLM security and compliance posture?
Zero data retention eliminates persistent storage of prompts and responses after inference completes. Without stored prompt logs or response databases, there is no retrievable historical dataset to exfiltrate or subpoena. This materially reduces the scope of breach impact and simplifies compliance audits in regulated environments such as healthcare, finance, and government deployments.
3. What are Trusted Execution Environments (TEE) and how do cryptographic attestation proofs work?
A Trusted Execution Environment isolates workloads at the hardware level using secure enclaves. During inference, the model runs in protected memory, inaccessible to the host operating system or cloud administrators. Cryptographic attestation generates verifiable proofs that confirm the enclave’s integrity, code identity, and configuration. These proofs enable enterprises to validate runtime isolation without relying solely on vendor assurances.
4. How does OLLM implement Intel TDX and NVIDIA GPU attestation for secure AI inference?
OLLM leverages hardware-backed isolation mechanisms such as Intel TDX for secure virtual machine isolation and NVIDIA GPU attestation for protected accelerator execution. The platform provides cryptographic attestation proofs that verify inference workloads executed inside genuine, untampered TEEs. This enables verifiable privacy guarantees across CPU and GPU-based LLM workloads.
5. How does OLLM scale LLM workloads without hitting provider rate limits?
OLLM centralizes quota management and routing across aggregated LLM providers. Scaling can be handled by loading additional credits, reserving dedicated capacity, or distributing traffic across multiple models through routing policies. Multi-provider failover reduces dependency on a single vendor’s rate limits, enabling consistent throughput without requiring application-level refactoring.
"/><stop offset="1" stop-color="rgb(80, 78, 87)"/></linearGradient></defs><g d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z M 142.346 0.381 L 162 0.381 L 162 20 L 142.346 20 Z M 153.986 8.381 L 158.375 8.381 L 158.375 12 L 153.986 12 L 153.986 16.571 L 150.36 16.571 L 150.36 12 L 145.972 12 L 145.972 8.381 L 150.36 8.381 L 150.36 4.19 L 153.986 4.19 Z" fill="transparent" height="20px" id="cWM2PbaAz" width="162.00000833847133px"><path d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z" fill="url(%23UyELkL66Q-1582027827-linear-gradient)" height="20px" id="UyELkL66Q" width="134.52277004415487px"/><path d="M 0 0 L 19.654 0 L 19.654 19.619 L 0 19.619 Z" fill="rgb(176, 0, 0)" height="19.618991595424752px" id="t30DbKa7C" transform="translate(142.346 0.381)" width="19.653710120697895px"/><path d="M 8.014 4.19 L 12.403 4.19 L 12.403 7.81 L 8.014 7.81 L 8.014 12.381 L 4.389 12.381 L 4.389 7.81 L 0 7.81 L 0 4.19 L 4.389 4.19 L 4.389 0 L 8.014 0 Z" fill="rgb(255, 255, 255)" height="12.380917026238919px" id="bLcZkJmGc" transform="translate(145.972 4.19)" width="12.402826775197639px"/></g></svg>)