|

TL;DR
End-to-end encryption changes how distributed systems behave, not just how data is protected. Once servers cannot read payloads, debugging, recovery, and coordination must be redesigned from the ground up.
Many systems labeled “encrypted” still rely on server-side visibility for logging, moderation, or processing. Those access paths can weaken or negate end-to-end confidentiality guarantees. This article explains why those access paths quietly invalidate E2EE guarantees.
Real-world E2EE systems depend on specific architectural patterns, including client-owned keys, asynchronous key exchange, forward secrecy, and explicit integrity checks, each of which introduces non-obvious operational trade-offs.
Coordinating encrypted workloads is harder than encrypting messages. Task schedulers, workflow engines, and AI-backed systems must operate on structure and timing rather than content, or they reintroduce trust where it does not belong.
Metadata remains a real leakage surface even with strong encryption. Timing, size, and routing signals can reveal system behavior unless addressed through architectural controls.
OLLM combines privacy-focused logging defaults with confidential-computing execution paths for supported models and providers, reducing server-side exposure and adding verifiable attestation for inference integrity.
Why End-to-End Encryption Changes System Architecture
End-to-end encryption (E2EE) is a system property in which data is encrypted on the sender’s device and decrypted only on the recipient’s device. Servers may store, route, queue, or schedule encrypted data, but they never possess the keys required to read it.
The impact of server-side data access is well documented. The risk of centralized plaintext handling is well documented. IBM’s Cost of a Data Breach reports consistently show high breach impact and long lifecycle, especially in environments with cloud complexity and governance gaps. The pattern is consistent: once servers can read plaintext, any compromise expands from infrastructure failure into data disclosure.
Threads across security and systems communities, including recurring debates on Reddit in subreddits such as r/netsec and r/cybersecurity, often surface the same concern: teams adopt encryption in transit and at rest, yet still rely on server-side inspection for logging, moderation, or debugging. The result is a system that purports to provide privacy guarantees while retaining centralized access paths that invalidate them under pressure.
End-to-end encryption removes these access paths by design. Once servers cannot read data, familiar distributed system practices no longer function as expected. Payload inspection disappears. Server-side replay and reprocessing become risky. Debugging shifts from inspecting data to inferring behavior through metadata and state transitions. Recovery paths that depend on database access no longer exist. This shift is especially evident in contemporary systems that coordinate work rather than merely store messages. Task schedulers, workflow engines, and AI-backed coordination layers often assume visibility into inputs and outputs. In systems targeting E2EE-style guarantees, this visibility is treated as a liability. Coordination components should operate on encrypted payloads plus minimal control metadata, not plaintext content.
This article focuses on the architectural patterns that emerge from these constraints. It does not attempt to prove cryptographic security properties or compare cipher choices. Instead, it examines how distributed systems are structured when servers are intentionally blind, keys live at the edges, and coordination must occur without access to plaintext.
Threat Models and Trust Boundaries
End-to-end encryption is a response to specific threat models, and it introduces explicit trust boundaries that must be understood before any design pattern makes sense. Without a clear model of who the system is protecting against, E2EE often gets applied in ways that add complexity without improving security.
Adversaries End-to-End Encryption Is Designed For
The primary adversary E2EE addresses is a network-level attacker. This includes anyone capable of observing traffic between clients and servers, such as compromised routers, hostile networks, or malicious intermediaries. Because encryption and decryption occur only at endpoints, intercepted traffic yields ciphertext without usable context.
A second class of adversary is compromised infrastructure. In distributed systems, servers are exposed to a wide range of failure modes, including misconfiguration, vulnerable dependencies, leaked credentials, and supply-chain compromise. E2EE assumes that these failures will happen. By removing plaintext access from servers entirely, infrastructure compromise no longer implies data disclosure.
Internal access misuse is the third major threat category. This includes accidental access through debugging tools, overly permissive internal services, or intentional misuse by operators with elevated privileges. In E2EE systems, operators may control routing, storage, and scheduling, but they cannot read user data. This boundary holds even when access controls fail, because the cryptographic layer does not rely on policy enforcement.
Threats End-to-End Encryption Does Not Address
End-to-end encryption does not protect against endpoint compromise. If an attacker controls a user’s device, they can access plaintext before encryption or after decryption. E2EE assumes endpoints are trusted. Once that assumption fails, the system provides no additional protection.
Metadata exposure is another unresolved area. Even when payloads are encrypted, systems still expose timing, message size, frequency, and routing information. These signals can reveal communication patterns, relationships, or system behavior. E2EE reduces data access, not observability of activity.
Identity misbinding during key exchange is also outside the scope of protection unless explicitly handled. If a user accepts an attacker’s public key as belonging to a legitimate peer, the system will encrypt data correctly to the wrong party. Cryptography functions as intended, but trust is misplaced. This is a design and verification problem, not an encryption failure.
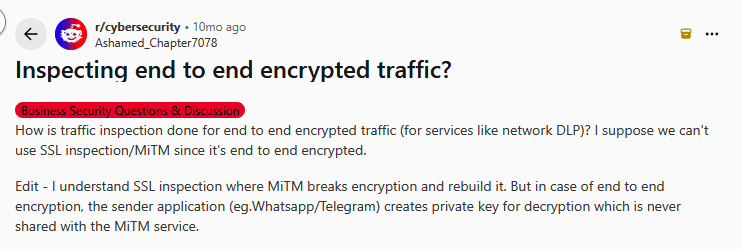
Defining Explicit Trust Boundaries
In classic end-to-end encryption, plaintext is trusted only at endpoints. Architectures that incorporate confidential computing may extend trusted processing to attested Trusted Execution Environments (TEEs) for specific server-side steps. Any component outside these explicitly defined boundaries must still be treated as untrusted with respect to data access, even if it is reliable or authenticated.
Key distribution mechanisms sit at a sensitive boundary. Directories, key servers, or discovery services may store public keys or pre-keys. These systems are trusted for availability and correctness, but not confidentiality. Their compromise should not expose the contents of the message, but it may affect who receives encrypted data.
Coordination services form the final boundary. These include message queues, workflow schedulers, task routers, or systems that sequence and trigger work. In E2EE architectures, these components operate purely on encrypted payloads and metadata. They may influence ordering, retries, or delivery guarantees, but they must do so without inspecting data. This constraint is central to designing distributed systems that coordinate encrypted workloads without violating access guarantees.
Cryptographic Primitives Used in End-to-End Encryption Systems
End-to-end encryption systems rely on a small set of cryptographic primitives that appear repeatedly across implementations. These primitives are not interchangeable at the architectural level. Each one introduces constraints that shape how distributed systems handle identity, performance, and failure.
Public Key Identity
In end-to-end encrypted systems, identity is derived from cryptographic keys rather than accounts stored on a server. A public key represents a user, device, or service endpoint. Possession of the corresponding private key is the only proof of identity the system recognizes.
This model removes reliance on centralized identity databases for data access decisions. Servers may still manage accounts, device lists, or access-control metadata, but these constructs do not permit reading encrypted content. Only the private key does. As a result, identity loss becomes a critical failure. If a private key is lost or corrupted, the system cannot recover access to previously encrypted data without an explicit recovery mechanism.
Verification paths define how one party determines that a public key belongs to the intended peer. These paths may involve direct key fingerprints, out-of-band verification, or trust-on-first-use models. Each approach carries different risks. A failure in verification does not weaken encryption itself, but it allows an attacker to receive encrypted data intended for someone else.
Symmetric Encryption for Message Payloads
While public-key cryptography establishes identity and enables secure key exchange, it is rarely used to encrypt message payloads directly. Payload encryption relies on symmetric keys because of performance and size constraints. Symmetric algorithms handle large volumes of data efficiently and produce predictable ciphertext sizes, which is important in systems that process high message throughput.
In distributed systems that coordinate encrypted workloads, payload size and encryption cost directly affect latency and resource use. Encrypting large messages on client devices shifts computational work to endpoints, including mobile or resource-constrained environments. This trade-off is intentional. The system accepts higher client-side costs in exchange for removing server-side access.
Symmetric keys are typically short-lived. They may be generated per message, per session, or per workflow step. Short-lived keys reduce exposure in the event of a key compromise, but they increase coordination complexity, particularly when messages arrive out of order or are retried.
Key Exchange
Key exchange bridges public key identity and symmetric payload encryption. It defines how two parties agree on a shared symmetric key without revealing it to intermediaries. In end-to-end encrypted systems, this exchange must function even when parties are not simultaneously online.
Static keys provide a stable identity but offer limited protection if compromised. Ephemeral keys introduce freshness and reduce long-term exposure. Most systems combine both. Long-lived identity keys authenticate participants, while ephemeral keys establish session secrets.
Session establishment becomes more complex in distributed systems with intermittent connectivity. Messages may be sent before a session exists, or long after a previous session expired. Key exchange mechanisms must tolerate these conditions without falling back to insecure behavior. This requirement directly influences later design patterns around asynchronous communication and forward secrecy.
Pattern 1: Client-Owned Key Material
Description
In this pattern, cryptographic keys are generated, stored, and used only on client devices. Servers never receive private keys and never perform encryption or decryption on behalf of users. Their role is limited to handling encrypted blobs and coordinating delivery or execution.
This creates a hard boundary between infrastructure control and data access. Even if a server is fully compromised, plaintext remains unavailable. From an architectural perspective, this removes entire classes of failure caused by logging, debugging tools, or internal access paths.
At a system level, this pattern establishes a few non-negotiable properties:
Endpoints are the only place where plaintext exists.
Infrastructure components operate on opaque data.
Access control failures do not automatically become data exposure events.
Client-owned keys also change how endpoints are modeled. A device is no longer a temporary session participant. It becomes a long-lived cryptographic actor whose state must persist across reconnects, restarts, and network changes.
System Implications
Removing server-side key ownership eliminates the need for server-side recovery. This is not a drawback that can be patched later. It is a direct outcome of the design.
Teams adopting this pattern must accept several consequences early:
Lost devices can permanently lock data.
Recovery must be explicit and opt-in.
Multi-device support requires secure device linking.
Operational responsibility shifts toward clients. Key lifecycle events, such as rotation or revocation, become visible system events rather than being handled silently in the background by infrastructure.
OLLM’s Zero-Knowledge AI Gateway
Traditional AI setups rely on "policy-based" privacy, where you trust the provider not to look at your data. In these systems, the flow looks like this:
Traditional Setup: You send a prompt → Server Decrypts → Model Processes → Server Re-encrypts.
In this model, your data is vulnerable during the "Model Processes" stage because it exists in plaintext in the server's memory.
OLLM solves this by moving from "trust" to "verification" using Confidential Computing. By leveraging hardware-based Trusted Execution Environments (TEEs), like Intel SGX or NVIDIA’s confidential GPUs, For supported TEE-backed execution paths, sensitive inference computation is isolated from host-level access, with attestation evidence available for verification.
TEE execution path: The client sends a request over authenticated transport → Supported models execute inside a hardware enclave → Attestation can be verified → Responses return through the configured API path.
By using OLLM, a task is no longer a transparent set of instructions; it is a cryptographic commitment that only the authorized hardware executor can open. For TEE-backed inference paths, operators should not be able to inspect in-enclave computation. Decryption and model execution occur within the attested enclave boundary rather than in general host memory, limiting operator visibility for those supported execution flows.
Failure Scenarios
Device Loss: Without a recovery mechanism, encrypted data tied to that device is irretrievable. Systems often address this by using shared keys across secondary devices.
Silent Key Change: If a client regenerates keys unexpectedly, peers may continue encrypting data to an outdated public key. Because servers cannot read payloads, these failures surface as undecryptable tasks with little diagnostic context.
OLLM provides cryptographic attestation reports for supported enclave execution paths. Attestation verifies enclave identity and integrity before sensitive workloads run. Device loss, key rotation drift, and peer-key verification, however, require separate key-management and recovery controls outside the attestation mechanism itself.
Pattern 2: Asynchronous Key Exchange
Problem Statement
Distributed systems cannot assume that participants are synchronized. Messages, tasks, or encrypted payloads are often produced when the intended recipient is offline. In these cases, requiring a live handshake for key exchange would stall the system.
Synchronous exchange protocols work only when both parties are present. This assumption breaks down in:
Messaging systems with offline users.
Queued task execution.
Delayed or scheduled workflows.
Without an asynchronous alternative, systems tend to reuse long-lived keys or block delivery. Both approaches increase risk.
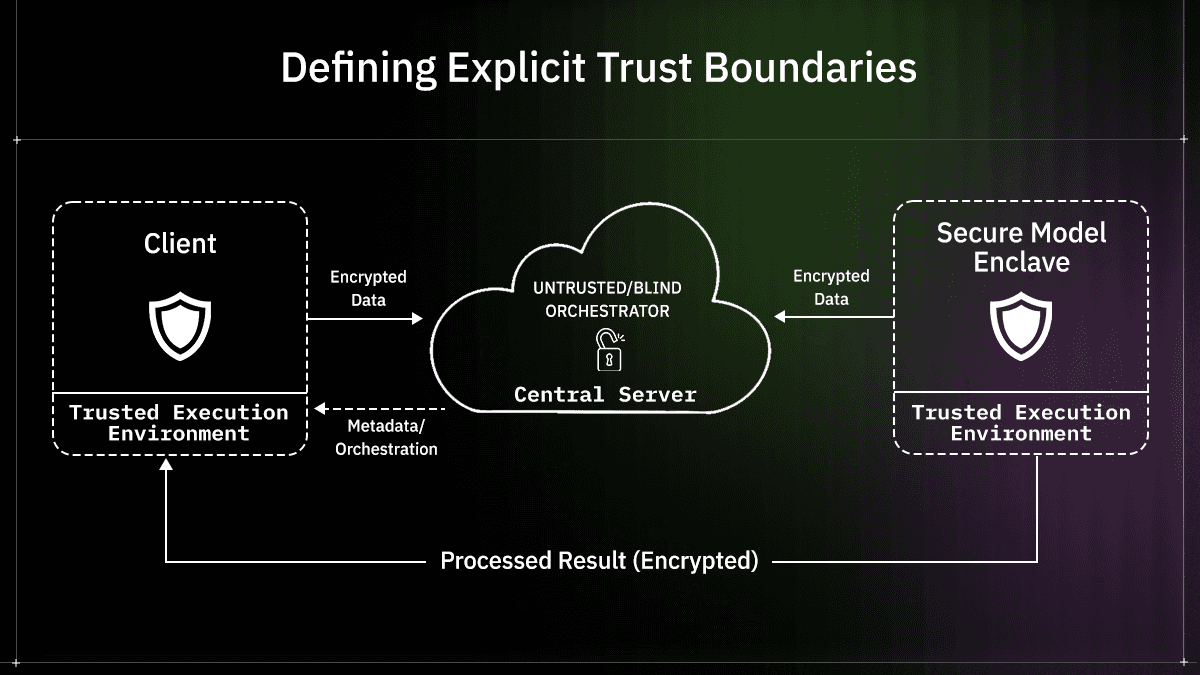
Pre-Key Distribution
Asynchronous exchange relies on pre-key distribution. Clients publish a set of public keys in advance so senders can encrypt data without waiting for the recipient to come online.
This introduces a clear trust separation:
The directory must provide correct keys.
The directory does not need access to private material.
Compromise of the directory should not expose the contents of the message.
In practice, pre-keys are consumed as messages are sent. Clients must replenish them regularly to avoid exhaustion. Reuse patterns must be avoided, since repeated use of the same pre-key weakens forward secrecy guarantees.
Key availability becomes an operational concern, similar to rate limits or quota management, but without server-side visibility into payloads.
Practical Implementations
Several production systems use this structure, most notably those influenced by Signal Protocol. These designs combine:
Long-lived identity keys for authentication.
Signed pre-keys for trust continuity.
One-time keys to limit exposure.
The same approach applies beyond messaging. Any system that encrypts data for delayed processing can adopt asynchronous exchange, provided that encryption decisions are made without assuming the recipient's presence or server-side access to keys.
Pattern 3: Forward Secrecy as a Default Property
Session-Based Keys
Forward secrecy limits the amount of data exposed when a key is compromised. In end-to-end encrypted systems, this is achieved by using short-lived session keys rather than long-lived encryption keys.
Instead of encrypting all messages with a single symmetric key, systems derive fresh keys over time. These keys may be scoped at the session, conversation, or message level, depending on latency and ordering requirements. Once a session key is discarded, previously encrypted messages cannot be decrypted, even if the long-term identity key is later exposed.
This approach changes how failures propagate. A compromised key no longer implies full historical access. Exposure is bound to a narrow window defined by key lifetime and rotation frequency.
In practice, session-based keys introduce several system-level considerations:
Clients must retain enough state to decrypt out-of-order messages.
Key derivation must tolerate retries and duplication.
Storage systems must assume that ciphertext cannot be reprocessed later.
Limiting Exposure When Keys Are Compromised
The primary value of forward secrecy is not prevention but containment. Systems should assume that keys will eventually be compromised through device loss, malware, or implementation flaws.
When forward secrecy is enforced consistently:
Past messages remain protected.
Future messages require fresh compromise.
Attackers cannot passively decrypt stored data after the fact.
This matters in distributed systems where encrypted data may be retained for long periods or replayed for delayed execution. Without forward secrecy, any future compromise of a key retroactively weakens all previously encrypted data.
Key Ratcheting
Key ratcheting extends forward secrecy by evolving keys continuously as messages are exchanged. Each message advances the cryptographic state, making previous keys unusable.
Ratcheting introduces resilience against partial compromise. If an attacker gains access to a current key, they cannot decrypt earlier messages, and once the system advances again, they also lose access to future messages.
This model complicates delivery semantics. Messages may arrive out of order, be delayed, or be duplicated. Clients must track ratchet state carefully to avoid decryption failures without leaking information about key progress. These challenges are not cryptographic edge cases, they are distributed systems problems expressed through cryptography.
Pattern 4: Message Authentication and Integrity
Why Encryption Alone Is Insufficient
Encryption protects confidentiality, but it does not guarantee that data has not been altered. An attacker who cannot read a message may still modify it, replay it, or inject new ciphertext into the system.
In distributed systems, this risk increases. Messages may pass through queues, brokers, or coordination layers that are not trusted for data integrity. Without explicit authentication, clients cannot distinguish between valid messages and manipulated ones.
Two common attack classes remain possible without integrity checks:
Modification of encrypted payloads to trigger failures or undefined behavior.
Replay of old messages to repeat actions or corrupt state.
Active Attacker Capabilities
An active attacker can intercept traffic and modify ciphertext in transit. Even small changes can cause predictable failures that leak information or disrupt workflows. In systems that coordinate encrypted tasks, this may surface as repeated execution, stalled pipelines, or corrupted state transitions.
Because servers cannot inspect payloads, they cannot detect or correct these issues. Integrity must be enforced end-to-end, just like confidentiality.
Integrity Mechanisms
End-to-end encrypted systems attach authentication data to each encrypted message. This allows recipients to verify that the message was created by the expected sender and has not been altered.
Typical mechanisms include:
Message authentication codes derived from shared secrets.
Counters or sequence numbers to detect replay.
Explicit binding between ciphertext and sender identity.
These checks occur before decryption. If validation fails, the message is discarded without revealing its contents. This behavior is critical in systems where encrypted messages may trigger side effects, such as task execution or state changes.
OLLM ensures integrity through two specific mechanisms:
Hardware-Level Verification: The Trusted Execution Environment (TEE) produces an "attestation report." This is a mathematical proof that the model was executed exactly as expected on the specified hardware, without any outside interference.
Authenticated Workflows: Tamper resistance and sender authenticity require explicit application-layer integrity controls, such as authenticated encryption (AEAD), nonces or counters for replay protection, and, where appropriate, digital signatures. These mechanisms turn encrypted payloads into verifiable units of work. Trusted Execution Environment attestation verifies enclave identity and integrity, but it does not replace message-level authentication or replay protection.
Pattern 5: Metadata Reduction Techniques
What Metadata Reveals
End-to-end encryption protects the content of messages, but it does not conceal everything. Even when payloads are encrypted, systems still emit metadata that can reveal how they are used. Timing, message size, and routing paths often remain visible to servers and intermediaries.
Over time, this information can expose sensitive patterns. Regular message intervals may indicate automated workflows. Sudden bursts of traffic may correlate with specific actions. Even without access to plaintext, an observer can infer relationships or system behavior from metadata alone.
Metadata leakage is especially relevant in distributed systems that coordinate work across multiple services. While each service may only see a fragment of activity, aggregation across infrastructure layers can reconstruct a detailed picture of system usage.
Architectural Controls
Reducing metadata exposure requires architectural choices rather than cryptographic primitives alone. These choices often trade efficiency for privacy and must be evaluated early.
Common techniques include padding messages to reduce size variability and batching deliveries to obscure timing signals. Both approaches increase latency and resource use, but they reduce the fidelity of observable patterns. In some systems, identity information is separated from transport entirely so that routing decisions do not reveal who is communicating with whom.
None of these techniques eliminates metadata leakage. They aim to reduce precision and correlation. Metadata reduction is often overlooked because it does not affect functional correctness. Systems work without it. The impact only becomes apparent when adversaries analyze behavior over time, which makes this pattern easy to postpone and difficult to retrofit.
Operational Constraints in End-to-End Encrypted Systems
Though there are numerous constraints, we will discuss the top 3 here:
1. Observability Limits
Once servers cannot read payloads, most traditional observability techniques cease to function. Logs no longer contain request data, traces cannot show inputs or outputs, and replay-based debugging is no longer possible. Engineers are forced to reason about behavior rather than content.
Consider a distributed workflow system that routes encrypted tasks between services. If a task stalls, the server cannot inspect the task payload to see what went wrong. Instead, debugging relies on signals such as when the task was queued, how many retries occurred, and where execution stopped. The problem is inferred by reconstructing the execution path rather than by reading data.
As a result, instrumentation shifts toward control flow. Missing messages, repeated retries, and long gaps between state transitions become the primary indicators of failure. Systems that do not plan for this often feel opaque once encryption is enforced.
2. Abuse Prevention
End-to-end encryption also limits the ability to detect misuse. Because servers cannot inspect content, abuse prevention relies on behavioral rather than payload-based analysis.
For example, a messaging or task submission system may only see how often requests are sent, how much compute is consumed, or how frequently workflows fail. These signals can indicate misuse, but they are imprecise. High-volume legitimate users may look suspicious, while low-volume abuse may slip through unnoticed.
This trade-off is inherent. Any system that guarantees server-side blindness must accept reduced enforcement accuracy. The goal is to manage risk through rate limits and behavioral thresholds rather than to eliminate misuse entirely.
3. Performance Considerations
Encryption moves computational cost to the edges. Clients handle key generation, encryption, decryption, and state tracking. On modern desktops this overhead is usually acceptable, but on mobile or constrained devices it can become noticeable.
At scale, the impact shows up indirectly. Encrypted payloads are larger, increasing storage and bandwidth use. Clients must hold more state to manage keys and retries. When a component fails, servers cannot correct or optimize payload handling because they cannot inspect the payload. These are not reasons to avoid end-to-end encryption. They are constraints that influence capacity planning, retry behavior, and client resource budgets.
Common Design Errors
Many systems weaken their own guarantees by introducing server-side access paths after encryption is added.
A common example is storing private keys on servers for “recovery” purposes. This shifts encryption from a cryptographic boundary into a policy decision. Once keys exist on infrastructure, any server compromise becomes a data compromise.
Another frequent mistake is equating transport encryption with end-to-end encryption. Transport Layer Security protects data in transit between hops, but each service that terminates the connection can still read the plaintext. In multi-service systems, this quietly expands the trust boundary with every hop.
Key backups also cause problems when threat models are unclear. Encrypting backups does not help if the backup keys are managed by the same infrastructure. Instead of reducing risk, this creates additional avenues for compromise.
Finally, weak identity verification during onboarding leads to silent failures. If a device accepts an incorrect public key, encryption still works, but the data is sent to the wrong party. Nothing breaks visibly, and the error is difficult to detect later.
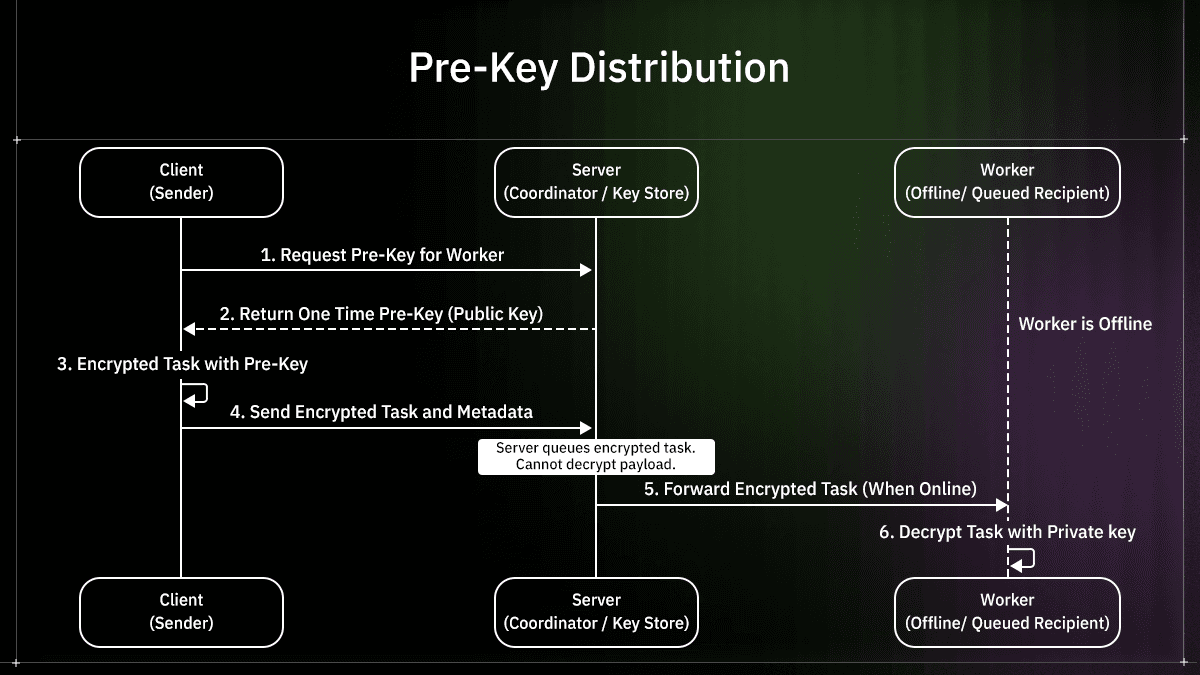
How OLLM Avoids Common Design Pitfalls
Many systems weaken their own guarantees by introducing server-side access paths for "convenience." OLLM is architected to eliminate these compromises:
No Centralized "Recovery" Keys: Unlike traditional orchestrators that store master keys for "debugging," OLLM leaves key ownership at the edge. If OLLM’s infrastructure is breached, the attacker finds only opaque ciphertext.
Beyond Transport Encryption: While others rely only on TLS (which terminates at the server), OLLM ensures data remains encrypted even inside the processing environment using Confidential Computing (TEEs).
Verification over Trust: OLLM uses cryptographic proofs to verify that your data was processed in a secure enclave, moving the needle from "trusting the provider" to "verifying the math."
Comparison: End-to-End Encryption vs Transport-Level Encryption
Aspect | End-to-End Encryption | Transport-Level Encryption |
Security boundary | Plaintext exists only on sender and recipient devices. Servers never see decrypted data. | Plaintext is decrypted on servers at each hop along the path terminating the connection. |
Server trust assumption | Servers are treated as untrusted for data access by design. | Servers are trusted to handle plaintext securely. |
Impact of infrastructure compromise | Infrastructure compromise does not expose message contents. | An infrastructure compromise can expose plaintext stored or in transit. |
Key ownership | Keys are generated and held by clients. | Keys are managed by servers or infrastructure components. |
Operational visibility | Limited to metadata, identifiers, and state transitions. Payload inspection is not possible. | Full visibility into request contents, responses, and payload structure. |
Typical use cases | Privacy-sensitive messaging, secure coordination, encrypted workflows. | Traditional web services, internal APIs, and systems requiring inspection. |
Conclusion
End-to-end encryption cannot be treated as a late-stage security upgrade. Once servers are unable to read data, the system behaves differently at every layer. Debugging changes, recovery paths disappear, identity becomes cryptographic, and coordination must happen without payload visibility. These effects are not edge cases. They are the natural outcome of moving trust to the edges.
The design choices covered in this article, client-owned keys, asynchronous exchange, forward secrecy, and explicit integrity checks, exist to keep systems usable under these constraints. They do not simplify system design. They make their limitations explicit and force teams to choose where responsibility lives, how failures surface, and what trade-offs are acceptable.
OLLM is built around this assumption. It is designed to reduce and constrain server-side plaintext exposure, with attested TEE execution paths for supported models and providers. If you are evaluating how end-to-end encryption affects real distributed workflows, not just message transport, exploring this model is a practical next step.
FAQs
1. Does end-to-end encryption prevent server-side data access?
Yes. In a correctly implemented end-to-end encrypted system, servers never possess the keys required to decrypt data. They may store or route ciphertext, but they cannot read message contents.
2. Can large distributed systems operate with end-to-end encryption?
Yes, but only when designed for it from the start. Systems must separate control data from payloads and accept limits on inspection and enforcement. Retrofitting encryption into existing architectures is significantly harder.
3. How does end-to-end encryption affect debugging?
It removes the ability to inspect payloads on the server. Debugging relies on metadata, state transitions, and client-side diagnostics rather than server-side logs of request contents.
4. Is end-to-end encryption compatible with regulatory requirements?
It can be, depending on the regulation and system design. End-to-end encryption reduces server-side exposure but may complicate requirements related to access, moderation, or auditability. Compliance must be evaluated case by case.
"/><stop offset="1" stop-color="rgb(80, 78, 87)"/></linearGradient></defs><g d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z M 142.346 0.381 L 162 0.381 L 162 20 L 142.346 20 Z M 153.986 8.381 L 158.375 8.381 L 158.375 12 L 153.986 12 L 153.986 16.571 L 150.36 16.571 L 150.36 12 L 145.972 12 L 145.972 8.381 L 150.36 8.381 L 150.36 4.19 L 153.986 4.19 Z" fill="transparent" height="20px" id="cWM2PbaAz" width="162.00000833847133px"><path d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z" fill="url(%23UyELkL66Q-1582027827-linear-gradient)" height="20px" id="UyELkL66Q" width="134.52277004415487px"/><path d="M 0 0 L 19.654 0 L 19.654 19.619 L 0 19.619 Z" fill="rgb(176, 0, 0)" height="19.618991595424752px" id="t30DbKa7C" transform="translate(142.346 0.381)" width="19.653710120697895px"/><path d="M 8.014 4.19 L 12.403 4.19 L 12.403 7.81 L 8.014 7.81 L 8.014 12.381 L 4.389 12.381 L 4.389 7.81 L 0 7.81 L 0 4.19 L 4.389 4.19 L 4.389 0 L 8.014 0 Z" fill="rgb(255, 255, 255)" height="12.380917026238919px" id="bLcZkJmGc" transform="translate(145.972 4.19)" width="12.402826775197639px"/></g></svg>)