|

TLDR
AI gateways increasingly function as core infrastructure as systems scale, centralizing security, access control, observability, and cost governance once teams use multiple models and environments.
The build vs buy decision is about ownership, not capability: building shifts cost, maintenance, and risk to internal teams, while buying offloads operational responsibility.
In-house gateways incur hidden long-term costs, including platform engineering, security reviews, audits, on-call operations, and continuous upgrades as models evolve.
Managed gateways reduce time-to-market and operational drag, offering OpenAI-compatible APIs, predictable usage-based spend, and production-ready security defaults.
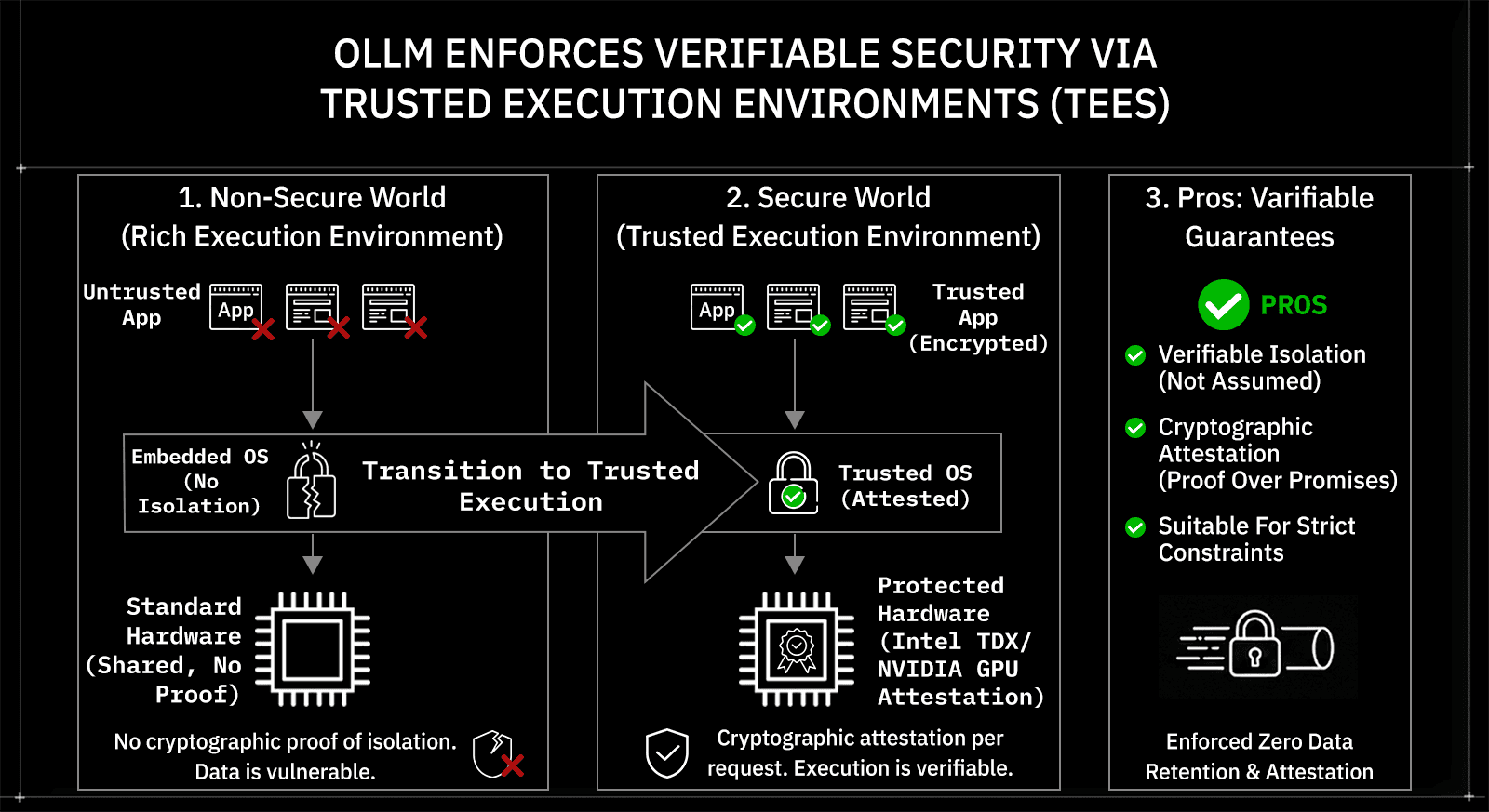
OLLM focuses on verifiable security, running models in TEEs with Intel TDX and NVIDIA GPU attestation, enabling per-request encryption verification and enforcing zero data retention.
AI gateways act as a centralized control layer between applications and models
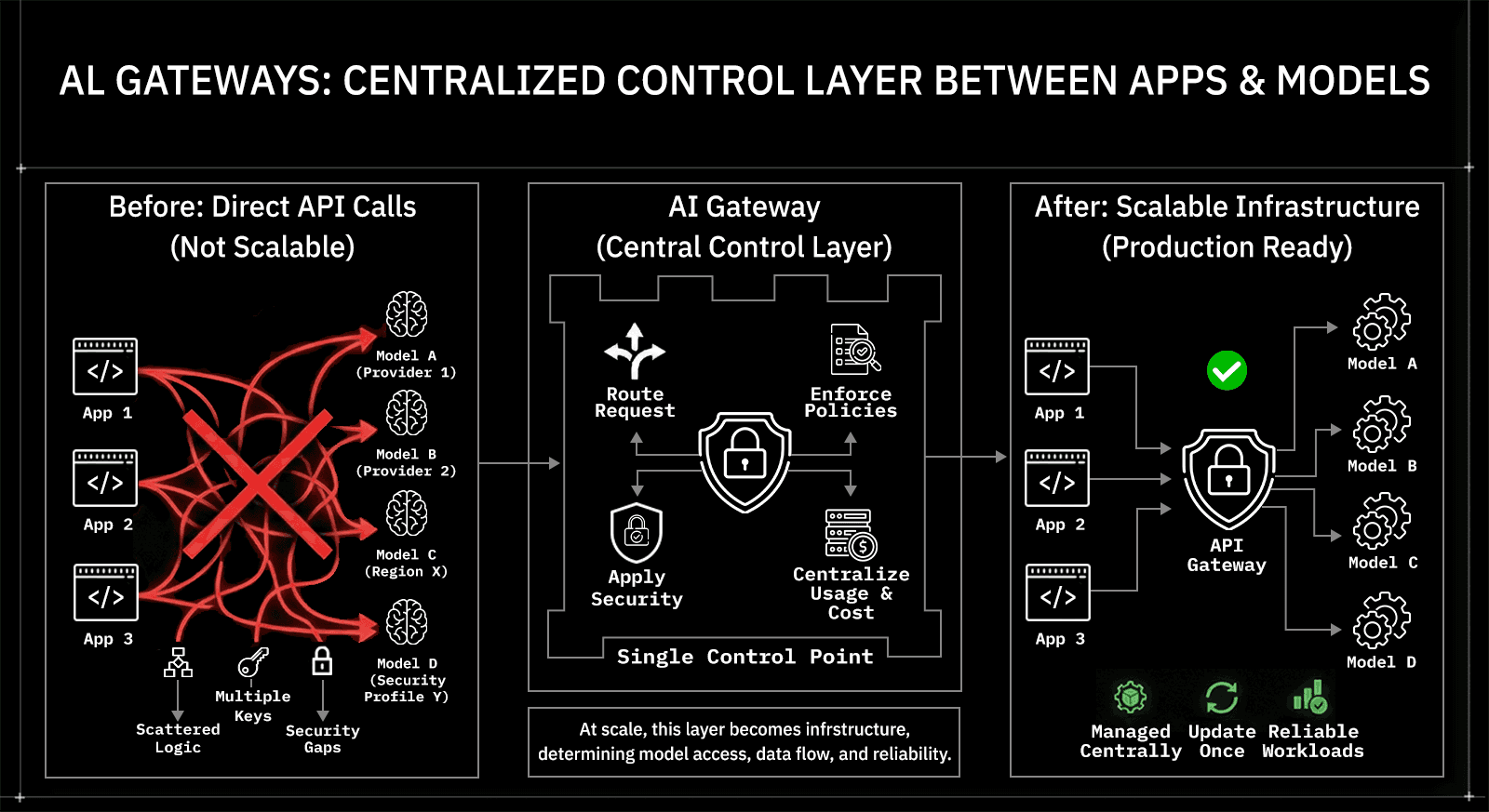
AI gateways sit between applications and language models to centralize control. As teams expand from a single model to multiple providers, regions, and security profiles, direct model API calls no longer scale. Routing logic spreads across services. API keys multiply. Logging and cost tracking become inconsistent. Security assumptions vary from one team to another.
AI gateways consolidate these responsibilities into a single control layer. They act as a centralized access layer where applications explicitly select models, while the gateway enforces access policies, security constraints, and usage controls. Instead of embedding this logic into every application, teams manage it centrally and update it once.
At scale, this layer becomes infrastructure rather than tooling. It determines how models are accessed, how data flows through AI systems, and how reliably AI workloads behave in production.
The decision comes down to who owns cost, time, and operational risk
Choosing between building an AI gateway and using an existing one is primarily an ownership decision. Both approaches can handle requests and connect to models. The difference lies in who bears the ongoing costs, how quickly teams reach production, and where operational risk sits as usage scales.
Building an internal gateway shifts ownership inward. Engineering teams own development timelines, infrastructure provisioning, security controls, incident response, and long-term maintenance. This can make sense when infrastructure itself is a competitive advantage, but it also turns the gateway into a permanent platform commitment rather than a one-time build.
Buying a gateway shifts that ownership outward. Time to production shortens, operational responsibilities move to the vendor, and teams adopt a predefined security and governance model. The trade-off is reduced flexibility at the deepest layers and reliance on vendor guarantees.
Across teams, three variables consistently drive the decision:
Time to production, including security and audit readiness
Total cost of ownership, not just initial build cost
Risk exposure, especially around data handling and compliance
Building an AI gateway internally increases control but slows delivery
Building an in-house AI gateway gives teams full control over architecture and behavior. Routing logic, security boundaries, logging, and integrations can be tailored to internal systems and policies. For organizations with highly specialized workflows or established platform teams, this level of control can align with broader infrastructure strategy.
That control comes with high delivery and maintenance costs. A production-ready gateway requires more than request routing. Teams must design authentication, key management, logging, monitoring, failure handling, and upgrade paths as models and providers change. Security reviews, compliance requirements, and internal audits further extend timelines before real workloads can ship.
Building an internal gateway can also make sense in narrower cases, such as serving proprietary or custom-trained models. When models are trained in-house or tightly coupled to internal data pipelines, integrating them directly into a self-managed gateway may be required. In these cases, the gateway becomes part of the model lifecycle rather than a shared access layer.
Over time, the gateway becomes a system that must evolve continuously. Each new model, provider change, or security requirement introduces additional engineering work. For most teams, this slows product delivery and diverts attention from building AI-driven features that users actually interact with.
Buying an AI gateway shifts complexity into a managed control plane
Buying an AI gateway replaces custom infrastructure with a pre-built control layer. Instead of implementing routing, access control, observability, and guardrails from scratch, teams adopt a system that already includes these capabilities and is designed to work together. This reduces the surface area that application teams need to own.
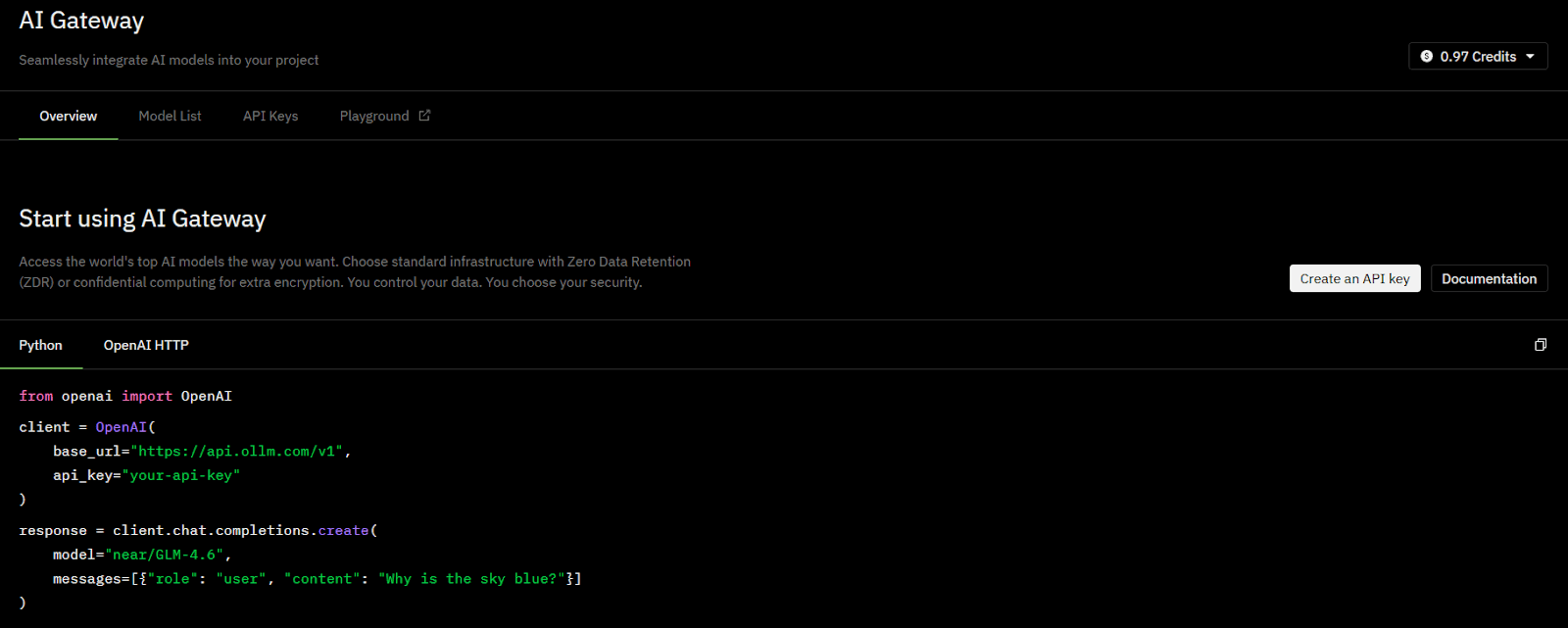
Most AI gateways, including OLLM, expose an OpenAI-compatible API surface. This allows teams to switch providers by updating the endpoint and credentials while keeping the rest of the application code unchanged. For production systems, this compatibility reduces migration risk and avoids deep refactoring when models or providers change.
The primary advantage is speed with operational consistency. Gateways built for production environments can be deployed quickly and include opinionated defaults for security, logging, and governance. Applications continue to explicitly specify models, while the gateway abstracts security, access, and operational concerns
The trade-off is reduced depth of customization. While most gateways expose configuration and APIs, they rarely allow teams to redefine the entire execution model. For many organizations, this is acceptable because the gateway is not where differentiation lives. It becomes shared infrastructure that prioritizes reliability, predictability, and lower operational burden over bespoke design.
Cost differences appear once gateways support real production workloads
Prototype costs are misleading. Early in-house gateways can appear inexpensive when they handle only a small volume of requests. The real cost difference appears once the gateway supports multiple teams, production SLAs, and security and compliance requirements.
Internal gateways accumulate cost through people and operations, not just infrastructure. As usage grows, teams must staff and maintain the gateway as a permanent platform:
Where in-house gateway costs actually come from
Engineering ownership: platform engineers for routing logic, provider adapters, authentication, retries, and failover
Security work: key management, encryption handling, internal reviews, and incident response
Operational overhead: monitoring, on-call rotation, upgrades as models and APIs change
Compliance effort: evidence collection, audit preparation, and recurring security assessments
These costs scale with organizational size and usage, not just request volume.
Managed gateways convert variable effort into predictable spend. Subscription pricing replaces ongoing platform engineering work, while maintenance, provider changes, and security hardening are handled centrally. This shifts the cost from continuous engineering effort to a more stable operating expense.
With OLLM, teams do not incur separate infrastructure or platform engineering costs for running the gateway itself. There is no need to provision or maintain gateway infrastructure, security tooling, or on-call coverage for the control plane. Spend is tied to model and token usage rather than upfront gateway development, ongoing platform maintenance, or hidden operational overhead.
Cost Dimension | Build In-House | Managed Gateway |
Upfront spend | Low to moderate | Low |
Ongoing effort | High, people-driven | Low, vendor-driven |
Cost predictability | Low | High |
Scale impact | Increases with teams | Mostly usage-based |
Security and compliance risks concentrate at the gateway layer
Gateways become the highest-risk component in an AI stack. Every prompt, context payload, and model response flows through this layer. If encryption, isolation, or logging guarantees are weak here, downstream safeguards do not compensate.
Internal gateways usually fail in three predictable areas
Encryption guarantees: TLS in transit is common, but end-to-end protection during model execution is harder to prove
Execution isolation: Model providers may claim isolation without verifiable evidence
Auditability: Proving how data was handled during inference often relies on policy, not cryptographic proof
These gaps become visible during security reviews, customer questionnaires, and regulatory audits.
OLLM addresses this risk by making execution verifiable rather than assumed. Model workloads run in Trusted Execution Environments (TEEs), with attestation support via Intel TDX and NVIDIA GPU attestation. This attestation allows users to cryptographically verify, per request, that execution occurred inside an encrypted TEE rather than trusting contractual claims. Combined with enforced zero data retention, this shifts security from documentation to measurable guarantees.
This distinction matters for teams operating under strict data-handling, privacy, or regulatory constraints, where proof outweighs promises.
Time-to-market favors gateways designed for production workloads
Delivery timelines diverge sharply after the first security review. Internal gateways often reach a functional prototype quickly, but production readiness introduces delays that are hard to compress. Encryption reviews, key management design, access controls, audit logging, and failure handling are typically introduced late in the build cycle and can block launches.
Where internal timelines usually slip
Security and privacy reviews added after core routing is built
Compliance requirements are not introduced once customers ask for evidence
Provider changes requiring adapter rewrites and regression testing
On-call readiness and incident playbooks were created post-hoc
Each step is reasonable in isolation. Together, they stretch delivery from weeks into months.
Production-ready gateways remove these gating steps upfront. Security defaults, audit surfaces, and provider abstractions already exist, so teams ship applications instead of infrastructure. For experienced developers, the advantage is not convenience; it is avoiding repeated rework when AI systems move from internal demos to customer-facing products.
This difference compounds over time. Faster initial launches lead to earlier feedback, while stable gateway layers prevent infra work from becoming the long pole in future releases.
A direct comparison clarifies the trade-offs without abstraction
Side-by-side differences become obvious once gateways are evaluated as production infrastructure. The comparison below shows how teams actually experience these choices after security reviews, scaling, and audits, rather than at the prototype stage.
Dimension | Build an AI Gateway In-House | OLLM |
Time to deploy | Months, gated by security and audits | Hours, production-ready defaults |
Security model | Internally designed and maintained | TEE-based execution with attestation |
Encryption guarantees | Policy-driven, hard to verify | Cryptographically verifiable |
Privacy posture | Depends on internal controls | Enforced zero data retention |
Model access | Limited by integrations built | Multiple models available via a single API interface |
Audit readiness | Manual evidence collection | Verifiable execution proofs |
Ongoing operations | internal on-call, upgrades, incident response | handled automatically by the gateway |
The distinction is not feature depth but responsibility. Building places long-term ownership of security, uptime, and compliance on internal teams. OLLM shifts those responsibilities into a hardened gateway layer while preserving flexibility at the application level.
This makes the trade-off clearer for experienced teams: control versus speed, internal assurance versus verifiable guarantees, and platform ownership versus product focus.
Deciding who should own the AI gateway
Building an AI gateway makes sense when the gateway itself creates differentiation. This applies to teams developing proprietary platforms, highly specialized execution environments, or research systems where tight coupling to internal infrastructure is unavoidable. In these cases, long build times and ongoing maintenance are accepted as part of the strategy.
For organizations consuming external or managed models, separating model development from gateway infrastructure simplifies ownership. Teams operating proprietary training pipelines may reasonably choose tighter integration, with the understanding that this increases operational and maintenance responsibility.
For most product and platform teams, the gateway is shared infrastructure. Its role is to be reliable, secure, auditable, and adaptable as models and providers change. Owning that surface area rarely improves the end product, but it consistently slows delivery and increases long-term risk.
This is where OLLM fits naturally. By combining multi-model access with verifiable security, using TEE-based execution, Intel TDX and NVIDIA GPU attestation, and enforced zero data retention, OLLM removes infrastructure ownership from the critical path. Teams keep control where it matters, while offloading cost, time, and risk where it does not.
For experienced teams scaling AI into production, the choice is less about build versus buy and more about where responsibility should live as the system grows.
Conclusion: How teams should think about AI gateway decisions
AI gateway decisions age quickly once real users, data, and audits enter the picture. What looks manageable at the prototype stage often becomes a long-term platform obligation that pulls engineering effort away from product work. Cost grows through people and process. Timelines stretch around security reviews. Risk concentrates where proofs are weakest.
For teams shipping AI into production, the practical question is where responsibility should live over time. When infrastructure itself is the differentiator, building can be justified. When it is not, shifting security, compliance, and operational ownership to a hardened gateway reduces drag without limiting application-level flexibility.
The most durable setups treat the gateway as stable, verifiable infrastructure and keep experimentation at the edges. That separation allows teams to scale AI use without scaling risk at the same rate.
FAQ
1. What is the difference between an AI gateway and calling LLM APIs directly?
An AI gateway adds a centralized control layer for security, access management, observability, and cost governance. Direct API calls scale poorly once multiple teams, models, and compliance requirements are involved, because each application must independently handle keys, logging, audits, and operational safeguards.
2. When does it make sense to build an AI gateway instead of buying one?
Building an AI gateway makes sense when the gateway itself is part of the product or a core competitive differentiator. This typically applies to proprietary platforms or highly specialized research systems. For most application teams, building introduces ongoing platform and security ownership without improving end-user outcomes.
3. How do AI gateways affect security and compliance in production systems?
AI gateways concentrate security risk because all prompts and responses pass through them. Production-grade gateways provide stronger guarantees around encryption, execution isolation, auditability, and access control. Without these guarantees, compliance evidence often relies on policy and documentation rather than verifiable enforcement.
4. How does OLLM verify request security during model execution?
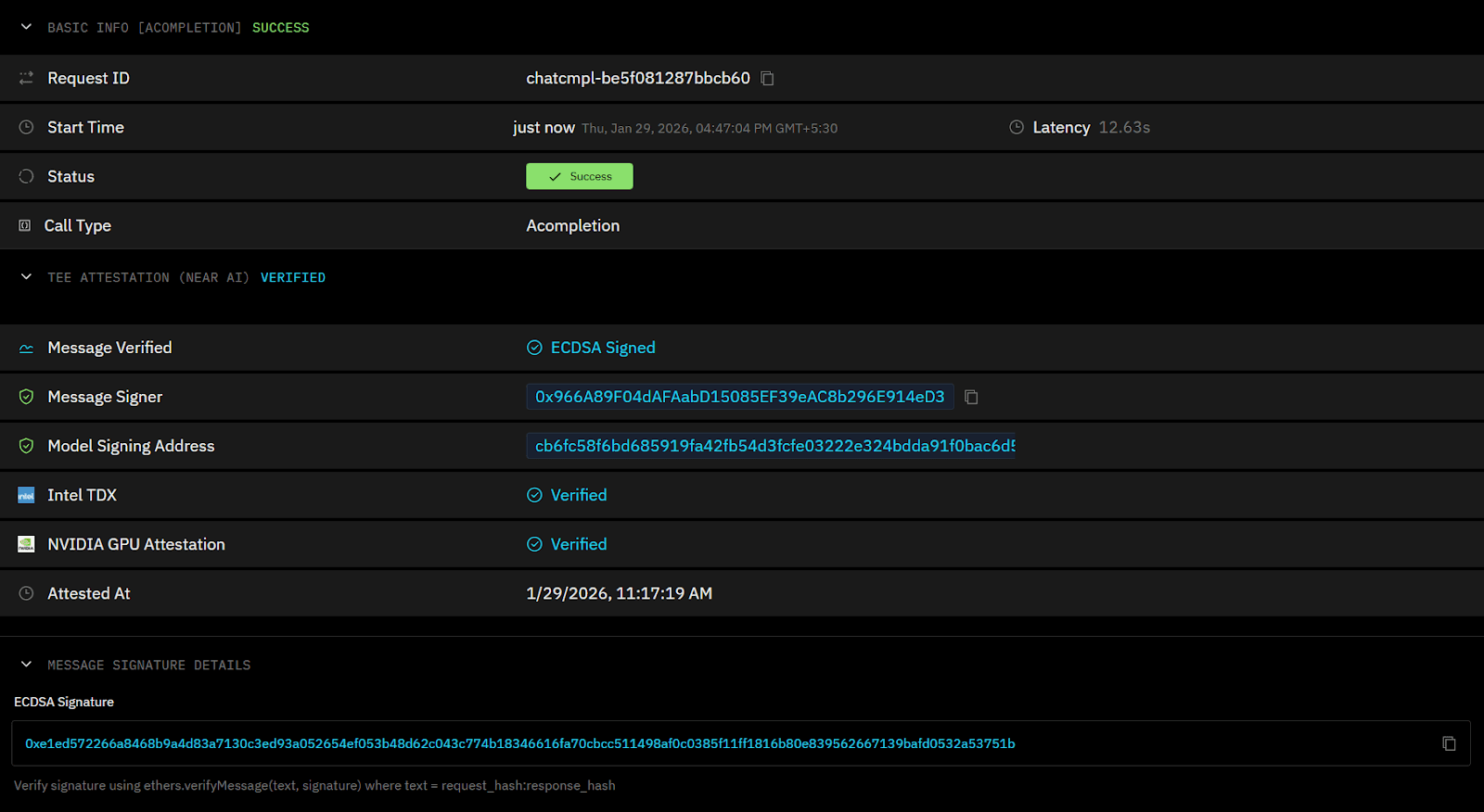
OLLM runs model workloads in Trusted Execution Environments (TEEs) and supports attestation via Intel TDX and NVIDIA GPU attestation. This allows users to cryptographically verify, per request, that execution occurred inside an encrypted environment rather than relying on contractual assurances.
5. Does OLLM require changes to existing OpenAI-based application code?
No. OLLM exposes an OpenAI-compatible API surface, which allows teams to switch endpoints and credentials without refactoring application logic. Model selection remains explicit in the request, while the gateway handles security, isolation, and operational concerns.
"/><stop offset="1" stop-color="rgb(80, 78, 87)"/></linearGradient></defs><g d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z M 142.346 0.381 L 162 0.381 L 162 20 L 142.346 20 Z M 153.986 8.381 L 158.375 8.381 L 158.375 12 L 153.986 12 L 153.986 16.571 L 150.36 16.571 L 150.36 12 L 145.972 12 L 145.972 8.381 L 150.36 8.381 L 150.36 4.19 L 153.986 4.19 Z" fill="transparent" height="20px" id="cWM2PbaAz" width="162.00000833847133px"><path d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z" fill="url(%23UyELkL66Q-1582027827-linear-gradient)" height="20px" id="UyELkL66Q" width="134.52277004415487px"/><path d="M 0 0 L 19.654 0 L 19.654 19.619 L 0 19.619 Z" fill="rgb(176, 0, 0)" height="19.618991595424752px" id="t30DbKa7C" transform="translate(142.346 0.381)" width="19.653710120697895px"/><path d="M 8.014 4.19 L 12.403 4.19 L 12.403 7.81 L 8.014 7.81 L 8.014 12.381 L 4.389 12.381 L 4.389 7.81 L 0 7.81 L 0 4.19 L 4.389 4.19 L 4.389 0 L 8.014 0 Z" fill="rgb(255, 255, 255)" height="12.380917026238919px" id="bLcZkJmGc" transform="translate(145.972 4.19)" width="12.402826775197639px"/></g></svg>)