|

TL;DR
AI gateways act as control planes for multi-model systems, providing a single programmable API across multiple LLM providers.
Unified API architecture removes provider-specific complexity, standardizing request formats, authentication, and response handling.
Centralized routing and execution management streamline communication between providers. Model choice can be application-driven, gateway-policy-driven, or a hybrid approach (for example, explicit model alias with gateway-level fallback or load balancing).
Policy, governance, and observability components consolidate usage control and performance visibility into a single layer.
Scaling happens at the gateway layer, using capacity allocation and multi-provider distribution without requiring application rewrites.
AI adoption no longer means integrating a single model provider. Teams combine multiple LLMs for reasoning, summarization, embeddings, classification, and fallback resilience. A SaaS product might route customer chat to one model, run analytics extraction on another, and rely on a third for cost-efficient background jobs. As model diversity increases, orchestration complexity increases with it.
This article explains how AI gateways solve that orchestration challenge at the architectural level. It breaks down the core layers of an AI gateway, including unified APIs, request normalization, routing engines, and multi-provider traffic control. It also explains how AI gateways support real production use cases, how request flow works end-to-end, and how enterprises scale without coupling applications to specific model vendors.
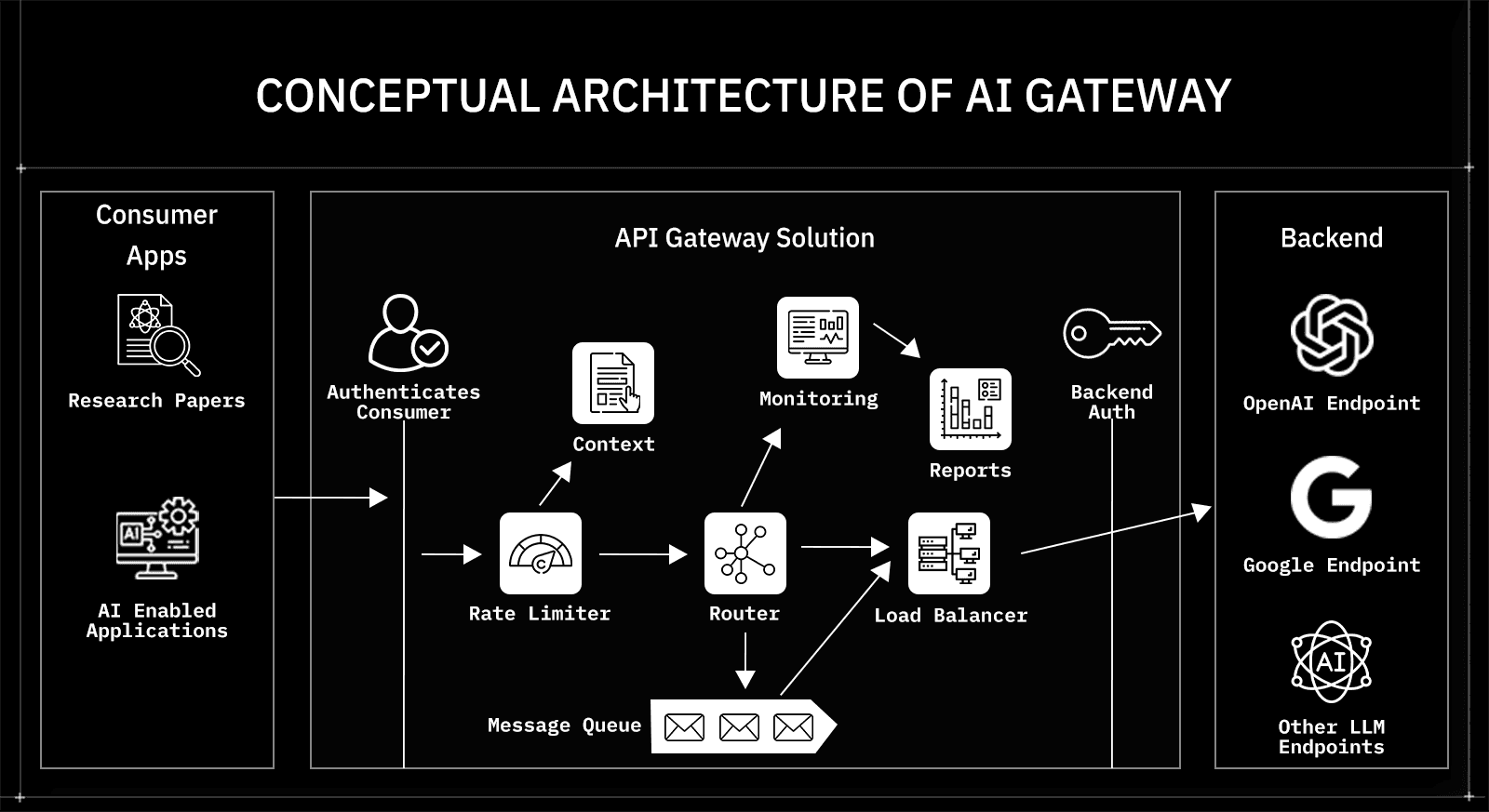
What are AI Gateways?
AI gateways exist because modern applications rarely rely on a single model. A production SaaS product might use one LLM for real-time chat, another for document summarization, and a third for embedding search. A fintech platform might route fraud analysis to a high-accuracy model while sending internal analytics tasks to a lower-cost provider. This multi-model pattern improves performance and cost efficiency, but it also increases orchestration complexity.
An AI gateway is an infrastructure layer that sits between your application and multiple LLM providers. Instead of integrating OpenAI, Anthropic, Mistral, and others separately, your application integrates with a single unified endpoint. The gateway abstracts provider-specific APIs, normalizes request formats, and routes traffic according to defined logic.
Consider a customer support system:
User message arrives in your app
Gateway routes the request to a high-accuracy model for intent detection
Follow-up summarization is routed to a cost-optimized model
If latency exceeds a threshold, traffic shifts to a backup provider
The application code does not change. Routing decisions happen inside the gateway.
Without a gateway, developers must:
Maintain separate SDKs per provider
Handle rate limits individually
Rewrite logic when switching vendors
Implement fallback and retry logic in application code
An AI gateway centralizes this orchestration. It provides:
A unified API across multiple LLM providers
Request normalization and response standardization
Policy-driven routing (cost, latency, capability)
Built-in failover and fallback logic
Centralized observability for AI traffic
This architectural pattern converts scattered model integrations into a programmable control plane. For developers building multi-model systems, the gateway serves as an abstraction layer that keeps application logic clean as AI infrastructure evolves behind it.
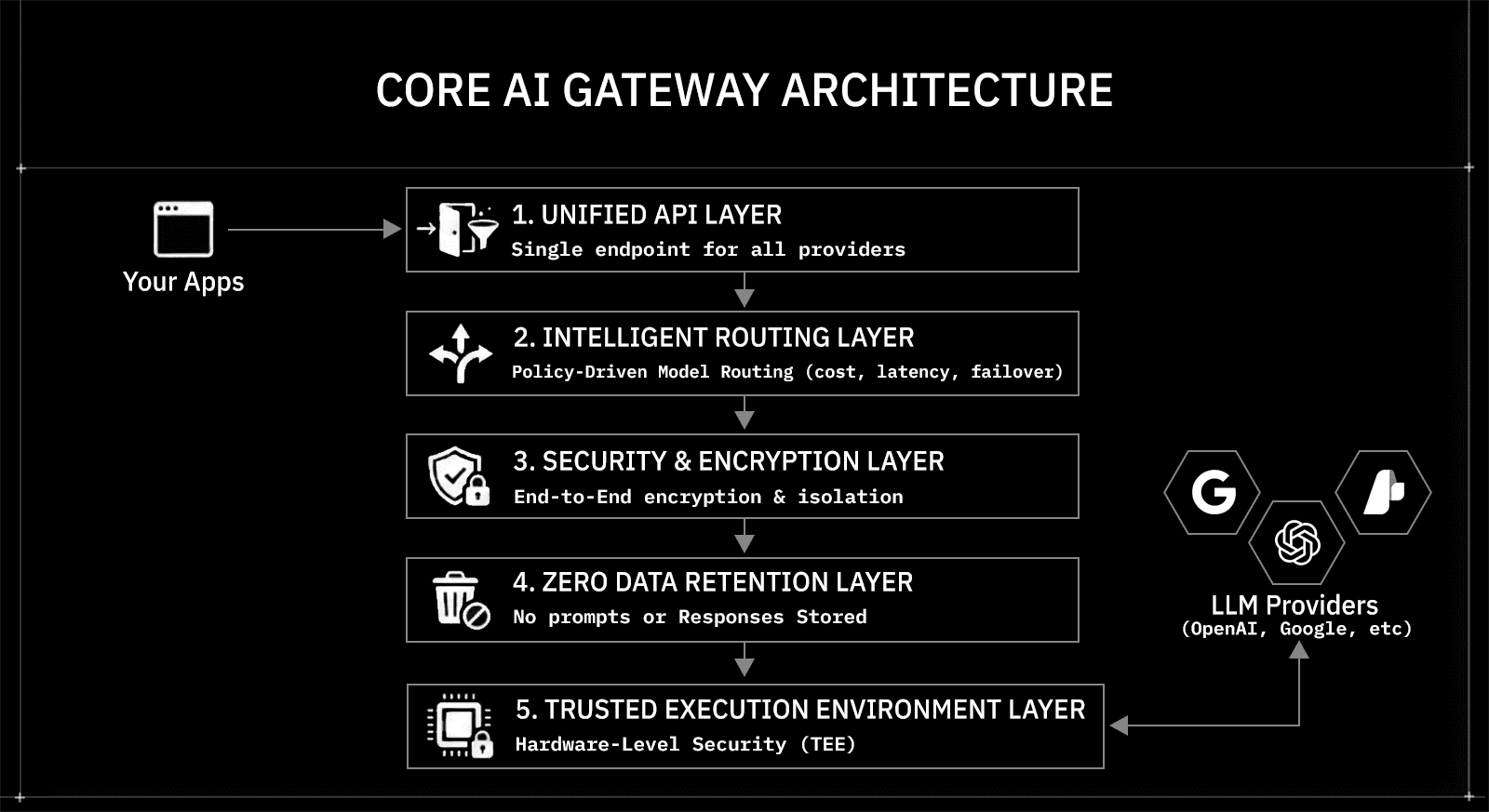
Core AI Gateway Architecture and How the Components Work Together
AI gateways rely on a structured architecture rather than isolated integrations. Each architectural component handles a distinct responsibility, from request normalization and routing to governance and response handling. This separation keeps application code clean while the gateway manages orchestration centrally.
Below is a breakdown of the core architectural components found in most AI gateways.
Unified API Architecture Standardizes Model Access
The unified API component exposes a single endpoint to applications. Developers integrate once and gain access to multiple LLM providers without embedding provider-specific logic.
This component typically handles:
Request normalization across model providers
Authentication and access validation
Schema alignment for prompts and responses
Version abstraction for evolving model APIs
For example, one provider may expect messages[], another may require input_text, and another may stream responses differently. The gateway translates these differences internally. Applications send consistent payloads while the gateway adapts them downstream.
This architectural abstraction reduces integration churn when providers update APIs or when teams introduce new models.
How AI Gateways Differ from Traditional APIs and API Gateways
Traditional APIs expose deterministic services with stable contracts. A payments API, for example, returns a fixed schema for a charge request. An API gateway handles authentication, routing, and rate limiting, but the response format and semantics remain consistent across environments.
LLM APIs introduce integration variability. Different providers implement chat completions differently:
One provider expects a
messages[]array, another expects a singleinputstringStreaming formats vary (SSE chunks vs incremental JSON)
Token limits differ across models
Error responses and rate-limit semantics are inconsistent
Model naming conventions and versioning differ
When applications integrate multiple LLM providers directly, these differences leak into service code. Engineers must adapt request formatting, streaming handlers, and error parsing per provider. That coupling is what creates architectural friction.
An AI gateway abstracts those differences by normalizing request and response contracts at a single integration layer.
An AI gateway extends the API gateway pattern to handle these differences.
Here is a simplified comparison:
Capability | Traditional API Gateway | AI Gateway |
Routing target | Routes requests to microservices by path or hostname (e.g., | Routes requests to specific LLM provider endpoints (e.g., |
Request transformation | Limited header or path rewriting | Normalizes LLM payload formats (e.g., |
Rate limiting model | Request-per-second or per-IP limits | Token-based limits (input + output tokens) and per-provider throughput control |
Streaming handling | Generic HTTP or WebSocket proxying | Normalizes SSE or streaming chunk formats across different LLM providers |
Error handling | Passes upstream service errors | Standardizes provider-specific error codes and rate-limit responses |
Cost visibility | Not natively cost-aware | Tracks token usage and cost per request, model, or API key |
Provider abstraction | Not applicable | Abstracts multiple LLM vendors behind a single API contract |
Model execution concerns | Not applicable | Handles model-specific limits (context window, max tokens, provider quotas) |
For example, a traditional API gateway might route /payments traffic to a payment microservice. An AI gateway dynamically routes a single /chat endpoint among models based on latency thresholds, token usage, or budget constraints.
Developers building AI-native systems need more than HTTP routing. They need orchestration across heterogeneous model providers. AI gateways introduce that orchestration layer without pushing vendor-specific logic into application code.
Routing Architecture Manages Traffic to Specified Models
The routing component governs how requests move from the gateway to the target model provider. In many setups, the application specifies a model name or alias, while the gateway applies execution policies such as load balancing, fallback handling, and rate-limit-aware routing. In policy-driven configurations, the gateway can also select among approved model deployments based on latency, cost constraints, or availability. Instead, it ensures that requests reach the specified model reliably and efficiently.
Routing within the gateway focuses on execution handling rather than model choice.
Routing responsibilities typically include:
Directing requests to the correct provider endpoint
Managing provider-specific connection pools
Handling retries when transient failures occur
Distributing traffic across available infrastructure capacity
Enforcing per-provider rate and throughput limits
For example, an application may explicitly call model-x for summarization. The gateway receives that request and forwards it to the correct provider endpoint. If the provider enforces rate limits or experiences temporary instability, the gateway manages retry logic and request flow control without requiring changes in application code.
In a document-processing workflow, the application defines which model handles summaries and which handles deeper reasoning. The gateway ensures reliable delivery, consistent request formatting, and stable execution against those models.
This architectural separation keeps model selection in application logic while delegating execution management to the gateway. The result is a cleaner service code and centralized control over provider communication.
Policy and Governance Architecture Centralizes Usage Control
The governance component enforces consistent rules across all AI traffic. Instead of embedding safeguards in each service, teams define AI-specific controls centrally at the gateway layer.
These controls go beyond simple rate limiting.
Common governance capabilities include:
Per-application or per-API-key usage limits
Token-based quotas (input and output)
Budget thresholds tied to model usage
Environment-based restrictions (staging vs production)
Prompt validation and schema enforcement
Output filtering and response guardrails
Model allowlists or deny-lists
For example:
A production environment may restrict which models are permitted for external-facing traffic.
A compliance-sensitive workflow may enforce structured output schemas before responses reach downstream systems.
A public API may enforce maximum token limits to prevent cost spikes or misuse.
The gateway evaluates these policies before forwarding the request and can validate or block responses before returning them.
This architectural centralization turns AI guardrails into infrastructure. Instead of scattering validation logic across services, governance lives in one enforceable control layer.
Observability Architecture Provides AI Workload Visibility
The observability component tracks usage and performance across all model interactions. Because all traffic passes through the gateway, it becomes the natural control point for metrics.
Typical visibility includes:
Request volume by model
Token consumption trends
Latency distribution
Error rates per provider
Cost attribution by team or service
In multi-model systems, this insight helps teams optimize performance and spending. Without a gateway architecture, these metrics remain fragmented across provider dashboards.
Runtime Architecture Manages Execution and Response Handling
The runtime component forwards requests, aggregates streaming responses, and returns normalized outputs to the client.
It typically manages:
Connections to downstream providers
Streaming aggregation
Response normalization
Retry and fallback handling
If a provider streams responses in provider-specific chunks, the gateway standardizes the format before returning it to the application. Client-side handling remains consistent regardless of which model processed the request.
How AI Gateways Scale Without Adding Operational Complexity
AI workloads often fluctuate significantly as products grow. A feature launch, enterprise rollout, or public API exposure can multiply inference requests within days. When applications integrate directly with model providers, scaling requires handling provider rate limits, implementing retry strategies, and occasionally introducing additional vendors. That operational complexity compounds over time.
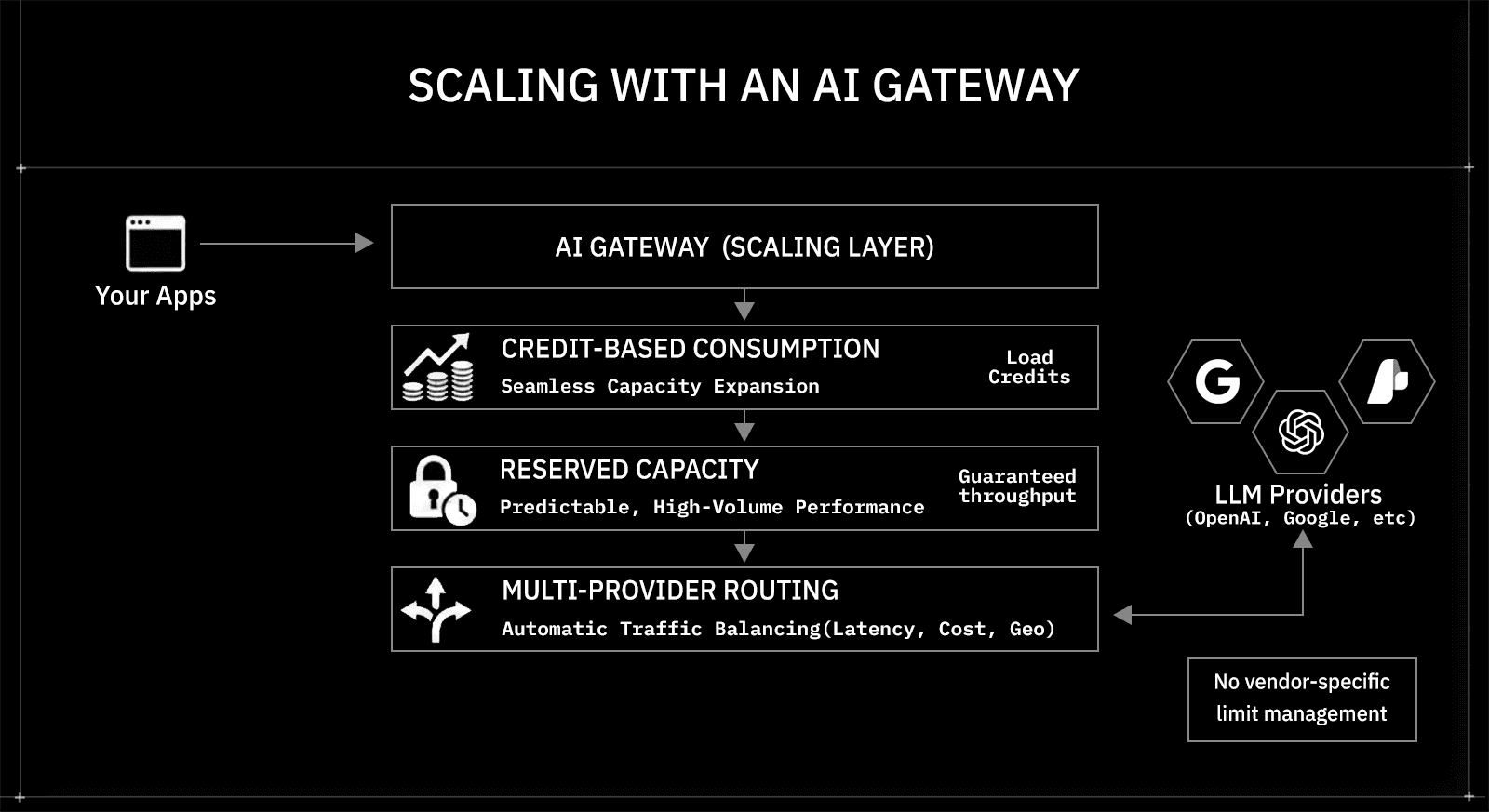
AI gateways separate application logic from capacity management. Applications continue to send requests to a single endpoint, while the gateway manages throughput, distribution, and expansion behind the scenes.
The diagram above illustrates this architecture: your apps connect to the AI gateway (scaling layer), which manages capacity across multiple LLM providers.
Three core mechanisms enable this scaling model:
1. Credit-Based Consumption Expands Throughput
Capacity increases at the gateway layer without changing integration patterns.
Add credits to increase available usage
Keep the same endpoint and request schema
Avoid redeploying services
Applications remain untouched while available inference capacity grows.
2. Reserved Capacity Ensures Predictable Performance
Reserved throughput supports sustained, high-volume workloads.
Suitable for AI chat systems with steady traffic
Useful for batch document processing pipelines
Reduces performance variability during peak usage
This mechanism shifts scaling from reactive to planned.
3. Multi-Provider Distribution Prevents Bottlenecks
Traffic can be distributed across multiple model providers based on defined policies.
Route latency-sensitive requests differently from background jobs
Avoid single-provider rate limits
Maintain service continuity during traffic spikes
The gateway handles distribution logic centrally rather than pushing it into application code.
This scaling architecture converts growth into a configuration decision. Applications remain stable, provider-agnostic, and simple, while the gateway absorbs traffic increases and capacity adjustments behind the control plane.
How OLLM Processes Requests Inside a Verifiable AI Gateway
OLLM implements the AI gateway architecture with hardware-backed confidential computing. OLLM supports TEE-backed execution for supported providers and model paths (for example, Phala/NEAR deployments), where inference runs inside hardware-isolated environments rather than standard shared infrastructure memory.
At a high level, the flow looks like this:
Your application sends a request to the OpenAI-compatible endpoint
OLLM authenticates the API key and validates the request
When a TEE-enabled model is selected, the request is routed to a secure TEE-backed execution environment
Inference runs inside encrypted memory
By default, OLLM does not store prompt or response content in persistent logs. Usage metadata such as token counts, cost metrics, and timestamps may still be tracked unless logging is explicitly disabled
Because OLLM uses an OpenAI-style API format, integration is straightforward. Existing SDKs and tooling work without modification.
OpenAI-Compatible Endpoint
OLLM exposes a standard /v1/chat/completions endpoint.
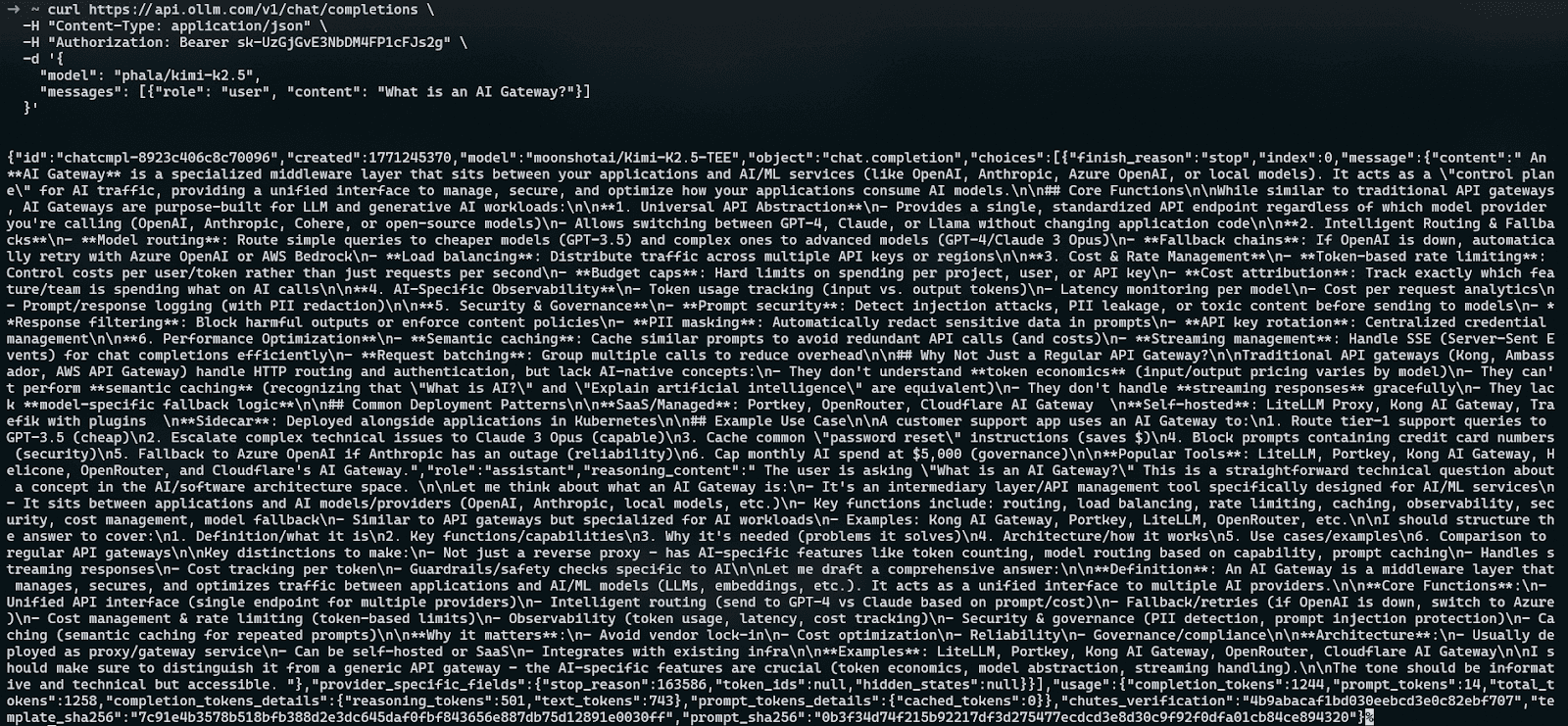
Example request:
curl https://api.ollm.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"model": "phala/kimi-k2.5",
"messages": [
{"role": "user", "content": "What is an AI Gateway?"}
]
}'
This OpenAI-compatible interface makes OLLM compatible with:
OpenAI SDKs
Existing AI frameworks
Backend services already built around chat-completion patterns
Infrastructure expecting standard REST semantics
Applications only change the base_url to https://api.ollm.com/v1.
TEE-Based Execution with Hardware Attestation
OLLM processes inference inside Trusted Execution Environments. These environments encrypt memory during computation and isolate workloads from the host operating system.
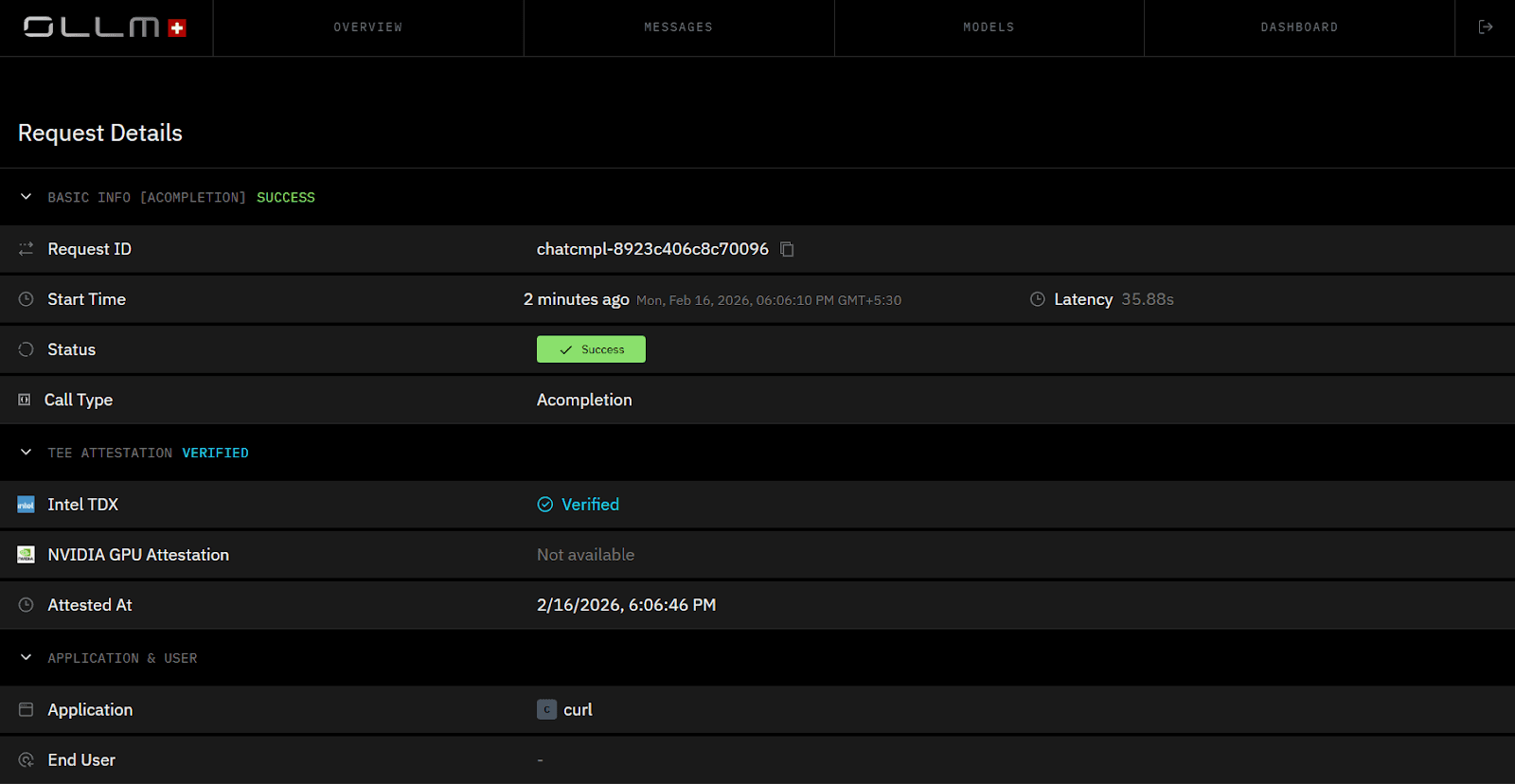
OLLM integrates:
Intel TDX for CPU-level confidential computing
NVIDIA GPU attestation for secure GPU workloads
Before inference runs, the enclave produces cryptographic attestation data. This attestation allows verification that:
The model runs inside a genuine hardware-backed TEE
The execution environment has not been tampered with
Memory is encrypted during processing
Users can validate this attestation to confirm that requests are processed inside confidential infrastructure rather than standard cloud compute.
Zero Data Retention by Design
By default, OLLM does not store prompt or response content server-side after execution. Metadata such as token usage, cost metrics, and timestamps may still be logged for billing and observability. Prompt and response storage can be enabled explicitly via configuration (for example, store_prompts_in_spend_logs) if required.
Requests are processed in memory inside the TEE and discarded after completion. This architecture ensures that sensitive prompts are not accumulated in storage layers.
OLLM Architecture from a Developer’s Perspective
From a developer’s perspective:
Integration uses a familiar OpenAI-style API
Model selection remains explicit in the request
Scaling happens behind the endpoint
Inference runs inside hardware-backed encrypted environments
Attestation provides verifiable proof of secure execution
OLLM combines standard API ergonomics with confidential computing infrastructure. The result is an AI gateway that preserves developer simplicity while providing verifiable execution guarantees at the infrastructure layer.
Why AI Gateways Are Becoming Core Infrastructure for Enterprise AI Systems
Enterprise AI has moved beyond experimentation. Organizations now embed large language models into revenue workflows, compliance automation, customer operations, and internal decision systems. As AI becomes production infrastructure, the tolerance for architectural risk declines.
Multi-model environments increase exposure. Each provider introduces different logging policies, security guarantees, and scaling behaviors. Managing these differences inside application code creates long-term operational debt. Governance becomes fragmented. Compliance becomes difficult to demonstrate.
AI gateways resolve this fragmentation by centralizing control. A single API abstracts 100+ model APIs and can expand further depending on connected providers and configuration. Routing policies determine how traffic flows. Zero data retention removes stored prompt risk. Trusted Execution Environments enforce hardware-level isolation. Cryptographic attestation provides verifiable proof of secure execution.
This combination transforms AI from vendor-dependent integration into managed infrastructure. Enterprises gain:
Unified control across model providers
Verifiable privacy backed by hardware attestation
Centralized enforcement of security policies
Elastic scaling without architectural redesign
Reduced compliance exposure through zero data retention
As regulatory scrutiny increases and AI workloads scale, this architectural layer becomes foundational. AI gateways shift the trust model from assumption to verification. For organizations operating in regulated or high-security environments, that shift defines the difference between experimental AI usage and enterprise-grade AI deployment.
Conclusion: Why AI Gateways Are Becoming the Standard Architecture for Multi-Model Systems
AI gateways convert fragmented model integrations into governed infrastructure. They unify access behind a single API, centralize governance and observability, and support strong privacy controls. In OLLM, retention and encryption behavior are configuration-driven, with privacy-preserving defaults and TEE-attested execution paths available for supported models. Routing logic optimizes cost and performance, while scaling remains predictable through credits and reserved capacity. This architecture replaces vendor trust assumptions with measurable security controls.
For teams deploying AI in regulated or high-security environments, the next step is architectural evaluation. Map current model integrations, identify data exposure surfaces, and assess whether execution environments provide verifiable guarantees or policy-based assurances. An enterprise AI gateway approach introduces centralized control, hardware-backed privacy, and operational elasticity without redesigning application logic.
FAQ
1. How does an AI gateway differ from a traditional API gateway in enterprise architecture?
An AI gateway extends the API gateway pattern to LLM inference workloads. While a traditional API gateway manages HTTP routing, authentication, and rate limiting for microservices, an AI gateway adds model abstraction, multi-provider routing, prompt normalization, token management, and inference-specific security controls. It also enforces zero-data-retention policies and integrates with Trusted Execution Environments for data-in-use protection, which standard API gateways do not address.
2. What is zero data retention in AI gateways, and why does it matter for compliance?
In OLLM, zero retention typically refers to the default non-storage of prompt and response content. Usage metadata such as token counts, timestamps, and cost can still be logged, and content logging can be explicitly enabled when required.
When content logging is disabled, requests are processed in memory and discarded after completion rather than written to persistent storage. This reduces exposure to stored prompt data and simplifies compliance considerations for environments that restrict the retention of sensitive or personally identifiable information.
3. How do Trusted Execution Environments improve AI inference security?
Trusted Execution Environments secure data while it is being processed. Technologies such as Intel TDX for CPU isolation and NVIDIA GPU attestation for GPU workloads create encrypted memory enclaves that prevent host operating systems or cloud administrators from accessing plaintext prompts. Cryptographic attestation proofs verify that inference runs inside a genuine secure enclave before data is processed, enabling verifiable data-in-use protection.
4. How does OLLM’s AI gateway provide cryptographic TEE attestation proofs?
OLLM integrates hardware-backed Trusted Execution Environments and supports cryptographic attestation mechanisms that validate enclave integrity before inference. By verifying technologies such as Intel TDX and NVIDIA GPU attestation, the gateway ensures that model execution occurs inside isolated, encrypted memory regions. These attestation proofs provide measurable evidence of secure execution rather than relying solely on policy-based guarantees.
5. How does OLLM scale AI workloads across hundreds of LLM providers?
OLLM scales through a unified API, multi-provider routing, and a credits-based usage model. Enterprises can increase capacity by loading additional credits or coordinating reserved throughput for predictable high-volume workloads. The gateway distributes traffic across providers to avoid rate limits and optimize latency. Applications continue using the same endpoint while scaling occurs behind the control plane, reducing operational complexity.
"/><stop offset="1" stop-color="rgb(80, 78, 87)"/></linearGradient></defs><g d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z M 142.346 0.381 L 162 0.381 L 162 20 L 142.346 20 Z M 153.986 8.381 L 158.375 8.381 L 158.375 12 L 153.986 12 L 153.986 16.571 L 150.36 16.571 L 150.36 12 L 145.972 12 L 145.972 8.381 L 150.36 8.381 L 150.36 4.19 L 153.986 4.19 Z" fill="transparent" height="20px" id="cWM2PbaAz" width="162.00000833847133px"><path d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z" fill="url(%23UyELkL66Q-1582027827-linear-gradient)" height="20px" id="UyELkL66Q" width="134.52277004415487px"/><path d="M 0 0 L 19.654 0 L 19.654 19.619 L 0 19.619 Z" fill="rgb(176, 0, 0)" height="19.618991595424752px" id="t30DbKa7C" transform="translate(142.346 0.381)" width="19.653710120697895px"/><path d="M 8.014 4.19 L 12.403 4.19 L 12.403 7.81 L 8.014 7.81 L 8.014 12.381 L 4.389 12.381 L 4.389 7.81 L 0 7.81 L 0 4.19 L 4.389 4.19 L 4.389 0 L 8.014 0 Z" fill="rgb(255, 255, 255)" height="12.380917026238919px" id="bLcZkJmGc" transform="translate(145.972 4.19)" width="12.402826775197639px"/></g></svg>)