|

TL;DR
Enterprise AI infrastructure failures are rarely dramatic; they build quietly through deferred security decisions, unreviewed data retention defaults, and single-provider dependencies that were never designed for production scale.
Without hardware-level isolation and cryptographic TEE attestation (backed by Intel TDX and NVIDIA GPU attestation), there is no verifiable evidence that inference ran in a trusted, unmodified environment.
Prompt and response data that is stored without a deliberate decision to do so becomes a breach surface. Zero-retention defaults at the gateway layer eliminate that risk without sacrificing billing or observability.
Single-provider dependencies, per-provider compliance management, and reactive scaling all compound into the same problem: infrastructure that cannot absorb production pressure without breaking
OLLM addresses all five failure patterns through a unified confidential AI gateway, TEE-backed execution paths, configurable zero-retention controls, cryptographic attestation proofs, and access to hundreds of models behind a single API with centralized quota visibility and compliance controls
AI adoption inside enterprises is accelerating faster than the infrastructure supporting it. Teams are shipping LLM-powered features, connecting to new model providers, and expanding use cases, often on top of the same lightweight setup they used to test a prototype six months ago.
That gap between how fast AI is moving and how slowly infrastructure matures is where most production failures begin. Not dramatically, but quietly, a misconfigured provider leaking prompt data, a single API dependency going down mid-demo, a compliance audit flagging uncontrolled data retention nobody thought to address.
The mistakes driving these failures aren't exotic. They're patterns that appear repeatedly across teams at every stage of AI maturity, and they cluster around three pressure points: security, data handling, and operational resilience.
This blog breaks down the five most common AI infrastructure mistakes enterprises make, and shows exactly how OLLM's confidential AI gateway is built to solve them at the infrastructure layer, where they actually need to be solved.
The Five Most Common AI Infrastructure Mistakes
Most AI infrastructure problems don't announce themselves. They build quietly in the background while teams are focused on shipping, and by the time they surface, they've already compounded into something harder to fix.
The root cause is usually the same: infrastructure decisions made at the prototype stage that never got revisited when things moved to production. A single provider dependency that felt fine at 100 requests a day becomes a liability at 100,000. A decision to skip attestation may seem harmless until a compliance audit requests proof of execution. The prompt data that "wasn't being stored" turns out to have been accumulating in logs that nobody was watching.

The five mistakes below highlight the most common failure patterns observed across enterprise AI deployments. They span security, data handling, and operational resilience, the three layers where infrastructure debt tends to hit hardest.
The five mistakes are:
Running inference with no hardware-level isolation or attestation
Persisting prompt and response data without a clear reason to
Depending on a single provider with no fallback strategy
Managing compliance and security separately per provider
Scaling reactively instead of building for load from the start
Each section below explains what the mistake looks like in practice, why it becomes more dangerous as usage grows, and how OLLM addresses it at the infrastructure layer.
Mistake 1: Running Inference With No Hardware-Level Isolation or Attestation
Most teams connecting to an LLM provider have no way to verify what actually happens to their prompts once they leave the application. The request goes out, a response comes back, and everything in between is a black box.
For internal tools, that ambiguity is tolerable. For enterprise workloads handling sensitive data, it isn't.
Why this is riskier than it looks:
Standard cloud inference runs on shared hardware. Without hardware-level isolation, there is no technical guarantee that your workload is fully separated from co-tenant workloads on the same physical infrastructure. Hardware-backed isolation reduces the risk of certain co-tenant and host-access threats on shared infrastructure, but only within the TEE threat model. In regulated environments, the inability to prove execution integrity is itself a compliance failure, regardless of whether a breach actually occurred.
What the fix looks like:
Trusted Execution Environments (TEEs) create hardware-isolated environments where inference runs independently of the host OS and other tenants. More importantly, TEE-backed execution can enable cryptographic attestation. Depending on the stack, technologies such as Intel TDX (for the confidential VM) and NVIDIA GPU attestation (for the GPU/device state) can generate evidence about the execution environment, including:
The confidential VM/workload measurement matches the expected values defined in the attestation policy, confirming the environment has not been tampered with
That the workload ran in a TEE-backed environment consistent with the policy
That the host can't directly read guest memory (within the TEE threat model)
Optionally, device/GPU claims when GPU attestation is available
How OLLM addresses this:
Every model available through OLLM runs on confidential hardware, with inference running in hardware-isolated environments backed by Intel TDX. Attestation artifacts are made available to enterprises so they can validate execution integrity as part of their trust policy.
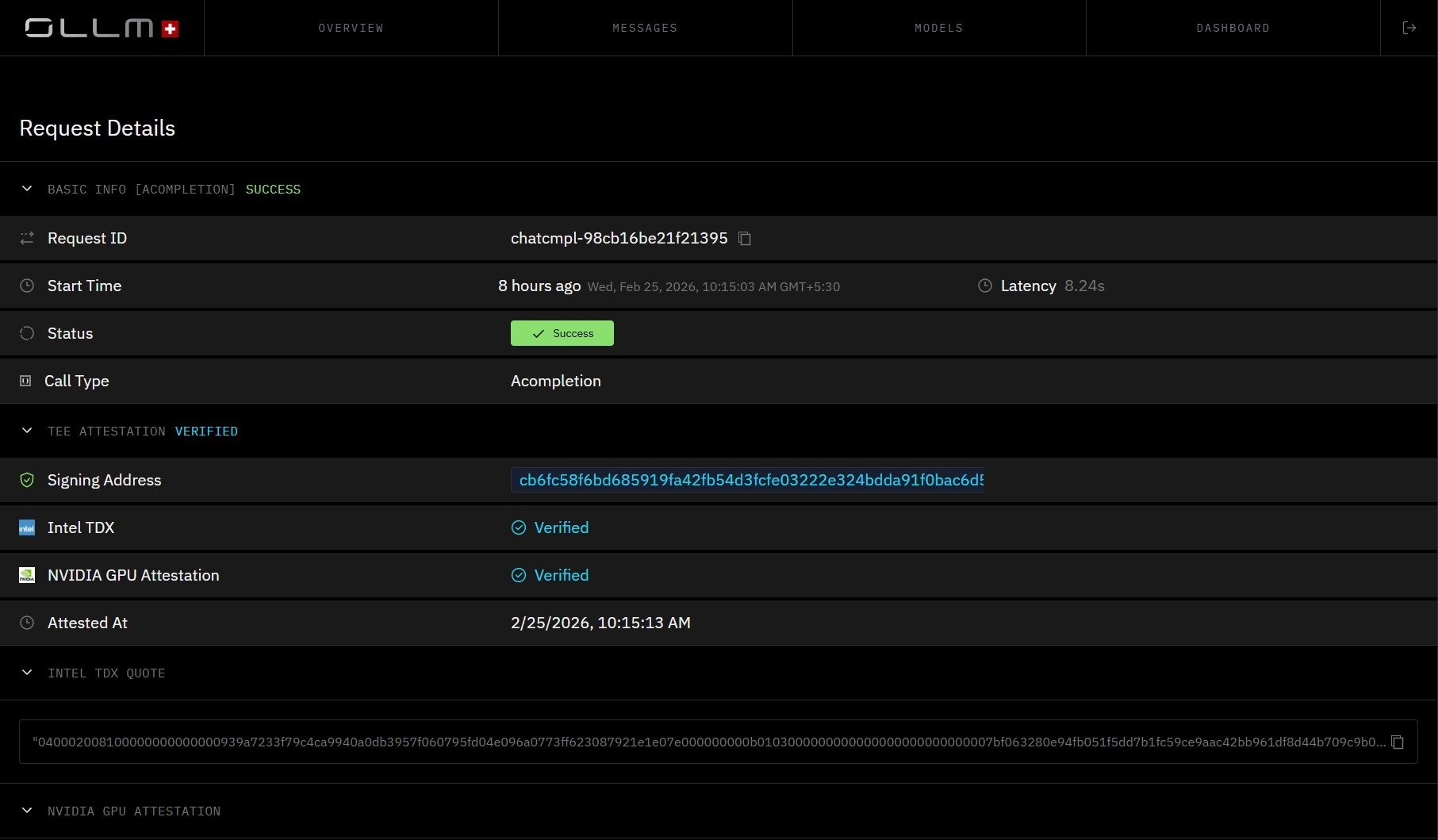
Per-request attestation details: Intel TDX and NVIDIA GPU Attestation both appear as Verified, with cryptographic signing addresses and attestation timestamps. This is what verifiable execution integrity looks like at the request level, not a policy document.
All requests are routed to a secure TEE-backed execution environment. Attestation artifacts are made available to enterprises so they can validate execution integrity as part of their trust policy, typically before provisioning secrets (and, in some designs, before sending sensitive prompts), and/or before accepting results.
This shifts attestation from a manual compliance exercise into a verifiable, infrastructure-backed process, replacing trust-based claims with cryptographically verifiable evidence about the execution environment.
Mistake 2: Persisting Prompt and Response Data Without a Clear Reason To
Data you don't store can't be stolen. It sounds obvious, but most AI infrastructure setups default to retaining prompt and response content without anyone explicitly deciding to keep it. It just accumulates, in logs, in spend records, in observability pipelines, creating a breach surface that didn't need to exist.
The risk isn't hypothetical. Any durable store of prompt-and-response content is a target. The larger and older the store gets, the more valuable it becomes to an attacker and the harder it becomes to audit, control, or purge.
Where teams typically go wrong:
Logging is enabled by default and never revisited
Prompt content ends up captured inside observability or cost-tracking pipelines
There is no gateway-level policy enforcing what gets stored and what doesn't
The assumption is that the provider handles data hygiene, when in reality, no one does
How OLLM addresses this:
OLLM defaults to not storing prompt and response content at the gateway layer. There is no growing database of inference exchanges for an attacker to target or for a compliance audit to flag.
A few important clarifications on how this works in practice:
Layer | What gets retained by default |
Prompt and response content | Not stored by default |
Usage metadata (tokens, cost, timestamps) | May still be logged |
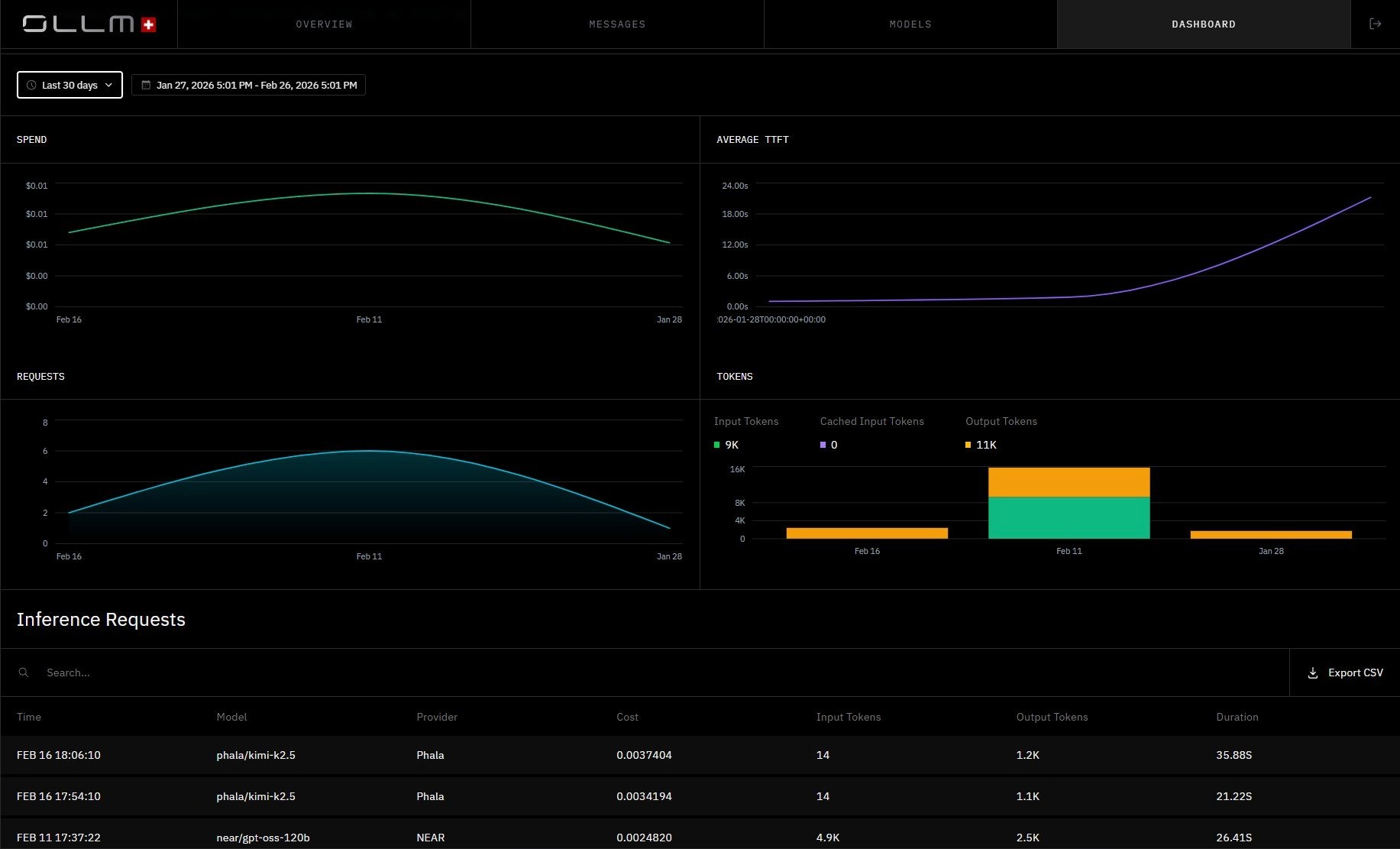
OLLM Dashboard, spend, token consumption, TTFT, and request volume are all tracked centrally. No prompt or response content appears here. This is what zero-retention-by-default observability looks like: full operational visibility with no inference content stored.
This means zero retention at OLLM refers specifically to prompt and response content. Operational metadata may still be retained for billing, reliability, or audit workflows, depending on configuration. Prompt and response content is not stored by default. Operational metadata may still be retained for billing and reliability workflows, depending on configuration, and OLLM's configuration makes that enforceable at the infrastructure layer rather than leaving it as an application-level best practice.
Mistake 3: Depending on a Single Provider With No Fallback Strategy
Starting with a single LLM provider makes sense at the prototype stage. One API key, one integration, move fast. The problem is that most teams never revisit that decision when they move to production, and a single provider dependency that felt fine at low volume becomes a serious liability at scale.
Provider outages happen. Rate limits get hit. Latency spikes at the worst possible moment. When your entire AI layer routes through a single endpoint, any of these events becomes your problem immediately, with no buffer or fallback.
What this looks like when it breaks:
A provider goes down during a customer-facing workflow with no automatic rerouting
Rate limits are hit mid-scale, and there is no overflow path
A provider degrades in latency, and there is no way to shift the load elsewhere
Cost spikes on one provider with no visibility or routing alternative
How OLLM addresses this:
OLLM provides a unified API across dozens of models and two providers. Rather than managing multiple integrations separately, model selection can be driven by the app, policy, or a hybrid approach. For example, the application specifies a model alias while the gateway handles execution policy across deployments. Switching from one model to another, or routing around a degraded provider, requires no application-layer changes:
Python, switching providers without changing your integration
from openai import OpenAI |
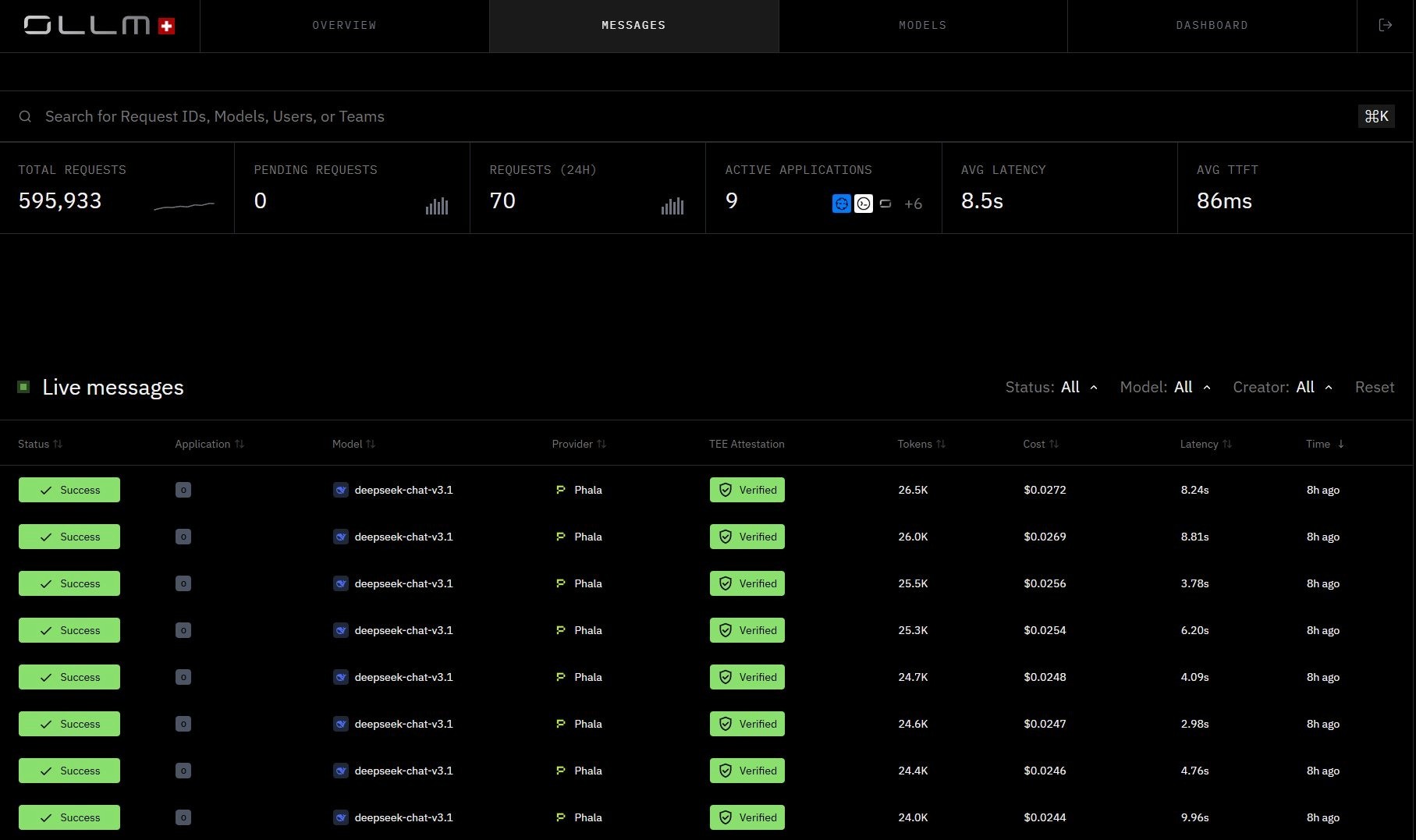
OLLM Messages view, requests across both Phala and NEAR providers, each with TEE Attestation Verified. With all models accessible through a single API, switching providers requires only a model string change, no integration rewrite, no new authentication setup, no application-layer refactoring.
At the routing layer, OLLM handles:
Access to multiple providers through a single API with no per-provider integration overhead
Centralized quota and usage visibility across all models and providers
Provider switching requires only a model string change, with no application-layer changes required
Mistake 4: Managing Compliance and Security Separately Per Provider
Every new LLM provider an enterprise connects to adds a new compliance surface. New authentication setup, new data handling terms to review, new logging behavior to audit, new security controls to verify. At one or two providers, this is manageable. At five or ten, it becomes a sprawling, inconsistent mess that no single team fully owns.
The deeper problem is that compliance controls enforced at the application layer are fragile. They depend on individual developers making the right decisions consistently, across every integration, every time. That's not a reliable foundation for regulated environments.
What this looks like in practice:
Each provider has different auth, logging, and retention behavior, with no central view
Security reviews have to be repeated per provider, with no shared baseline
Compliance controls are application-level assumptions rather than infrastructure-configurable policy
A new provider gets added quickly, and the compliance review never catches up
How OLLM addresses this:
OLLM centralizes provider communication behind a single confidential AI gateway. Instead of managing compliance separately for each provider, security and retention controls are enforced at the gateway layer consistently across all models and requests. Here's what that looks like using the same API call format regardless of which provider or model is selected:
cURL, one API, consistent compliance controls across all providers
curl https://api.ollm.com/v1/chat/completions -H "Content-Type: application/json" -H "Authorization: Bearer your-api-key" -d '{ |
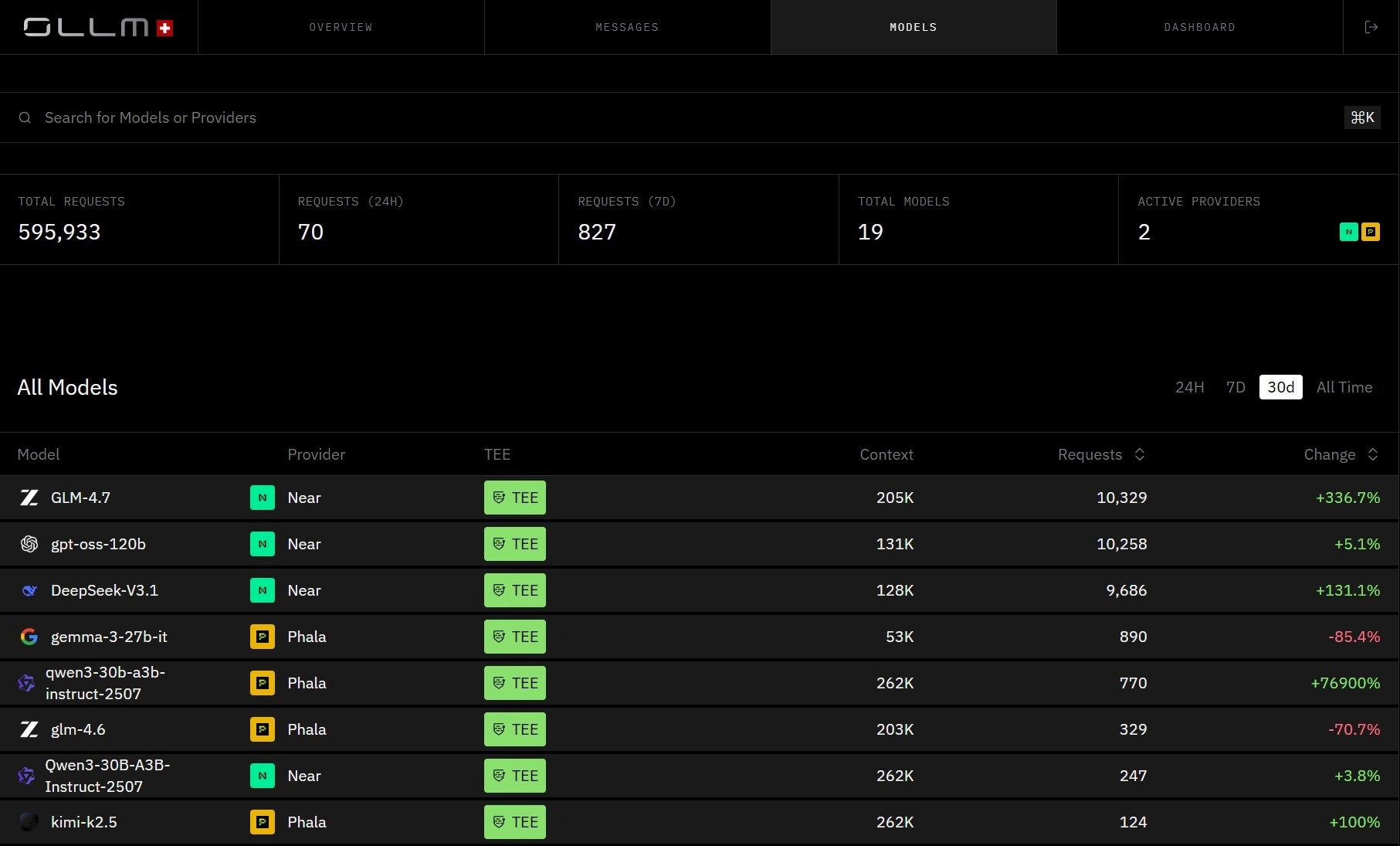
OLLM Models view, every model across every provider is visible in one place, with TEE status, context window, and request volume surfaced per model. This is the unified compliance surface: one gateway, one policy layer, no per-provider audit sprawl.
Specifically, OLLM provides:
Centralized observability and cost tracking across all providers through one API
Configurable retention and logging controls can be enforced at the gateway, not the application
TEE-backed execution across all models, with attestation artifacts available for audit
Hardware-backed isolation via Intel TDX-based confidential-VM isolation and NVIDIA GPU attestation across all models
Confidential infrastructure is increasingly expected in regulated environments. OLLM integrates these controls at the infrastructure layer so compliance controls are configurable by policy rather than dependent on application-level discipline.
Mistake 5: Scaling Reactively Instead of Building for Load From the Start
Scaling problems in AI infrastructure rarely announce themselves in advance. The more common pattern is that usage grows steadily, everything feels fine, and then a spike in traffic or a new product launch suddenly exposes the limits of an infrastructure that was never built to absorb load gracefully.
By that point, the options are limited. Scrambling to add providers, renegotiate rate limits, or refactor routing logic under pressure is exactly the kind of reactive scaling that creates new failure points while trying to fix old ones.
What reactive scaling typically looks like:
Rate limits are discovered when they are hit, not before
Adding a new provider to handle overflow requires a new integration from scratch
There is no central view of quota usage across providers to anticipate bottlenecks
Capacity planning is guesswork because usage data lives in multiple disconnected places
How OLLM addresses this:
OLLM handles scaling through centralized quota enforcement and visibility, meaning usage data across all models and providers is tracked in one place rather than scattered across disconnected dashboards.
In practical terms, scaling with OLLM looks like:
Usage stays visible through centralized observability and cost tracking across all providers
Adding a new provider requires only a model string change, not a new integration
Higher capacity needs can be addressed by contacting sales to discuss reserving capacity for the expected load
This turns scaling from a reactive crisis into a managed infrastructure concern handled at the gateway layer.
What Solid AI Infrastructure Looks Like When You Get It Right
The five mistakes above share a common thread: they all stem from infrastructure decisions that were deferred, delegated to the application layer, or simply never made. The fix in each case isn't a new tool bolted on top; it's getting the foundation right so that security, compliance, and resilience can be enforced by default through configuration rather than hoped for.
Solid AI infrastructure in a production enterprise environment looks like this:
At the security layer:
Inference runs in hardware-isolated environments with cryptographic attestation evidence available on demand, covering VM identity, workload integrity, and GPU state
Execution integrity is verifiable, not assumed, backed by Intel TDX-based confidential-VM isolation and NVIDIA GPU attestation across all models
Attestation evidence can be validated as part of a trust policy, typically before provisioning secrets or sending sensitive prompts, and/or before accepting results
At the data layer:
Prompt and response content is not persisted by default at the gateway layer
Retention and logging behavior are enforced by configuration and policy, not left to individual application decisions
Operational metadata, tokens, cost, and timestamps are tracked for billing and reliability, while prompt and response content is not stored by default
At the operational layer:
A single API covers hundreds of models and providers with no per-provider integration overhead
Provider switching, quota visibility, and compliance controls are centralized at the gateway layer
Compliance controls are centralized, consistent, and auditable across every provider and every request
This is the infrastructure posture OLLM is built around, a unified confidential AI gateway that provides TEE-backed execution paths, configurable zero-retention controls, attestation artifacts, and centralized routing across models, with retention and logging behavior enforced by policy rather than left as application-level assumptions.
Conclusion: Infrastructure Confidence Is a Competitive Advantage
AI infrastructure mistakes rarely announce themselves. They accumulate quietly, in unverified execution environments, in prompt data nobody realized was being stored, in provider dependencies that held up fine until they didn't. The five mistakes covered in this blog share a common thread: they all stem from infrastructure decisions that were deferred or never made, and they all become significantly harder to fix once they've compounded in production.
To see how OLLM's confidential AI gateway addresses these at the infrastructure layer, TEE-backed execution, configurable zero-retention controls, centralized routing, and cryptographic attestation evidence across hundreds of models, visit ollm.com and get started.
FAQs
1. What is TEE attestation, and why does it matter for enterprise AI workloads?
TEE attestation is a cryptographic process that generates verifiable proof about an execution environment's identity and integrity. For enterprise AI, it means you can confirm that inference ran inside an unmodified, hardware-isolated enclave rather than taking it on trust. In regulated industries, this proof is increasingly required as a compliance baseline rather than just a security enhancement.
2. What is the difference between zero data retention and zero knowledge in AI infrastructure?
Zero data retention means prompt and response content is not persisted at the gateway or provider layer. Zero-knowledge refers to cryptographic protocols in which a system can verify something without accessing the underlying data. In practice, enterprise AI infrastructure needs both: zero retention reduces the breach surface, while a zero-knowledge architecture ensures that even the infrastructure operator cannot read inference content.
3. How does OLLM handle zero data retention without breaking billing and observability?
OLLM separates content from metadata. Prompt and response content is not stored by default at the gateway layer, while operational metadata, tokens used, cost, and timestamps are still tracked for billing and reliability. Prompt and response storage is off by default and not retained unless explicitly configured, meaning retention controls can be enforced by policy without losing the observability needed to run production workloads.
4. What is Intel TDX, and how does it differ from standard cloud isolation?
Intel TDX (Trust Domain Extensions) creates hardware-isolated virtual machines called Trust Domains that are protected from the host operating system, hypervisor, and other tenants. Standard cloud isolation relies on software-level separation, which cannot provide the same cryptographic guarantees. TDX-backed inference environments generate attestation reports that can be independently verified, unlike standard cloud isolation.
5. How does AI gateway routing differ from a standard API proxy?
A standard API proxy forwards requests without any additional layer. An AI gateway adds execution policy enforcement, privacy controls, centralized observability, and unified access to multiple models and providers through a single API. With OLLM specifically, every request also runs inside a hardware-isolated TEE with per-request cryptographic attestation, which no standard proxy provides.
"/><stop offset="1" stop-color="rgb(80, 78, 87)"/></linearGradient></defs><g d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z M 142.346 0.381 L 162 0.381 L 162 20 L 142.346 20 Z M 153.986 8.381 L 158.375 8.381 L 158.375 12 L 153.986 12 L 153.986 16.571 L 150.36 16.571 L 150.36 12 L 145.972 12 L 145.972 8.381 L 150.36 8.381 L 150.36 4.19 L 153.986 4.19 Z" fill="transparent" height="20px" id="cWM2PbaAz" width="162.00000833847133px"><path d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z" fill="url(%23UyELkL66Q-1582027827-linear-gradient)" height="20px" id="UyELkL66Q" width="134.52277004415487px"/><path d="M 0 0 L 19.654 0 L 19.654 19.619 L 0 19.619 Z" fill="rgb(176, 0, 0)" height="19.618991595424752px" id="t30DbKa7C" transform="translate(142.346 0.381)" width="19.653710120697895px"/><path d="M 8.014 4.19 L 12.403 4.19 L 12.403 7.81 L 8.014 7.81 L 8.014 12.381 L 4.389 12.381 L 4.389 7.81 L 0 7.81 L 0 4.19 L 4.389 4.19 L 4.389 0 L 8.014 0 Z" fill="rgb(255, 255, 255)" height="12.380917026238919px" id="bLcZkJmGc" transform="translate(145.972 4.19)" width="12.402826775197639px"/></g></svg>)