|

TL;DR
Enterprise LLM deployments introduce new classes of security failures that do not occur in traditional distributed systems, including untracked data exfiltration via prompt paths and invisible identity loss at the model boundary.
Many teams treat prompt injection and model misuse as product bugs instead of structural security problems, leaving those vulnerabilities open in production without detection.
Identity and access enforcement often ends at the API key, breaking audit trails and incident response when LLM requests must be traced back to a principal.
Decentralized model usage without centralized governance (model sprawl) creates an unbounded attack surface, especially when teams use unmanaged keys or direct SDK integrations.
Observability in these systems often ends at cost and performance metrics, leaving no forensic evidence after an incident.
Platforms like OLLM address these failures by treating model access as governed infrastructure, preserving identity through inference paths and enforcing data boundaries without requiring visibility into prompt content.
Introduction: The First Enterprise LLM Incident Is Always Invisible
An LLM-driven support tool quietly leaked customer identifiers and internal service tickets in its responses for weeks, but neither security logs nor access-control alerts registered the breach. The application behaved “normally,” and only a downstream customer complaint revealed the exfiltration of data. This is not hypothetical: enterprise usage of generative AI now accounts for an average of 223 incidents per month where sensitive data is shared with AI tools, and in the top 25 percent of organizations, this figure reaches 2,100 incidents monthly, many of which involve regulated personal, financial, or healthcare data being sent to AI services in violation of policy.
A recent engineering community discussion highlights how these failures surface in practice. Developers describe prompt injection as altering system behavior in production without triggering alerts, because adversarial inputs reshape model execution in ways traditional security controls never observe prompt injection in production systems.
Traditional distributed system assumptions, such as centralized log inspection, consistent replay of operations, and complete visibility into execution paths, collapse once LLM inference becomes a dependency. Teams assume that if traffic is encrypted and authenticated, it is secure; that data loss prevention (DLP) tools see everything of interest; and that identity stays attached to every action. But inference calls rarely traverse the same paths as application data, and those assumptions create blind spots that are only discovered after production impact.
In this article, we focus on architectural and operational failure classes that cause enterprise LLM security failures, rather than on model internals or cryptographic theory. We show where risk enters the system, why existing tooling cannot catch it, and what architectural boundaries must be clarified before scaling to production.
Where Enterprise LLM Architecture Actually Lives
An “enterprise LLM” is not a single model instance. It is the sum of all request paths, service interactions, inference endpoints, and orchestration logic that connect internal systems to one or more language models. Security failures often occur not at the code level within a model but in how models are integrated with broader infrastructure.
The Hidden Path from Application to Inference
The typical request path has multiple touchpoints:
Internal application layer where service code constructs a prompt or task.
Language model SDK or API client embedded in microservices.
Internal routing or gateway layer that may perform load balancing, tenant isolation, or fallback logic.
External model provider endpoints are owned by third parties with their own retention and logging policies.
Retries, fallbacks, and error handlers that can generate side channels of data exposure if not properly instrumented.
Most documentation diagrams end at the function call: response = model.generate(prompt). In production systems, calls span untrusted networks, nonstandard SDK implementations, proxy layers, and often several intermediate caches and stores.
Why Most Diagrams Stop at “Call the Model”
Standard architectural documents treat LLM inference like any other API call, obscuring key security concerns:
Telemetry and logs often record only performance metrics (latency, throughput, error codes), not the content or origin of prompts.
The application-provided identity context is frequently lost or consolidated at the gateway layer to simplify routing.
Retries and fallbacks may resend sensitive context fragments to different endpoints without developer awareness.
As a result, responsibility boundaries blur: is the application owner responsible for securing the prompt content, or does that fall to the gateway team or the security team? Without a clear architectural model that accounts for every hop, teams make implicit trust assumptions about the infrastructure that cannot be verified.
Failure Class 1: Sensitive Data Leaves the Organization Earlier Than Expected
In production systems, prompts are not static strings. They are assembled dynamically from request context, database records, logs, tickets, and retrieved documents. This happens because richer context produces better answers, and nothing in the application stack signals that this text is about to cross an organizational boundary.
Once prompt construction happens inside the service code, data classification rules often stop applying. Fields that would never be sent to an external API directly are concatenated into a prompt because they are treated as inert text. The inference call becomes a data export path that bypasses existing controls without triggering alerts.
Why “No Training on Customer Data” Misses the Real Risk
Many teams rely on provider guarantees that customer data is not used for model training. Training is not the relevant threat model. The risk begins earlier, at the time of transmission. The moment plaintext leaves the enterprise boundary for inference, the organization loses control over retention, access, and forensic visibility. Even if data is retained briefly, teams cannot independently verify its deletion or restrict who can access it within the provider’s infrastructure. This shifts risk from theoretical misuse to practical loss of control, which matters during audits, incident response, and regulatory inquiries.
Why Data Loss Prevention Tools Do Not See This Traffic
Traditional data loss prevention tooling was built for structured flows and known protocols. Prompt traffic breaks those assumptions. Prompts are free-form, dynamically assembled, and often streamed or compressed. From the network’s perspective, this is encrypted API traffic using valid credentials. Deeper inspection introduces performance costs and privacy concerns, so many organizations choose not to inspect at all. The result is a blind spot where sensitive data leaves the system in plain text, and no security controls are in place to observe or block it.
The Accountability Gap Nobody Owns
When data is leaked through a prompt, responsibility is rarely clear. Application teams assume security owns outbound risk. Security teams assume application teams control what is sent. Platform teams often sit in between without visibility into payload content. Once plaintext crosses the inference boundary, accountability becomes ambiguous. That ambiguity is not accidental; it is architectural, and it guarantees delayed detection.
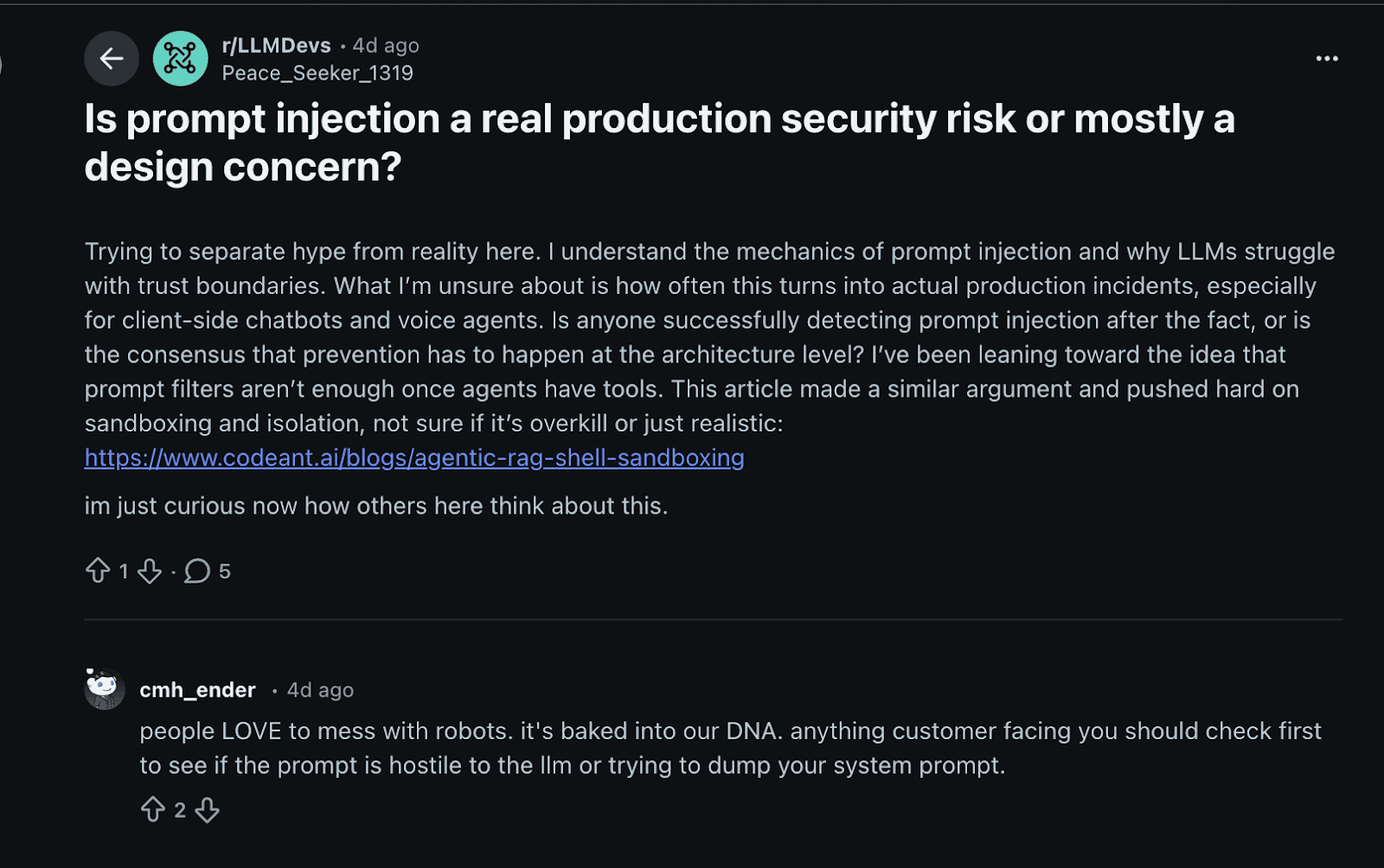
Failure Class 2: Prompt Injection Treated as a Product Bug Instead of a Security Bug
Language models do not have a concept of trusted versus untrusted input. Everything in the prompt influences behavior. In enterprise workflows, this means user input, retrieved documents, tickets, emails, and even logs can shape execution. When retrieval-augmented generation is introduced, the system explicitly feeds untrusted content back into the model, widening the attack surface by design.
How Retrieval and Tool Use Amplify Injection Risk
Prompt injection becomes significantly more dangerous when models are allowed to take actions. This includes calling internal tools, generating structured outputs consumed by other services, or making decisions that trigger workflows. At this point, injection is no longer about degrading answer quality. It becomes a way to influence control flow across systems that implicitly trust model output. A single poisoned document or crafted input can redirect behavior far beyond the model itself.
Why Prompt Hardening Fails Under Adversarial Conditions
Teams often respond with prompt templates, delimiters, or input filtering. These techniques reduce accidental misuse but do not hold against a determined adversary. An attacker does not need to override the entire prompt. They only need to introduce ambiguity or conflicting instructions at the right point in the context. Because prompt composition happens at runtime, static analysis and code review cannot reliably detect these paths.
Why Existing Security Models Do Not Catch This
Prompt injection does not map cleanly to traditional security categories. It is not a typical injection vulnerability, and it is not purely a logic bug. Static scanners cannot reason about how prompts are assembled at runtime. Web application firewalls see only encrypted requests. Logs often record only token counts or latency. As a result, exploitation can occur without leaving actionable evidence.
The core mistake is framing prompt injection as a product correctness issue. Once untrusted content can influence system behavior, the problem is no longer about output quality. It is about control boundaries, which are currently undefined in most enterprise LLM systems.
Failure Class 3: Identity and Access Control Ends at the Model API
Data exposure and prompt manipulation usually surface first, but they are rarely what breaks incident response. The real collapse happens later, when teams try to answer a basic question and cannot. That question is not what happened, but who did it.
Once LLMs are introduced, identity guarantees that were carefully built across the application stack often disappear at the exact point where risk increases.
How Identity Gets Stripped During Inference Calls
Most enterprise systems are built around strong identity propagation. Requests carry user identity, service identity, and environment context across hops. That chain often ends when a request becomes an LLM call.
Inference traffic is commonly funneled through shared SDKs, internal gateways, or proxy services that collapse identity into a single API key. From the model provider’s perspective, every request looks the same, regardless of which user, tenant, or workflow triggered it. This is convenient for routing and cost management, but destructive for security guarantees. Once identity is flattened, downstream systems cannot distinguish between legitimate usage, abuse, or compromise. The system still works, but attribution is gone.
Shared API Keys as an Architectural Liability
API keys are frequently treated as configuration, not credentials. Teams reuse them across services, environments, and even business units to simplify integration and billing. This creates a situation where access control is enforced at deployment time rather than request time. Any service holding the key can perform any action allowed by that key, regardless of who initiated the request. Revoking access becomes a blunt instrument that risks breaking unrelated workflows.
When something goes wrong, rotating the key stops the bleeding but destroys the audit trail. There is no way to isolate the source of misuse without breaking everything that depends on that credential.
Why Per-User and Per-Tenant Enforcement Rarely Exists
Many teams assume they can layer access control on top of LLM usage later. In practice, this is difficult once requests are aggregated. Per-user enforcement requires identity context to be preserved through the entire inference path. Per-tenant enforcement requires strong isolation guarantees at the gateway and provider level. Both are hard to retrofit once systems are live, because application logic, billing, and routing have already been built around shared access.
The result is a system where access control technically exists, but not at the granularity required for meaningful security decisions.
How Audit Trails Collapse During Incidents
When an incident occurs, security teams try to reconstruct a timeline. They ask which user initiated the request, what data was included, which model processed it, and what downstream actions occurred.
In many enterprise LLM deployments, none of that information is available in one place. Logs record token counts and response times. Application logs record high-level actions without prompt content. Provider logs are inaccessible or incomplete. At that point, incident response becomes speculative. Without identity continuity, teams cannot scope impact confidently, which is often worse than discovering the issue itself.
The loss of identity explains why many LLM incidents feel uncontainable. The next failure class explains why teams often do not even know how many such identity boundaries exist in their environment.
Failure Class 4: Model Sprawl Becomes an Unbounded Attack Surface
Once teams see value in LLMs, adoption spreads faster than governance structures can keep up. This growth is rarely centralized and almost never intentional. What starts as experimentation quickly becomes production dependency, and by the time security asks what models are in use, nobody can answer with confidence.
How Enterprises Accumulate Dozens of Models Without Noticing
Different teams choose models based on task fit, latency, cost, or availability. Over time, chat, embedding, and specialized reasoning models are introduced across services.
Because these integrations are often done through SDKs or direct API calls, they bypass centralized review. Model selection becomes a local decision, even though the risk profile is global. Within months, an organization may be relying on dozens of distinct inference endpoints, each with different guarantees and failure modes.
Inconsistent Provider Guarantees Create Hidden Risk
Each model provider handles data differently. Retention periods vary. Logging practices differ. Some providers allow fine-grained control, others do not. When teams treat models as interchangeable components, they ignore these differences. A model swap made for cost or performance reasons can quietly change the organization’s exposure without any architectural review. This inconsistency matters most during audits and incidents, when teams must explain where data went and under what conditions it was processed.
Shadow Usage Through Direct SDKs and Personal Credentials
Model sprawl is not limited to sanctioned services. Developers often experiment using personal API keys or direct provider SDKs to move faster. These usages rarely show up in central inventories. They are not covered by organizational policies. They may persist long after prototypes become production dependencies. Security teams often discover this shadow usage only after data appears in unexpected places or when providers flag unusual activity.
Why Governance Does Not Scale at the Model Level
Some organizations try to govern each model individually, approving usage one integration at a time. This approach does not scale. Every new model, version change, or provider update becomes a governance event. Teams bypass the process to avoid delays, creating exceptions that eventually become the norm. Without a higher-level control plane that treats model access as infrastructure rather than a library choice, sprawl is inevitable.
Defining Explicit Trust Boundaries in Enterprise LLM Systems
By the time teams reach this point, a pattern should be clear. None of the previous failures exist because teams ignored security entirely. They exist because trust boundaries were never explicitly redrawn after LLMs entered the system. Most enterprise architectures still assume that servers are trusted intermediaries. LLMs invalidate that assumption in subtle but damaging ways.
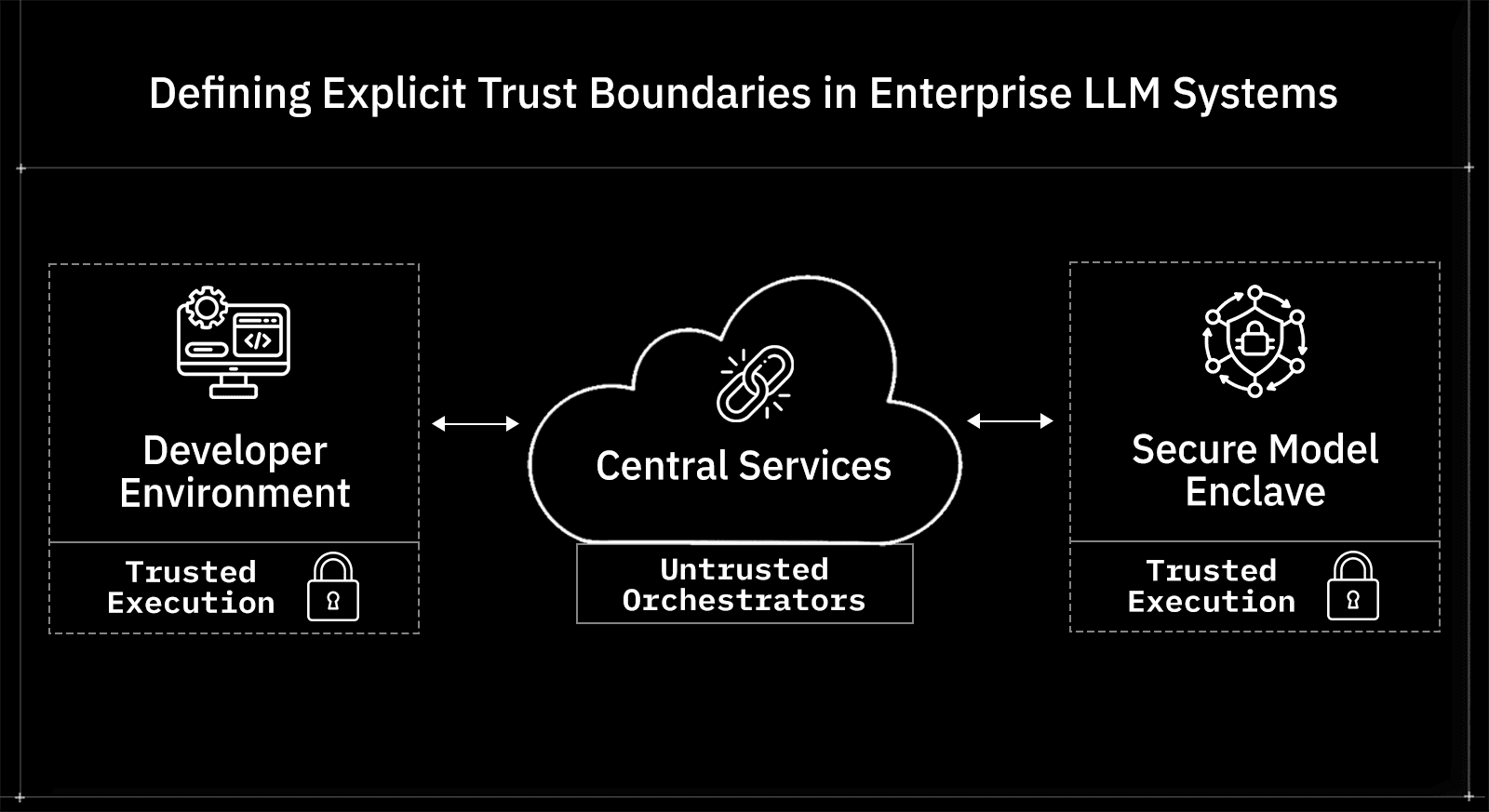
Why “Trusted Server” Is No Longer a Safe Assumption
In traditional distributed systems, servers inspect, transform, and store data as part of normal operation. Security controls are layered around that assumption.
With LLMs, servers often act as blind coordinators rather than trusted processors. They assemble prompts, route requests, handle retries, and forward responses, but they should not be trusted with plaintext in many threat models. Treating these components as trusted simply because they sit inside the network perimeter leads to overexposure. The moment plaintext is visible in more places than strictly necessary, the attack surface expands in ways that are hard to reason about and harder to audit.
Blind Infrastructure Versus Trusted Execution
A clearer model separates infrastructure that moves data from environments that are allowed to see it. Routing services, queues, schedulers, and gateways should be treated as blind infrastructure. They are allowed to handle encrypted payloads, enforce policy based on metadata, and coordinate execution, but they should not require access to plaintext to function. Trusted execution environments become narrow and explicit. These are typically limited to the client environment where data originates and the secure enclave where inference occurs. Everything in between should assume zero visibility by default.
Where Plaintext Is Allowed to Exist
One of the most important architectural decisions is defining where plaintext may legally and technically exist. If plaintext is permitted inside application servers for convenience, that choice must be treated as a risk decision, not an implementation detail. If plaintext is restricted to endpoints and enclaves, then encryption, key handling, and access control become first-class architectural concerns rather than optional features.
Teams that do not clearly draw this line tend to discover it later, during incidents or audits, when changing it is significantly more expensive.
Routing Data Is Not the Same as Accessing Data
A recurring source of confusion is the assumption that any component touching data must be able to read it. Routing encrypted payloads does not require access to content. Enforcing rate limits, quotas, or policy does not require plaintext. Many enterprise systems already operate this way for sensitive workloads, but LLM integrations often ignore those patterns. When systems conflate routing with access, they inherit risks that are entirely avoidable with clearer boundaries.
Once trust boundaries are clarified, another uncomfortable reality emerges. Many existing security tools appear to be in place, yet they fail to detect or prevent any of the failures described so far. The reason lies in how those tools interpret risk.
Why Traditional Security Tooling Misclassifies LLM Risk
Existing controls were built for deterministic systems with inspectable inputs and predictable execution paths. LLM-driven systems violate those assumptions without announcing that they have done so.
Why Web Application Firewalls Lack Semantic Context
Web application firewalls are effective when requests map cleanly to known patterns. LLM prompts do not. From the firewall’s perspective, inference traffic is authenticated, encrypted API traffic carrying opaque payloads. There is no schema to validate against and no clear boundary between data and instructions.
Even when inspection is enabled, prompts do not resemble traditional attack signatures. As a result, firewalls either allow everything or block so aggressively that they break legitimate usage, leaving teams to disable meaningful protection.
Why Static Scanning Cannot Reason About Prompt Assembly
Static analysis examines code paths and inputs at build time. Prompt construction happens dynamically at runtime. Context is pulled from databases, user input, documents, and external systems. The final prompt is assembled in memory and never exists as a static artifact. This makes it invisible to scanners that rely on code structure rather than runtime behavior. Security issues emerge from how components interact, not from individual lines of code, which places them outside the reach of traditional tooling.
Why Cloud Security Posture Tools Miss the Problem
Cloud security posture management tools reason about resources, permissions, and configurations. They do not reason about how data flows through an application. From their point of view, an LLM call is a permitted outbound API request using approved credentials. There is no misconfiguration to flag, even if the request contains sensitive data or violates internal policy. Dashboards look green while risk accumulates silently at the application layer.
How Passing Existing Checks Creates Dangerous Confidence
Perhaps the most damaging effect is psychological. When systems pass security reviews using existing tools, teams assume the risk is under control. This confidence delays deeper inspection and architectural correction. By the time a real incident occurs, the system has grown too large and too interconnected to fix quickly. At that point, teams are forced into containment rather than prevention.
What Breaks First in Regulated and High-Risk Environments
All enterprise LLM systems carry risk, but regulated environments expose weaknesses faster and with less margin for ambiguity. These environments do not fail because their threat models are different. They fail because their tolerance for uncertainty is lower.
Financial Services: Auditability Fails Before Security Does
In financial systems, the first failure is rarely a live exploit. It is the inability to explain system behavior after the fact. Audit requirements require teams to reconstruct who accessed what data, under what authorization, and for what purpose. When an LLM requests that identity be collapsed into shared keys and prompts are not logged in a reconstructable way, this chain breaks. Even if no data was misused, the inability to prove that becomes a compliance issue.
This forces conservative teams to limit usage or roll back deployments, not because models are unsafe, but because systems are unverifiable.
Healthcare: Data Handling Guarantees Become Unprovable
Healthcare environments care more about strict data-handling guarantees than about innovation speed. When prompts include patient context, symptoms, or identifiers, teams must demonstrate where that data flows, for how long it exists, and who can access it. LLM inference paths often cross boundaries that were never modeled for protected health information. Once data handling cannot be proven end to end, compliance teams treat the system as noncompliant by default, regardless of intent.
Government and Defense: Trust Assumptions Are Explicitly Challenged
In government and defense contexts, infrastructure compromise is assumed, not hypothetical. Systems are designed under the assumption that internal components may be observed or breached. LLM systems that rely on trusted servers or opaque third-party endpoints violate this assumption from the outset. Here, the failure is architectural. If plaintext exists in places that cannot be justified under the threat model, the system is rejected outright.
Large SaaS Platforms: Tenant Isolation Becomes Fragile
Multi-tenant SaaS systems rely on strict isolation guarantees. When LLM usage is centralized without preserving tenant identity or separated encryption contexts, the risk of cross-tenant data exposure increases. Even without a direct breach, the lack of provable isolation becomes a contractual liability. At scale, a single ambiguous incident can trigger customer trust erosion far beyond the technical impact.
The common thread across these environments is not regulation itself. It is the requirement to explain system behavior with precision. That requirement exposes architectural shortcuts that seemed acceptable during early adoption.
Where OLLM Fits in This Architecture (and Why It Exists)
Up to this point, the failures described share a common root cause. Enterprise LLM usage is treated as an application concern when it is actually an infrastructure concern.
OLLM exists in the gap that most teams never formally design: the boundary between internal systems and external language models, where identity, policy, and data-handling guarantees are supposed to survive inference.
Treating Model Access as Infrastructure, Not a Library Call
In many organizations, LLM access is introduced into the system through SDKs embedded directly in services. That choice pushes security, identity, and audit responsibilities into application code, where they are inconsistently implemented and hard to reason about.
OLLM takes the opposite position, as model access is centralized behind an explicit control plane that every inference request must pass through. This does not change how applications think about prompts, but it does change where enforcement occurs. By making model access infrastructure-owned rather than app-owned, teams regain a single place to reason about risk without rewriting every service.
Preserving Identity Across the Inference Boundary
One of the recurring failures described earlier is identity collapse. Requests enter the LLM layer carrying rich user and service context, then emerge flattened into shared credentials. OLLM is designed to preserve caller identity through the inference path rather than replacing it with a generic API key.
This allows access decisions, audit trails, and incident reconstruction to operate on real principals instead of abstract usage metrics. This matters less during normal operation and far more during failure. When something goes wrong, identity continuity determines whether the incident can be scoped.
Enforcing Data Boundaries Without Inspecting Content
Another tension highlighted earlier is the trade-off between observability and confidentiality. Teams want enforcement without turning every prompt into a logging liability. OLLM operates as a blind orchestrator by default.
It routes encrypted requests, applies policy based on metadata and identity, and coordinates access to models without requiring visibility into plaintext prompt content. This aligns with the trust boundary model described earlier: infrastructure that moves data does not need to read it in order to control it.
Managing Model Sprawl at the Right Layer
Model sprawl becomes dangerous when governance operates at the application or provider level. OLLM addresses this by acting as a single integration point for multiple models and providers.
From the system’s perspective, models become interchangeable backends behind a governed interface. Teams can change providers, introduce new models, or restrict usage without pushing those decisions into every service. This does not eliminate sprawl. It makes sprawl observable and governable, which is the difference between managed growth and uncontrolled risk.
Comparison: Enterprise LLMs With and Without Centralized Control
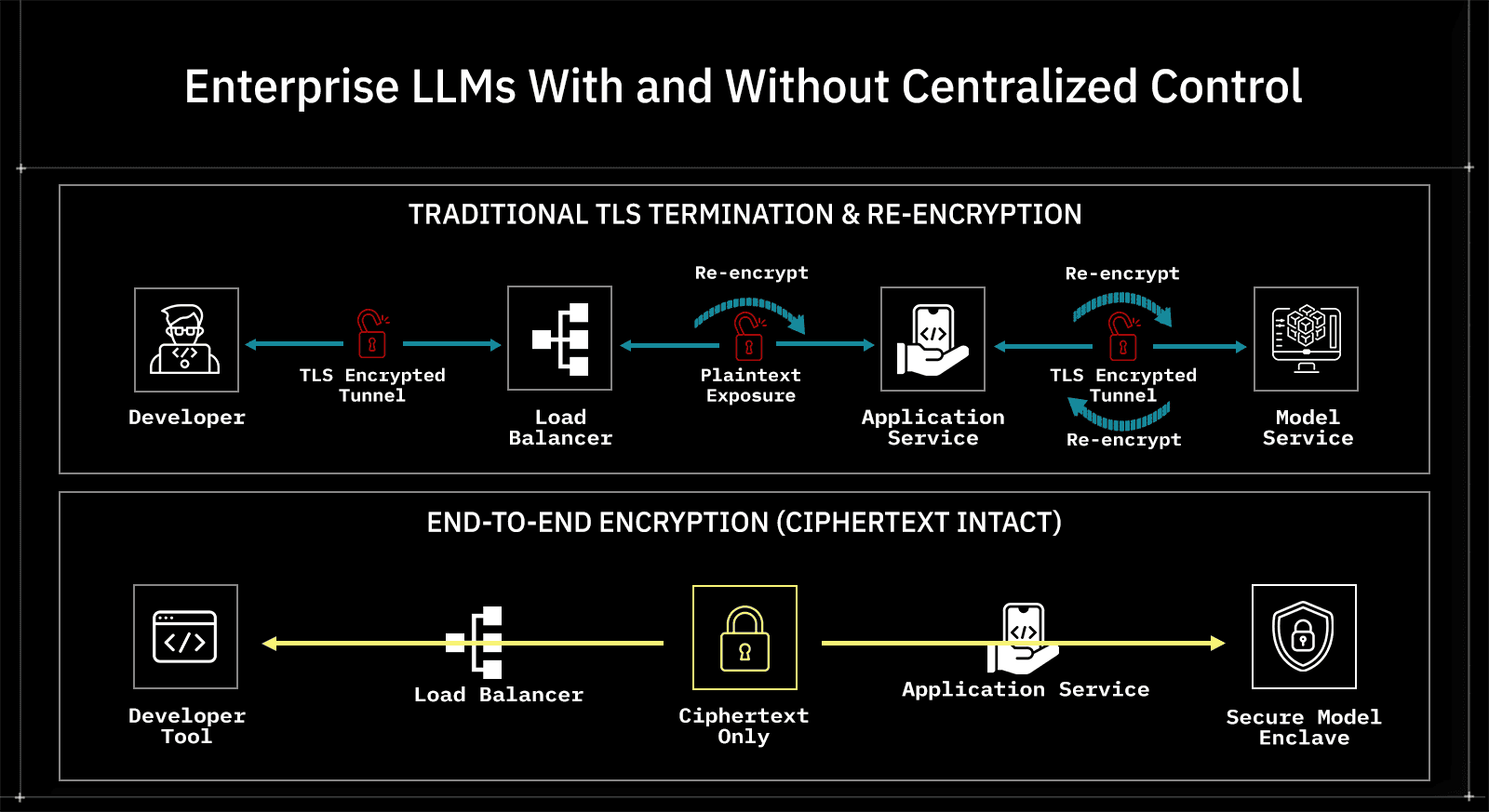
At this point, the differences between failure-prone and resilient systems are structural. The table below contrasts how enterprise LLM systems behave under pressure, not how they are marketed.
Dimension | Decentralized LLM Usage (Typical) | Centralized Control Plane for LLM Access |
Identity Propagation | Collapsed into shared API keys or service identity | Preserved per user, service, and tenant |
Prompt Visibility | Fragmented or unavailable | Governed with explicit policy and traceability |
Data Boundary Enforcement | Implicit, varies by team and provider | Explicit, consistent across all model access |
Incident Reconstruction | Partial or impossible | Deterministic and auditable |
Model Inventory | Incomplete, often unknown | Centralized and continuously observable |
Policy Enforcement | Implemented ad hoc in the application code | Enforced at a single architectural boundary |
Response to Compromise | Key rotation disrupts multiple systems | Scoped containment with minimal blast radius |
Regulatory Readiness | Relies on assumptions and attestations | Backed by enforceable controls and evidence |
Conclusion
Enterprise LLM security failures rarely originate from reckless behavior. They emerge from inherited assumptions that no longer hold once inference becomes part of core system workflows.
Data leaks occur because prompts bypass classification boundaries. Injection succeeds because untrusted content becomes an executable context. Identity collapses because access is centralized for convenience rather than accountability. Sprawl grows because governance operates at the wrong layer.
These failures surface late because existing tooling signals safety while missing the underlying risk. By the time an incident forces attention, the system has already grown too complex to fix incrementally.
Teams that succeed do not rely on better prompts or stricter guidelines. They redraw trust boundaries, preserve identity through inference paths, and treat model access as a governed system interface rather than an implementation detail.
In practice, this is where platforms like OLLM belong. Not as a feature layer on top of models, but as the control plane that sits between enterprise systems and external inference endpoints. By centralizing model access, preserving identity through inference, and enforcing data handling boundaries without inspecting prompt content, it addresses the structural failures described earlier without pushing security logic back into application code.
FAQs
1. Does enterprise LLM usage always expose sensitive data?
No. Exposure occurs when prompts include sensitive context and controls are not in place to restrict plaintext's presence. Architectures that enforce strict boundaries can significantly reduce this risk.
2. Can prompt injection be fully prevented?
No. Injection can be reduced and contained, but systems must assume that untrusted input will influence model behavior and design controls accordingly.
3. How do enterprises audit LLM behavior after an incident?
They need preserved identity context, request traceability, and governed prompt handling. Without these, audits rely on inference rather than evidence.
4. Are centralized LLM gateways required for compliance?
In regulated environments, yes. Without a centralized control plane, enforcing consistent policy, auditability, and isolation becomes impractical at scale.
"/><stop offset="1" stop-color="rgb(80, 78, 87)"/></linearGradient></defs><g d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z M 142.346 0.381 L 162 0.381 L 162 20 L 142.346 20 Z M 153.986 8.381 L 158.375 8.381 L 158.375 12 L 153.986 12 L 153.986 16.571 L 150.36 16.571 L 150.36 12 L 145.972 12 L 145.972 8.381 L 150.36 8.381 L 150.36 4.19 L 153.986 4.19 Z" fill="transparent" height="20px" id="cWM2PbaAz" width="162.00000833847133px"><path d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z" fill="url(%23UyELkL66Q-1582027827-linear-gradient)" height="20px" id="UyELkL66Q" width="134.52277004415487px"/><path d="M 0 0 L 19.654 0 L 19.654 19.619 L 0 19.619 Z" fill="rgb(176, 0, 0)" height="19.618991595424752px" id="t30DbKa7C" transform="translate(142.346 0.381)" width="19.653710120697895px"/><path d="M 8.014 4.19 L 12.403 4.19 L 12.403 7.81 L 8.014 7.81 L 8.014 12.381 L 4.389 12.381 L 4.389 7.81 L 0 7.81 L 0 4.19 L 4.389 4.19 L 4.389 0 L 8.014 0 Z" fill="rgb(255, 255, 255)" height="12.380917026238919px" id="bLcZkJmGc" transform="translate(145.972 4.19)" width="12.402826775197639px"/></g></svg>)