|

TLDR
Confidential computing protects AI workloads during execution, not just at rest or in transit, by isolating runtime memory using hardware-backed Trusted Execution Environments (TEEs).
Enterprise AI introduces hidden exposure risks through logging pipelines, observability systems, multi-provider integrations, and retained prompt artifacts that can form a “hidden database.”
Hardware-backed attestation (Intel TDX + NVIDIA GPU attestation) enables verifiable execution integrity, allowing enterprises to validate that inference ran inside isolated, untampered compute environments.
Zero-retention controls (when enforced via configuration) prevent the durable storage of prompt and response content, reducing the breach blast radius. Operational metadata may still be retained for billing, reliability, or audit workflows.
OLLM provides a unified confidential AI gateway that forwards model-specific requests and exposes attestation artifacts. In this reference architecture, model selection is explicit at the application layer, and routing behavior is deployment-configurable rather than dynamically enforced.
AI adoption is accelerating across regulated industries. Banks use large language models to analyze transaction data. Healthcare platforms process clinical summaries. Legal teams review contracts through AI copilots. These systems handle highly sensitive information. As AI moves into production, data protection requirements move from best practice to board-level priority.
Confidential computing introduces a new security model for AI workloads. It protects data not only when it is stored or transmitted, but also when it is being processed. This article explains what confidential computing means, why traditional AI infrastructure creates hidden exposure risks, how Trusted Execution Environments enforce encryption in use, and how hardware-backed attestation and zero data retention change the enterprise security equation.
What Does Confidential Computing Mean?
Confidential computing protects data while it is being processed, not only when it is stored or transmitted. It extends traditional encryption models by adding protection for data in memory during execution. This model is commonly described as encryption in use. Unlike software-based controls, enforcement occurs at the hardware level via CPU and GPU security extensions.
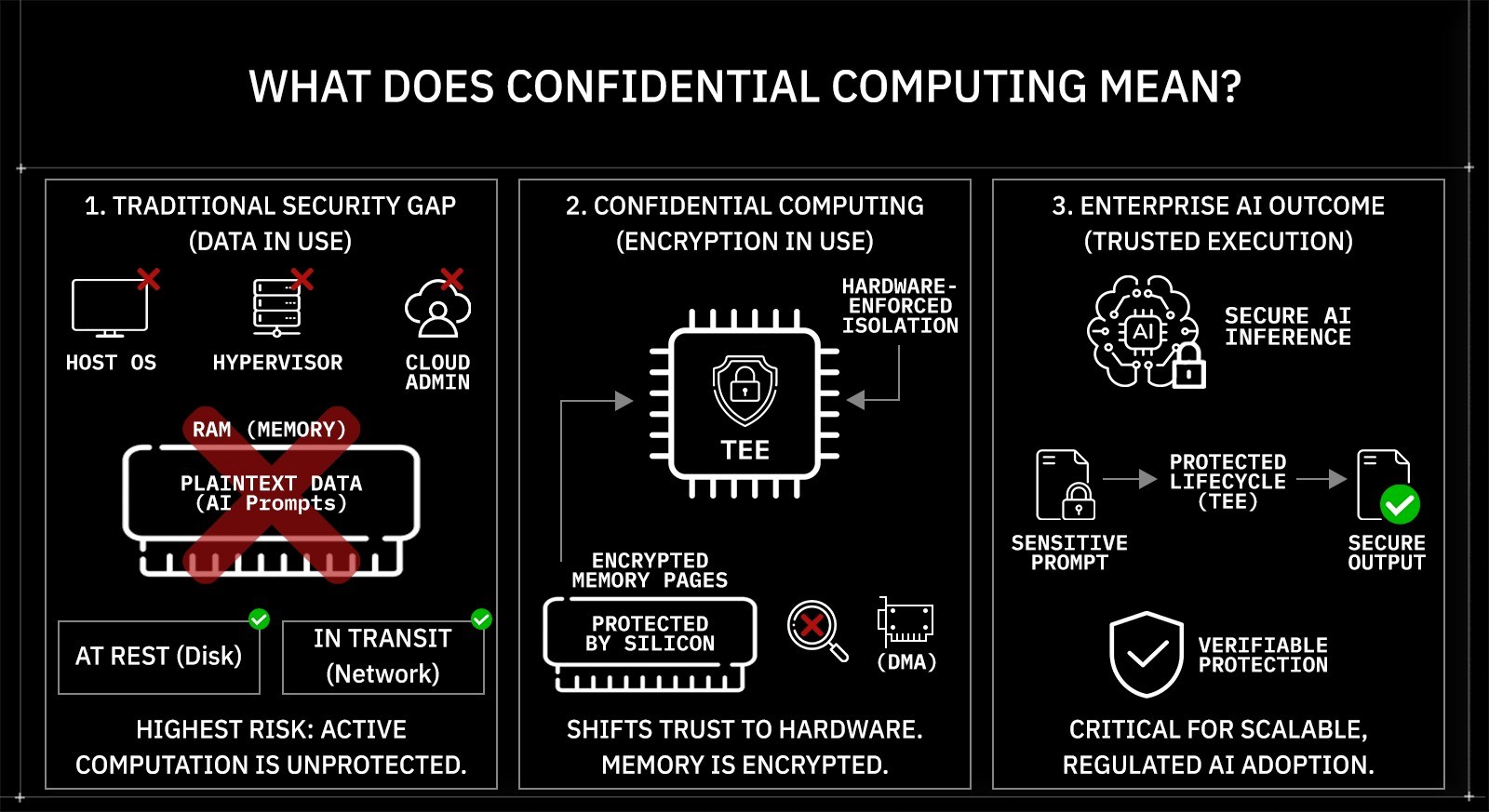
Consider an enterprise AI copilot deployed inside a financial institution. Employees submit prompts containing transaction records, internal audit findings, or regulatory filings. During inference, that prompt must be decrypted in memory so the model can compute a response. At that moment, the data exists in plaintext inside RAM. In traditional cloud environments, that memory can theoretically be inspected by:
The host operating system
The hypervisor
Privileged infrastructure administrators
Co-tenant side-channel or isolation-failure vectors on shared hardware
The highest-risk state is not storage. It is an active computation.
Traditional security models cover two data states:
Encryption at rest protects disks and databases.
Encryption in transit protects network communication using TLS.
Neither protects memory during execution. AI workloads amplify this gap because prompts, intermediate tensors, embeddings, and generated outputs may contain regulated or proprietary information.
Trusted Execution Environments (TEEs) enable encryption in use. A TEE creates a hardware-isolated execution boundary inside a CPU or GPU. Memory pages inside the enclave are encrypted using hardware-managed keys. The hypervisor cannot read enclave memory. Direct memory access (DMA) from peripherals is restricted. The workload is cryptographically measured at launch, producing a verifiable identity for the running code.
Confidential computing shifts trust from infrastructure operators to silicon-enforced isolation. For enterprise AI systems, this means sensitive prompts and model outputs remain protected throughout the entire execution lifecycle, including the exact moment they are decrypted for inference.
Most enterprise AI architectures were not originally built with these guarantees in mind. As adoption scales, the absence of runtime isolation becomes a structural risk. Understanding that gap is essential before examining how real-world AI infrastructure introduces hidden exposure points.
Why Enterprise AI Infrastructure Introduces Hidden Data Exposure Risks
Confidential computing addresses runtime isolation. Most enterprise AI stacks, however, are assembled from general-purpose cloud components that were not designed for strict confidentiality guarantees. As AI moves from experimentation to production, architectural defaults begin to matter.
AI prompts and responses frequently contain regulated or proprietary information. An internal copilot may process:
Customer financial records
Clinical notes and diagnostic summaries
Legal agreements and discovery material
Private source code repositories
Board-level strategy documents
Each inference request flows across multiple layers: API gateways, reverse proxies, observability agents, SDK wrappers, and model provider infrastructure. Every layer introduces potential visibility into request payloads.
Logging and telemetry create unintended retention. Many deployments enable structured logging, distributed tracing, or application performance monitoring by default. Payload fields may be captured for debugging. Reverse proxies may buffer requests. Observability pipelines may export traces to centralized SIEM systems. Even short-lived storage in log aggregators or message queues creates recoverable artifacts.
Over time, these artifacts accumulate into what can be described as a “hidden database.” Prompts, partial responses, cached embeddings, and telemetry metadata form a historical corpus. That corpus becomes a liability. A breach does not need to target the model provider directly; it can target logs, tracing systems, or monitoring backends.
Multi-provider integration increases fragmentation. Enterprises often integrate multiple LLM vendors for redundancy or cost optimization. Each provider brings:
Different logging defaults
Independent data retention policies
Separate authentication and rate-limit controls
Distinct compliance attestations
Security guarantees become uneven across the inference path. A single weak link can undermine an otherwise secure architecture.
Regulatory frameworks such as SOC 2, HIPAA, and GDPR require demonstrable controls over data processing and retention. Statements about “not training on data” do not address runtime exposure or telemetry persistence. Without architectural constraints, policy assurances remain incomplete.
For enterprise AI to meet confidentiality standards, two structural guarantees are necessary:
No persistent storage of prompts or responses across infrastructure layers
Verifiable hardware-enforced isolation during computation
The first reduces historical breach impact. The second reduces the runtime's attack surface. The next section examines how Trusted Execution Environments implement hardware-level isolation.
How Trusted Execution Environments Secure AI Data in Use
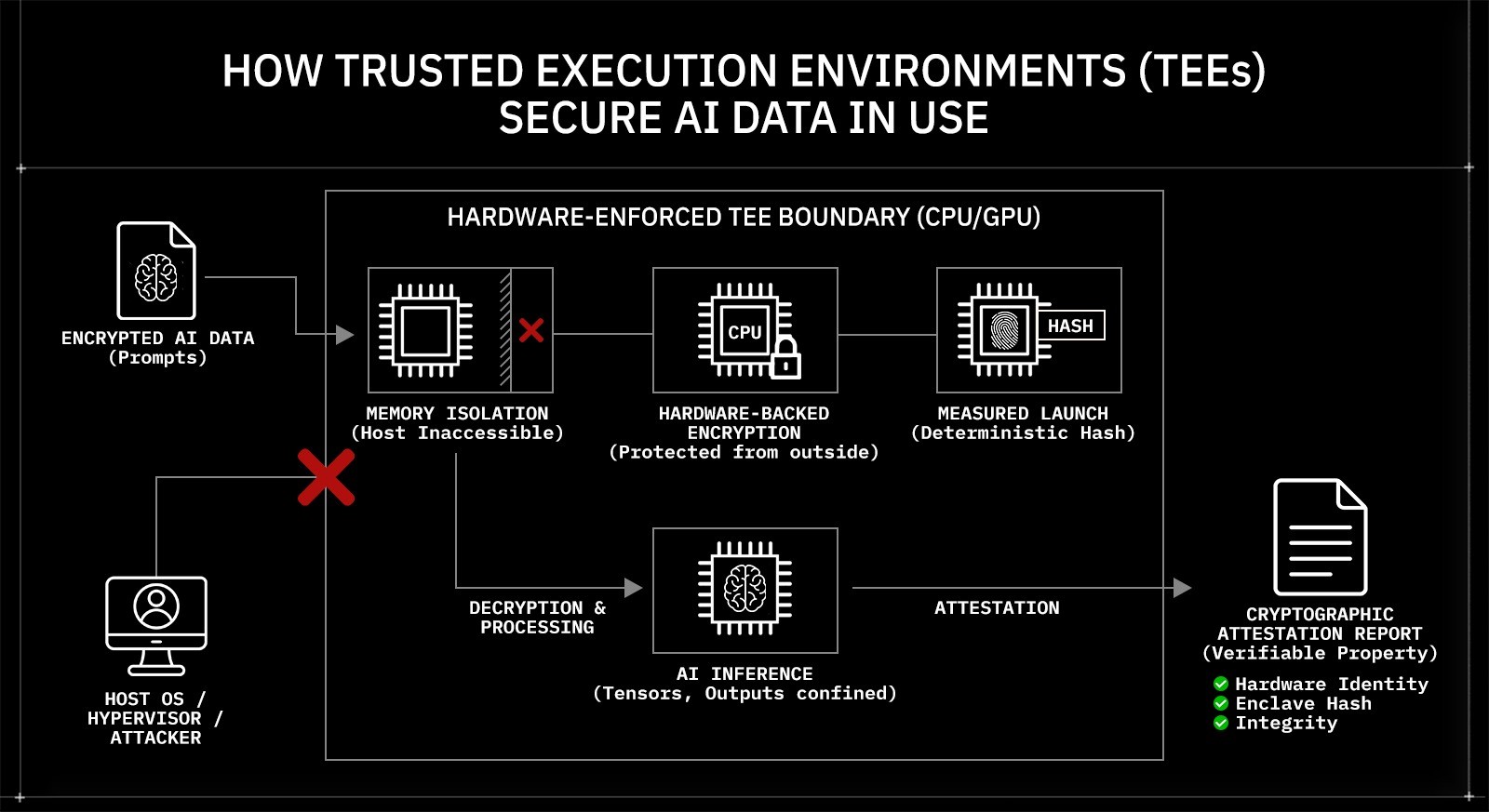
Enterprise AI systems require isolation during computation. Trusted Execution Environments (TEEs) provide that isolation by creating a hardware-enforced boundary around running code and its memory.
A TEE is a protected execution context implemented directly in the CPU or GPU. It isolates a workload inside an encrypted memory region that the host operating system, hypervisor, and other tenants cannot access. Memory pages assigned to the enclave are encrypted using hardware-managed keys that are not exposed to system software. Even if an attacker gains root access to the host, enclave memory remains unreadable.
TEEs enforce three foundational guarantees:
Memory isolation: Enclave memory cannot be accessed or modified by the host kernel, hypervisor, or co-tenant workloads.
Hardware-backed memory encryption: Data leaving the CPU package is encrypted, and plaintext exists only inside protected execution boundaries.
Measured launch: The enclave code and configuration are cryptographically measured at startup, producing a deterministic hash of the workload.
This directly addresses the runtime exposure problem. When an AI prompt is processed inside a TEE, decryption occurs only within the enclave. Intermediate tensors, embeddings, and generated outputs remain confined to protected memory during execution.
Cryptographic attestation extends this model beyond isolation. During attestation, the hardware signs a report containing the enclave measurement, platform identity, and configuration state. That report can be verified against a trusted root certificate chain. Enterprises can validate:
The hardware platform identity
The enclave measurement (hash of loaded code and configuration)
The integrity of the execution environment
Attestation transforms confidential computing from a claim into a verifiable property. Instead of trusting that an environment is secure, organizations can validate cryptographic evidence before relying on its output.
Trusted Execution Environments form the technical core of confidential AI. The next step is examining how these mechanisms are implemented across both CPU and GPU inference paths in production AI infrastructure.
How OLLM Uses Hardware-Backed Attestation to Protect CPU and GPU Inference
Trusted Execution Environments provide the isolation model. OLLM applies that model across both CPU and GPU layers of the inference path, exposing verifiable attestation evidence for each execution environment.
CPU-level isolation is implemented using Intel Trust Domain Extensions (TDX). Intel TDX creates hardware-protected virtual machines called trust domains. Memory assigned to a trust domain is encrypted with CPU-managed keys, and the hypervisor cannot read or modify it. Even with administrative privileges on the host, plaintext inside the trust domain remains inaccessible.
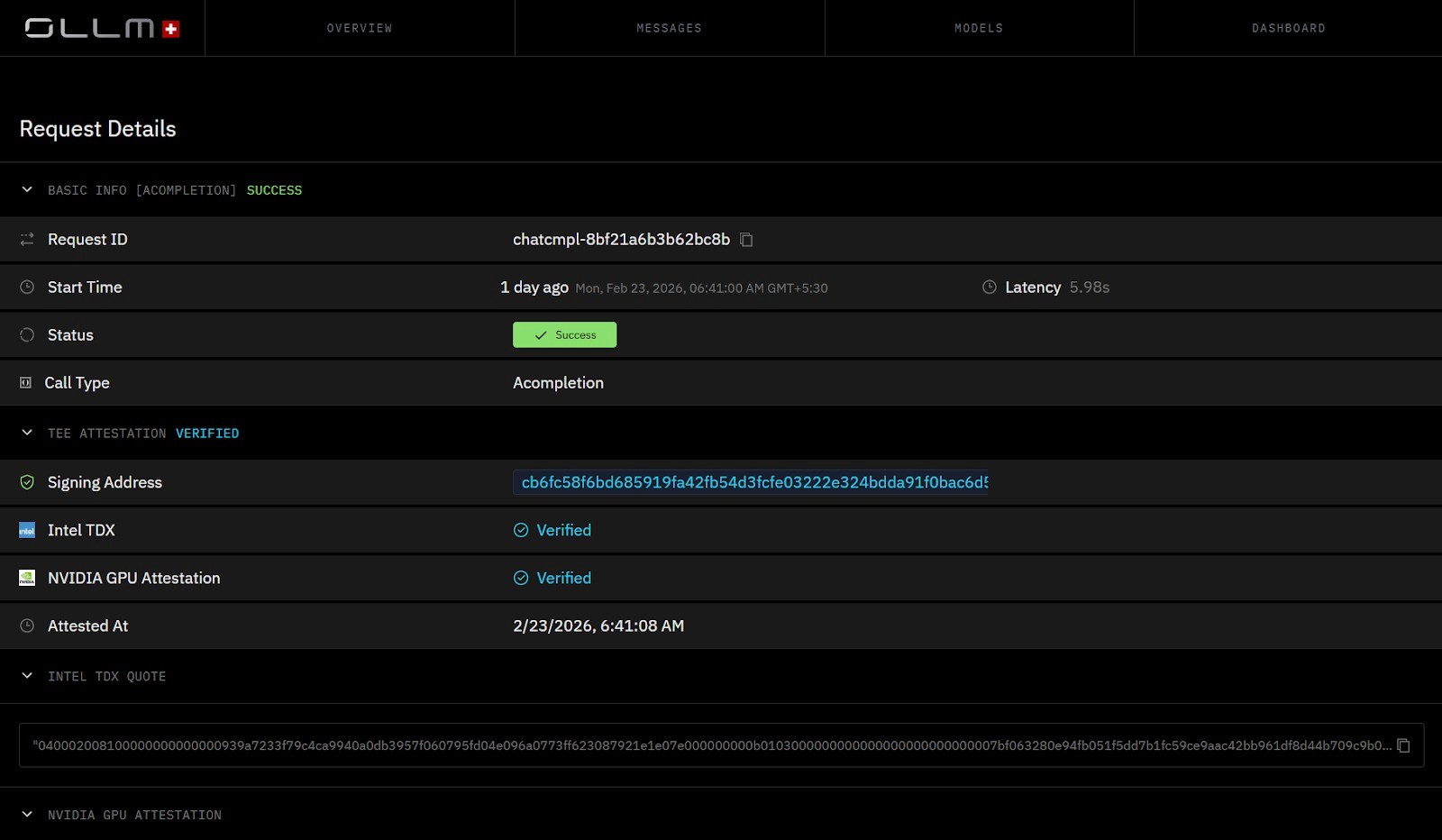
Within this TDX-backed environment:
Inference workloads execute inside encrypted guest memory
Host-level introspection of runtime memory is blocked
The virtual machine image is cryptographically measured at launch
A signed attestation report can be generated for verification
The attestation report includes measurements of the loaded workload and platform configuration. Enterprises can validate this report to confirm that the inference was executed inside an expected, untampered environment.
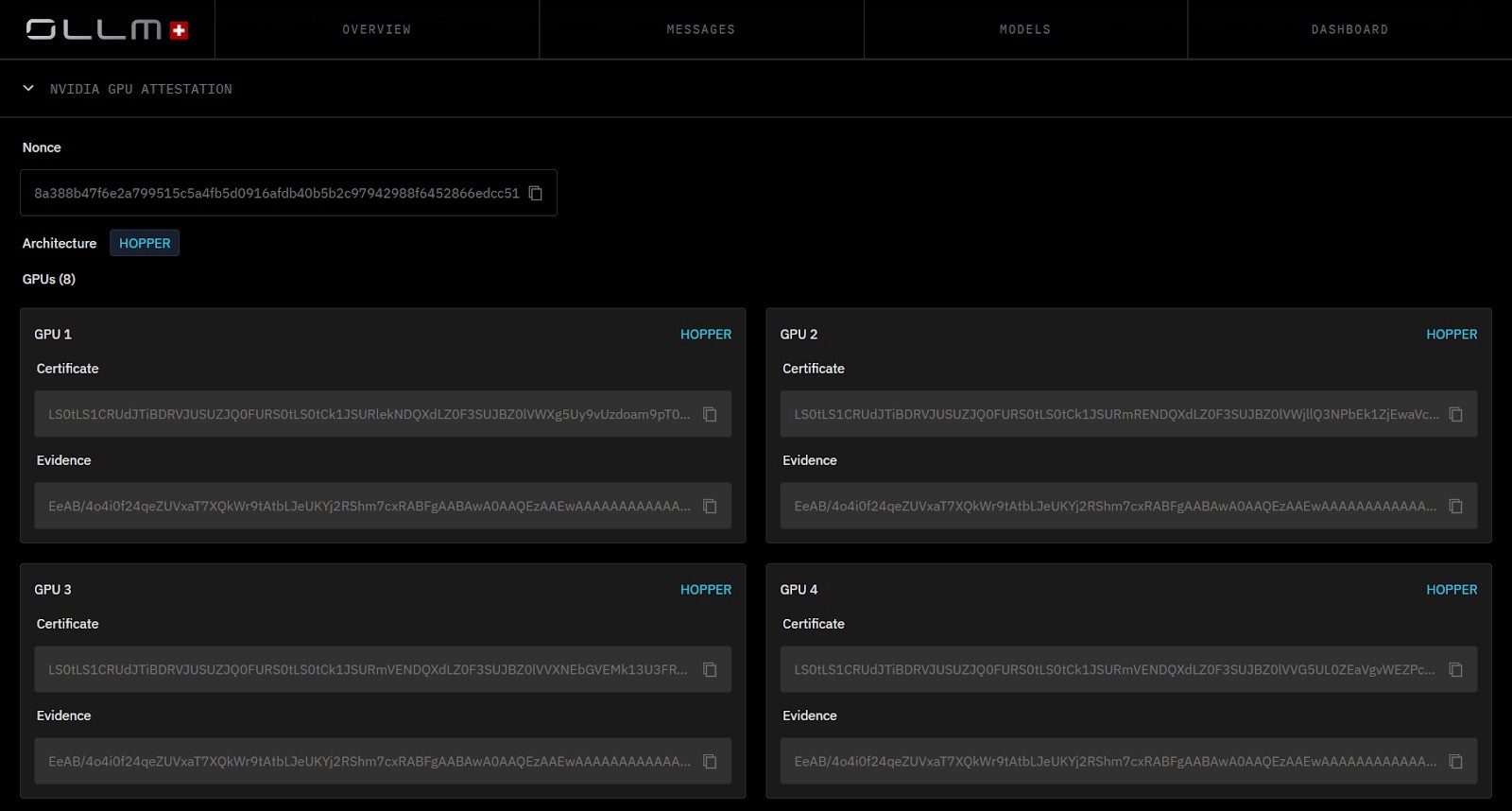
GPU-level validation is addressed using NVIDIA GPU attestation. Large language model inference depends heavily on GPU acceleration. Protecting only CPU memory leaves the GPU execution context as a potential point of exposure. NVIDIA GPU attestation provides hardware-backed verification of GPU firmware, driver state, and execution configuration. This ensures that the GPU participating in inference is operating in a verified and trusted state.
By combining:
Intel TDX for CPU memory encryption and isolation
NVIDIA GPU attestation for validated accelerator state
Cryptographic attestation reports are available for verification
OLLM provides visibility into the integrity of the full inference stack.
The calling application specifies which model to invoke. OLLM securely forwards the request to the selected confidential compute environment and exposes the relevant attestation artifacts. It does not dynamically select models or enforce automatic cutoffs; instead, it provides verifiable evidence that the compute environment met expected integrity conditions.
Confidential computing in this model becomes auditable. Execution integrity can be validated rather than assumed. With runtime isolation addressed, the remaining exposure surface lies in data persistence across infrastructure layers.
How Zero Data Retention Eliminates the “Hidden Database” Risk
Hardware isolation protects data during execution. Retention controls determine what remains after execution completes. Without strict retention boundaries, even in confidential compute environments, recoverable artifacts can persist.
In many AI deployments, prompts and responses traverse multiple subsystems: API gateways, reverse proxies, observability agents, tracing frameworks, and log aggregators. Debug-level logging may capture payload fields. Application performance monitoring tools may record request bodies. Centralized SIEM pipelines may ingest structured events. Even temporary buffers or message queues can persist sensitive content longer than intended.
Zero data retention changes this behavior at an architectural level. Under a zero-retention model:
Prompt payloads are not written to application logs
Response bodies are not stored in monitoring systems
No durable prompt/response content history is persisted at the gateway layer (metadata retention may still apply depending on configuration)
Telemetry excludes sensitive content fields
No retrievable corpus of prior AI interactions exists
This should be treated as an infrastructure default backed by enforceable configuration and policy guardrails, not just an application-level best practice.
If no prompt or response data is stored, there is no historical dataset to exfiltrate. A breach of logging infrastructure cannot expose past AI conversations if those conversations were never retained.
Zero retention also limits blast radius. At any given time, the only sensitive data present is data currently being processed within hardware-isolated environments. Once the request completes, no durable copy remains in downstream systems.
Runtime isolation addresses exposure during computation. Zero data retention addresses exposure after computation. Together, they remove the two primary layers where enterprise AI data typically accumulates risk.
How a Confidential AI Gateway Simplifies Multi-Model Security
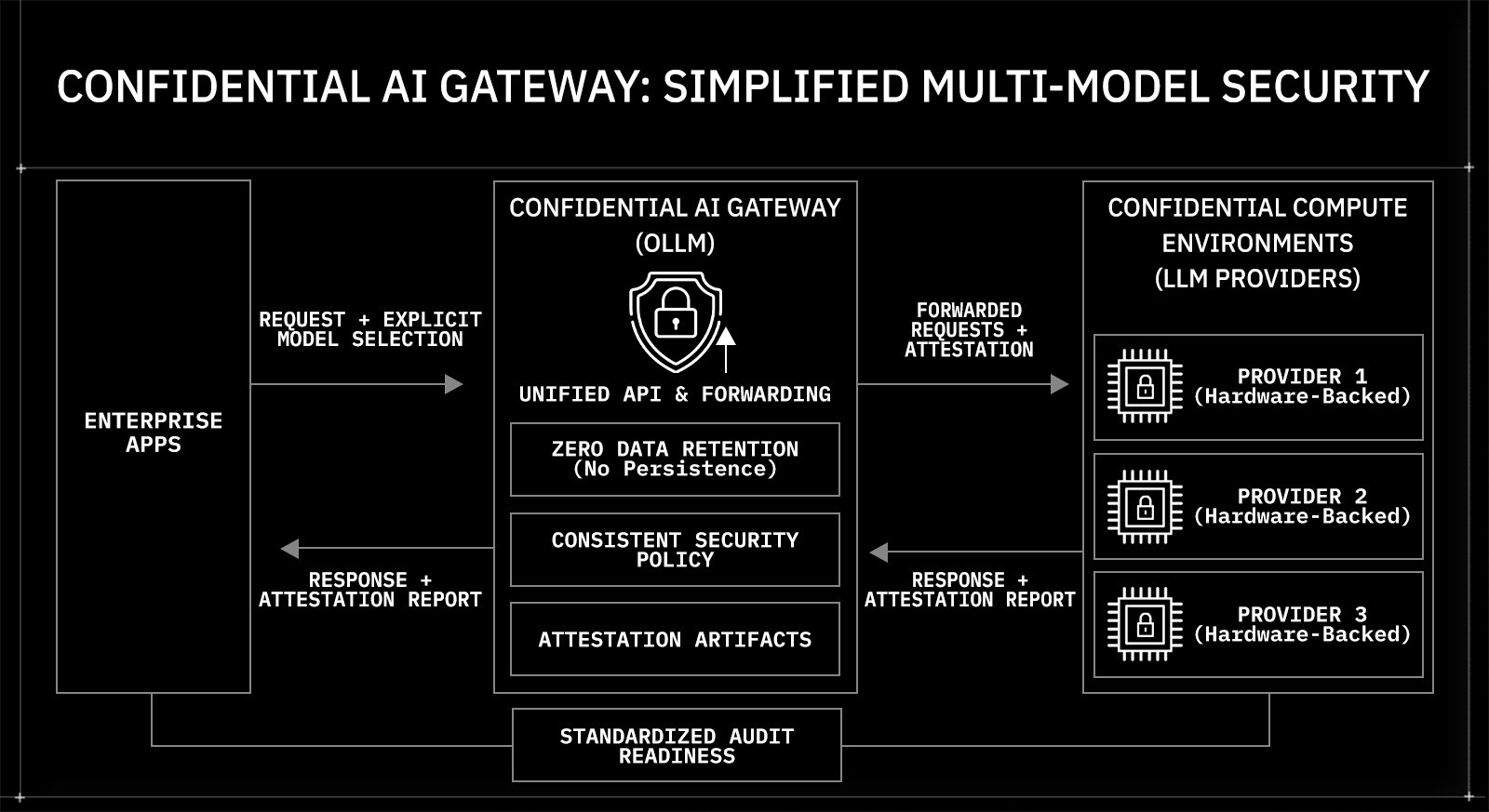
Runtime isolation and zero data retention reduce exposure at the compute and persistence layers. Enterprise AI environments, however, rarely operate with a single model provider. Organizations often integrate multiple LLM vendors to cover capabilities, ensure regional availability, or manage costs. Each integration introduces separate SDKs, authentication flows, logging defaults, and compliance assumptions. Over time, the security posture becomes fragmented.
A confidential AI gateway introduces a controlled integration layer without introducing centralized data storage. OLLM operates as a secure forwarding and verification layer between enterprise applications and LLM providers running on confidential compute infrastructure. Instead of building direct integrations to multiple providers, applications interact with a single API surface.
The calling application explicitly specifies which model to invoke in each request. OLLM forwards the request to the selected provider and exposes relevant attestation verification artifacts. It does not dynamically select, reroute, or optimize traffic across models. Model selection logic remains in the application layer.
This architectural model provides:
A unified API across providers
Consistent transport-layer encryption and request handling
Centralized enforcement of zero data retention constraints
Standardized access to attestation reports
Uniform policy application across integrations
Requests are transmitted securely to confidential compute environments that support hardware-backed isolation and GPU validation. Prompt payload persistence and observability content capture should be explicitly disabled through policy and configuration to preserve confidentiality guarantees.
By consolidating integration logic while preserving execution isolation, the gateway reduces configuration drift across providers. Security controls are applied consistently, and compliance evidence is exposed in a standardized format. The result is a single control plane for multi-model deployments without introducing dynamic routing complexity.
With integration standardized, the next consideration is how cryptographic attestation strengthens audit readiness in regulated environments.
Confidential AI as a Strategic Infrastructure Advantage
Scaling confidential AI addresses operational growth. The more significant impact is strategic. As AI systems become embedded in payment processing, clinical decision support, fraud detection, and internal knowledge workflows, infrastructure design begins to influence regulatory exposure and procurement outcomes.
Regulated industries no longer evaluate AI vendors solely on model quality or latency. They assess execution guarantees, data handling architecture, and auditability. Security architecture becomes part of due diligence. Questions shift from “How accurate is the model?” to “Where does inference execute?” and “What evidence exists that runtime environments are isolated?”
Confidential computing reshapes this evaluation. Hardware-backed memory encryption reduces the attack surface at the compute layer. Zero data retention eliminates the risk of data accumulation across observability and logging systems. Cryptographic attestation provides verifiable evidence of execution integrity rather than relying on contractual assurances.
This combination creates infrastructure-level differentiation. Organizations that can demonstrate runtime isolation and controlled data lifecycles reduce uncertainty for regulators, auditors, and enterprise buyers. Trust becomes grounded in measurable technical guarantees rather than policy language.
As AI adoption expands into high-sensitivity environments, execution integrity becomes as important as model performance. Confidential computing embeds privacy guarantees directly into the execution layer, making security a property of the architecture rather than an afterthought layered on top.
Conclusion: Building Enterprise AI on Verifiable Confidential Infrastructure
Enterprise AI now operates on data that regulators, customers, and boards consider mission-critical. Prompts may contain transaction records, protected health information, intellectual property, or internal strategic material. Protecting this data requires more than perimeter security and encrypted transport. It requires guarantees at two layers: isolation during execution and elimination of persistent data artifacts after execution. Confidential computing addresses both by combining hardware-enforced memory isolation, cryptographic attestation of execution environments, and strict zero-data-retention controls.
Confidential infrastructure is increasingly expected in regulated environments. OLLM integrates Intel TDX-based isolation, NVIDIA GPU attestation, and standardized attestation reporting, with retention controls that can be enforced across the inference path. Applications explicitly select their target models, while OLLM forwards requests securely and exposes verifiable execution artifacts. Organizations deploying AI in high-sensitivity environments can assess OLLM to implement hardware-backed, auditable protection from request submission through verified inference execution.
FAQ
1. What is confidential computing in AI workloads?
Confidential computing in AI refers to protecting data during inference by using encryption. It ensures that prompts, embeddings, and model outputs remain protected as they are processed in memory within Trusted Execution Environments (TEEs). Unlike encryption at rest or in transit, confidential computing isolates runtime memory using hardware-backed enclaves and cryptographic attestation.
2. How does Trusted Execution Environment (TEE) attestation work in enterprise AI?
TEE attestation provides cryptographic proof that an AI workload is running within a verified, unmodified hardware enclave. The hardware signs measurements of the enclave configuration and loaded code. Enterprises can validate attestation reports as part of a defined trust policy, either pre-request when tightly integrated, or post-request before accepting the results, to confirm that inference is executed within an expected, integrity-verified environment.
3. Why is zero data retention important for secure LLM deployments?
Zero data retention eliminates stored prompt and response history. Many AI systems log interactions for debugging or analytics, creating datasets that can be retrieved. In secure LLM deployments, eliminating persistent logging reduces breach surface area and removes the “hidden database” risk. If no prompt data is stored, it cannot be exfiltrated later.
4. How does OLLM use Intel TDX and NVIDIA GPU attestation to secure AI inference?
OLLM integrates Intel TDX to isolate CPU-level execution inside encrypted trust domains and uses NVIDIA GPU attestation to verify GPU-bound LLM inference workloads. This combination secures both CPU and GPU execution paths. Cryptographic TEE attestation proofs allow enterprises to validate that inference runs inside hardware-isolated, verified environments.
5. How does OLLM’s confidential AI gateway support multi-model enterprise deployments?
OLLM’s confidential AI gateway provides a single API endpoint through which applications send requests to specified confidential LLM providers. The calling application selects the model. OLLM handles secure forwarding, attestation verification, and zero-retention enforcement across requests. It provides configurable zero-retention controls, hardware-backed isolation, and attestation-backed execution evidence across models. This centralized architecture reduces fragmentation while maintaining verifiable privacy and alignment with compliance requirements.
"/><stop offset="1" stop-color="rgb(80, 78, 87)"/></linearGradient></defs><g d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z M 142.346 0.381 L 162 0.381 L 162 20 L 142.346 20 Z M 153.986 8.381 L 158.375 8.381 L 158.375 12 L 153.986 12 L 153.986 16.571 L 150.36 16.571 L 150.36 12 L 145.972 12 L 145.972 8.381 L 150.36 8.381 L 150.36 4.19 L 153.986 4.19 Z" fill="transparent" height="20px" id="cWM2PbaAz" width="162.00000833847133px"><path d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z" fill="url(%23UyELkL66Q-1582027827-linear-gradient)" height="20px" id="UyELkL66Q" width="134.52277004415487px"/><path d="M 0 0 L 19.654 0 L 19.654 19.619 L 0 19.619 Z" fill="rgb(176, 0, 0)" height="19.618991595424752px" id="t30DbKa7C" transform="translate(142.346 0.381)" width="19.653710120697895px"/><path d="M 8.014 4.19 L 12.403 4.19 L 12.403 7.81 L 8.014 7.81 L 8.014 12.381 L 4.389 12.381 L 4.389 7.81 L 0 7.81 L 0 4.19 L 4.389 4.19 L 4.389 0 L 8.014 0 Z" fill="rgb(255, 255, 255)" height="12.380917026238919px" id="bLcZkJmGc" transform="translate(145.972 4.19)" width="12.402826775197639px"/></g></svg>)