|

TL;DR
Direct OpenAI integration works for prototypes but breaks down at enterprise scale, with no privacy guarantees, no attestation, no fallback, and no unified compliance layer.
Alternatives like competitor APIs and cloud AI services close some gaps but still rely on contractual trust rather than cryptographic, hardware-verifiable execution evidence.
Self-hosted models give you data locality but trade the vendor-trust problem for significant infrastructure and compliance overhead.
AI gateways are the most complete enterprise alternative, handling routing, execution policy, zero-retention controls, and observability in a single layer without re-architecting your application.
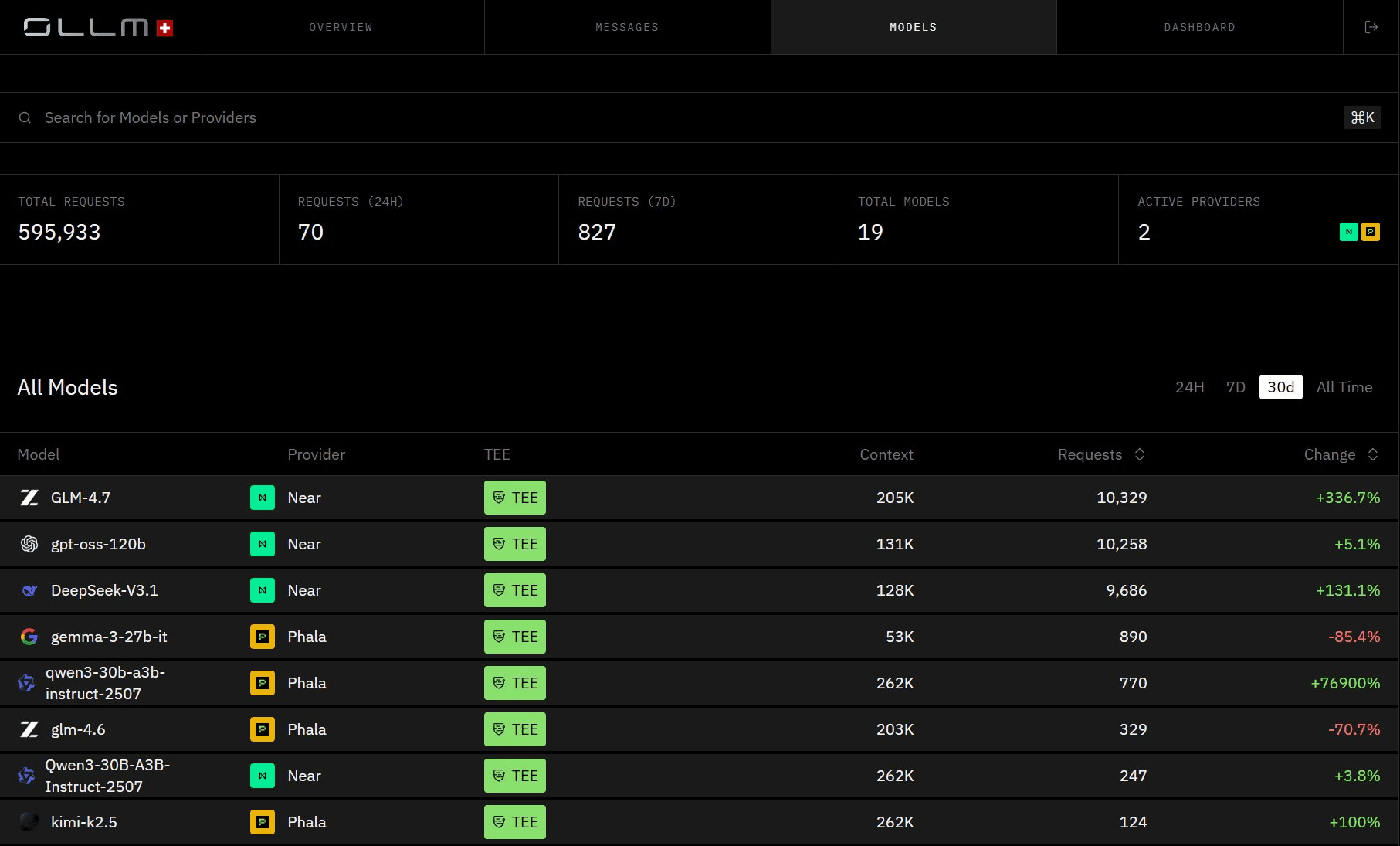
OLLM goes further than standard gateways with default zero-retention controls, Intel TDX-based confidential-VM isolation, NVIDIA GPU attestation, and cryptographic TEE attestation evidence across hundreds of models behind one OpenAI-style, OpenAI-SDK-compatible API
Enterprise AI adoption usually follows the same pattern. A team picks OpenAI, gets an API key, and ships something that works. It's fast, it's familiar, and the models are good enough to get stakeholder buy-in. Before long, that same pattern is replicated across teams, each with its own keys, its own integrations, and its own assumptions about what's safe to send over the wire.
At scale, that approach breaks down. Compliance teams start asking questions about where data goes. Security teams flag the lack of isolation guarantees. Engineering teams hit rate limits with no fallback. And leadership realizes there's no unified view of what the AI stack is actually costing. Direct OpenAI integration got the project started, but it was never designed to carry enterprise workloads.
Why Direct OpenAI Integration Falls Short for Enterprises
Direct OpenAI integration is the default starting point for most AI projects, and for good reason. The API is well-documented, the models are capable, and you can go from zero to a working prototype in an afternoon. But for production enterprise deployments, that simplicity comes with serious trade-offs.
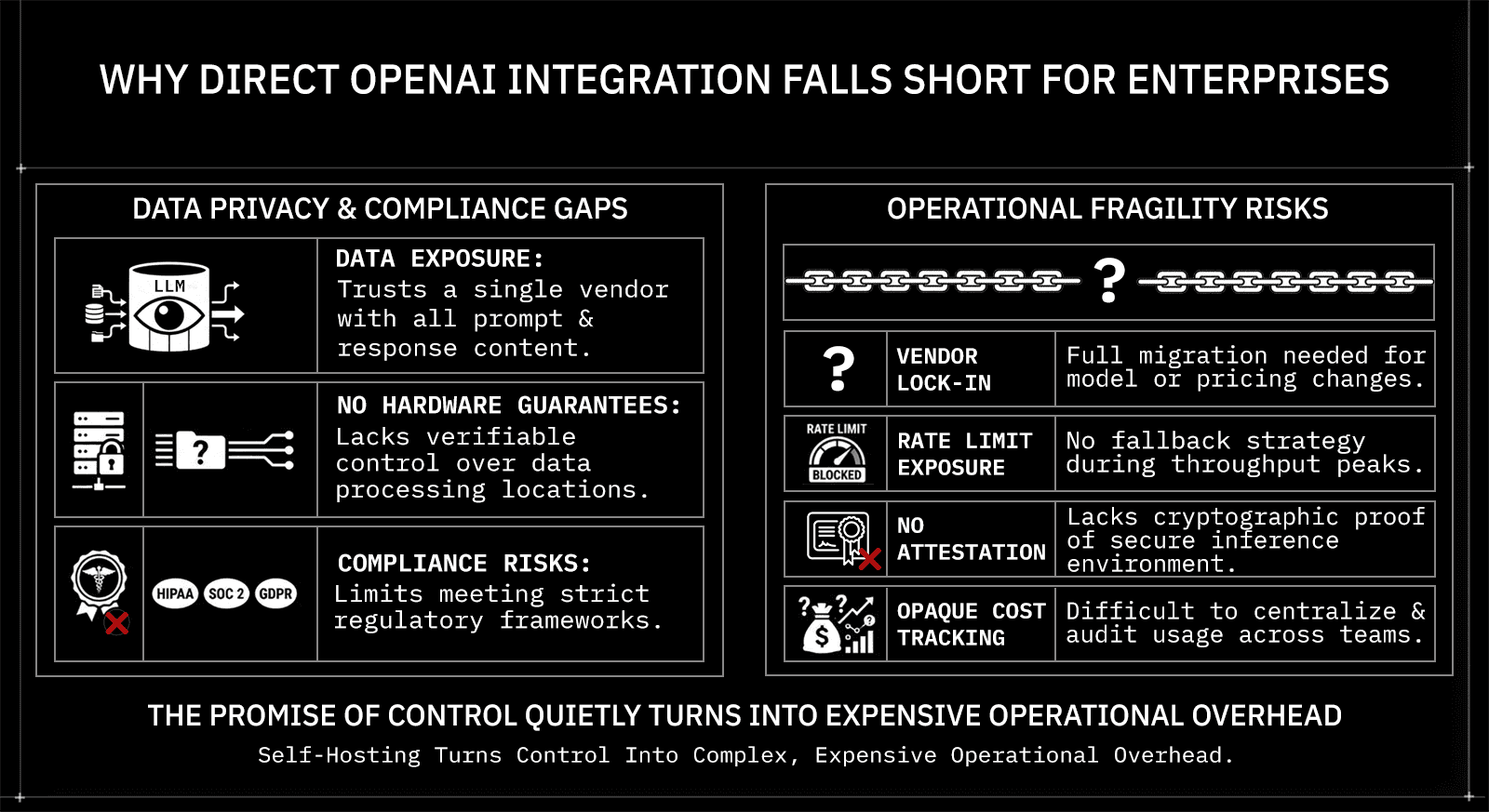
The core problem is that direct integration means trusting a single vendor with your entire inference stack. OpenAI sees every prompt and response. There are no hardware-level verifiable assurances about where your data is processed or by whom it can be accessed. For teams operating under HIPAA, SOC 2, GDPR, or financial compliance frameworks, that's not a gap you can paper over with a terms-of-service checkbox.
Beyond privacy, there's the operational fragility. A single API means:
Vendor lock-in: model deprecations or pricing changes require a full migration
Rate limit exposure: no fallback when you hit throughput ceilings
No attestation: no cryptographic proof that inference ran in a secure, isolated environment
Opaque cost tracking: usage across teams or products is hard to centralize and audit
The alternative isn't abandoning OpenAI-compatible models. It's changing how you connect to them, and that's where the architecture conversation starts.
What to Look for in an OpenAI Alternative
Not every alternative solves the same problems. Some give you model flexibility but no privacy guarantees. Others offer compliance tooling but still depend on cloud-level trust. Before evaluating options, it helps to have a clear set of criteria.
For enterprise deployments, the key questions are:
Criteria | Why It Matters |
Data privacy | Are prompts and responses stored? By whom? Where? |
Hardware-level isolation | Is inference running in a verifiable, isolated environment? |
Cryptographic attestation | Can you prove the execution environment hasn't been tampered with? |
Multi-model access | Can you switch or fallback across providers without re-architecting? |
Compliance readiness | Does the infrastructure support HIPAA, SOC 2, and GDPR requirements? |
Cost and usage visibility | Is there a unified view of tokens, cost, and usage across teams? |
Scaling headroom | Does the system give you visibility into quota usage and make it easy to switch providers without re-architecting? |
Most direct API integrations satisfy none of these beyond basic functionality. The alternatives covered in the next sections each address a subset, but their coverage varies significantly by architecture.
AI Gateways: The Most Complete Alternative for Enterprise
AI gateways sit between your application and the underlying model providers. Instead of calling OpenAI directly, your app sends requests to the gateway, which handles routing, execution policy, privacy controls, and observability in a single layer. For enterprises that need more than a single-vendor API, this is the most architecturally complete solution.
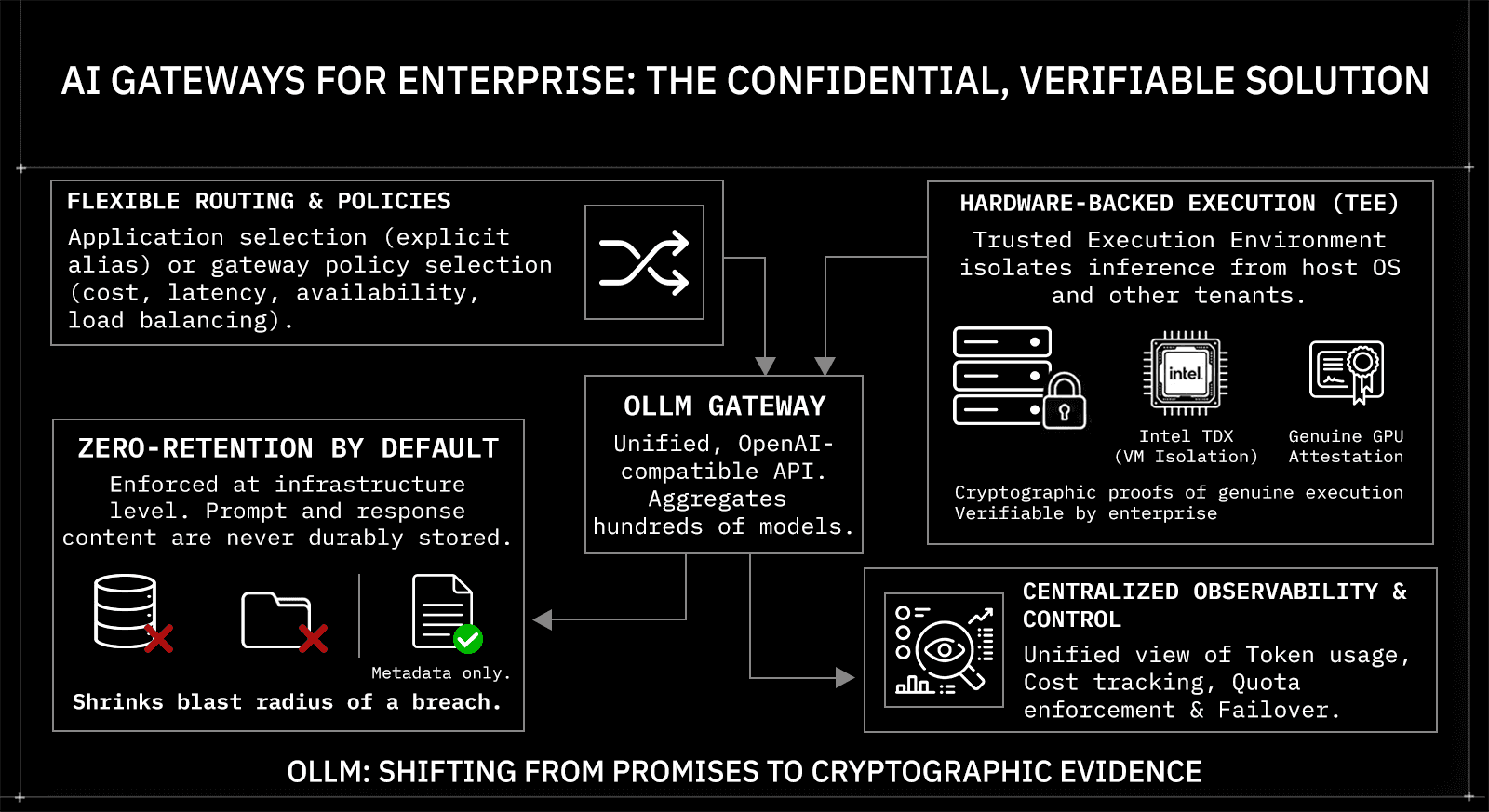
OLLM is built specifically for this use case. It's a confidential AI gateway that aggregates hundreds of models across providers behind a single OpenAI-style, OpenAI-SDK-compatible API for supported endpoints. The integration is a drop-in replacement for supported use cases; no re-architecting required. Because it uses the same SDK and request format, migration from a direct OpenAI integration is a single line change, base_url points to OLLM instead of OpenAI, and everything else stays the same:
Python, migrating from direct OpenAI to OLLM
from openai import OpenAI |
How Model Selection Works in OLLM
Model selection in OLLM is always user-controlled. The application explicitly specifies the model in the request, and OLLM executes that exact model; it does not substitute, override, or automatically reroute to a different provider or deployment.
Zero-Retention by Default
OLLM does not persistently store prompt or response content at the gateway layer by default. There is no database of your requests that could be breached or subpoenaed. Usage metadata, tokens, costs, and timestamps may still be logged for billing and reliability purposes, and prompt and response storage is off by default. This can be enforced at the infrastructure level through configuration, rather than left as an application-layer best practice.
This matters because zero retention isn't just a privacy feature; it's a compliance posture. When prompt and response content is never durably stored, the blast radius of a breach shrinks dramatically.
Hardware-Backed Execution with TEE Attestation
This is where OLLM goes beyond what any standard API gateway offers. Every model available through OLLM runs on confidential hardware. OLLM routes all requests to TEE-backed execution environments where inference runs inside hardware-isolated environments, separated from the host OS, hypervisor, and other tenants
What makes this verifiable is the attestation layer. OLLM integrates:
Intel TDX-based confidential-VM isolation: hardware-enforced isolation at the VM level for confidential compute
NVIDIA GPU attestation: cryptographic verification of GPU environment integrity, where the stack supports it
Cryptographic attestation evidence: standardized reports that enterprises can validate as part of their trust policy, typically before provisioning secrets (and, in some designs, before sending sensitive prompts), and/or before accepting results
TEE-backed execution can enable cryptographic attestation. Depending on the stack, technologies such as Intel TDX (for the confidential VM) and NVIDIA GPU attestation (for the GPU/device state) can generate evidence about the execution environment, including:
The confidential VM/workload measurement matches the expected values defined in the attestation policy, confirming the environment has not been tampered with
That the workload ran in a TEE-backed environment consistent with the policy
That the host can't directly read guest memory (within the TEE threat model)
Optionally, device/GPU claims when GPU attestation is available
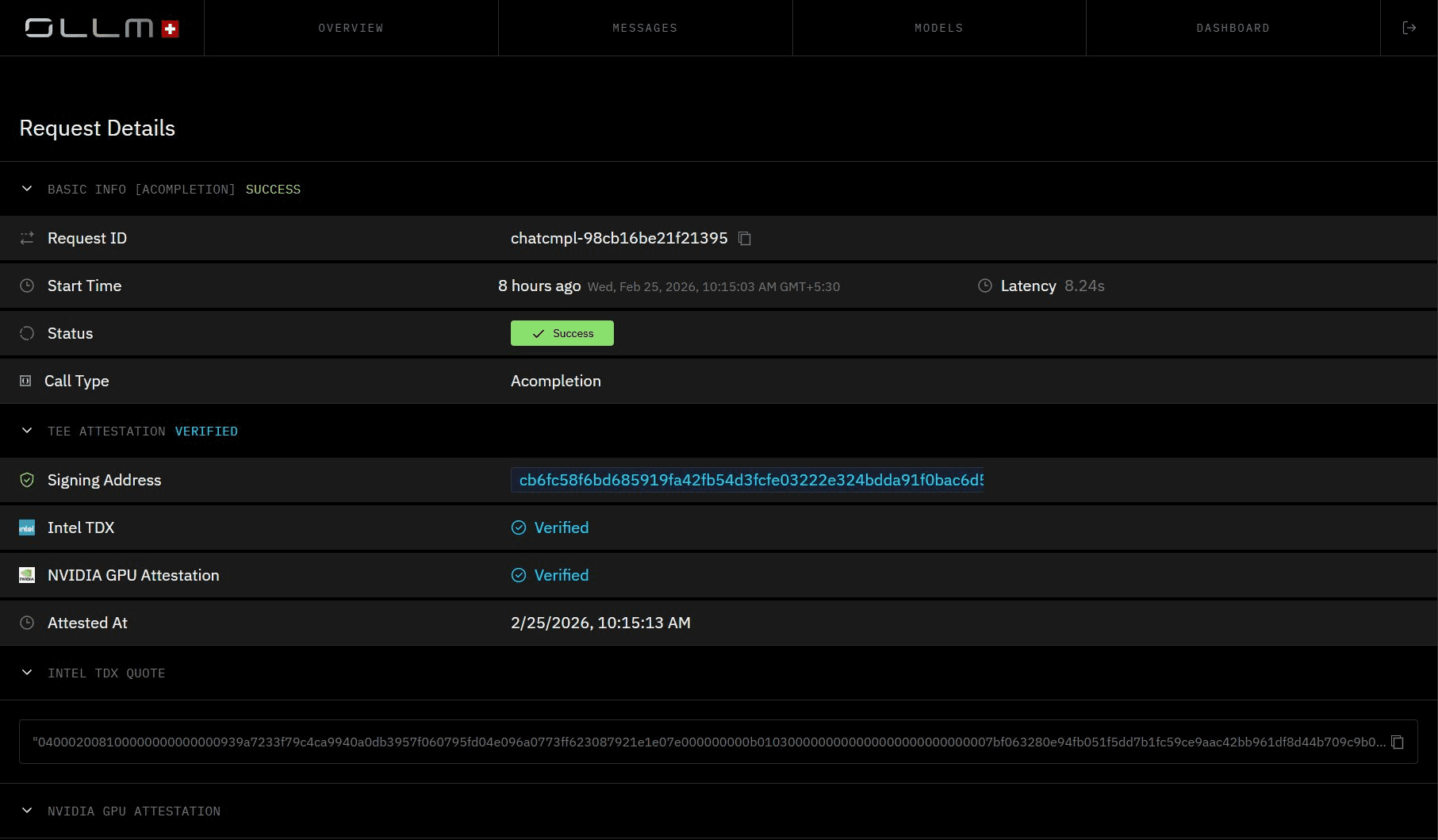
This model can replace purely trust-based isolation claims with cryptographically verifiable evidence, a meaningful distinction from every other gateway or API alternative on the market.
Here's what a TEE-attested request looks like in practice:
curl https://api.ollm.com/v1/chat/completions \ |
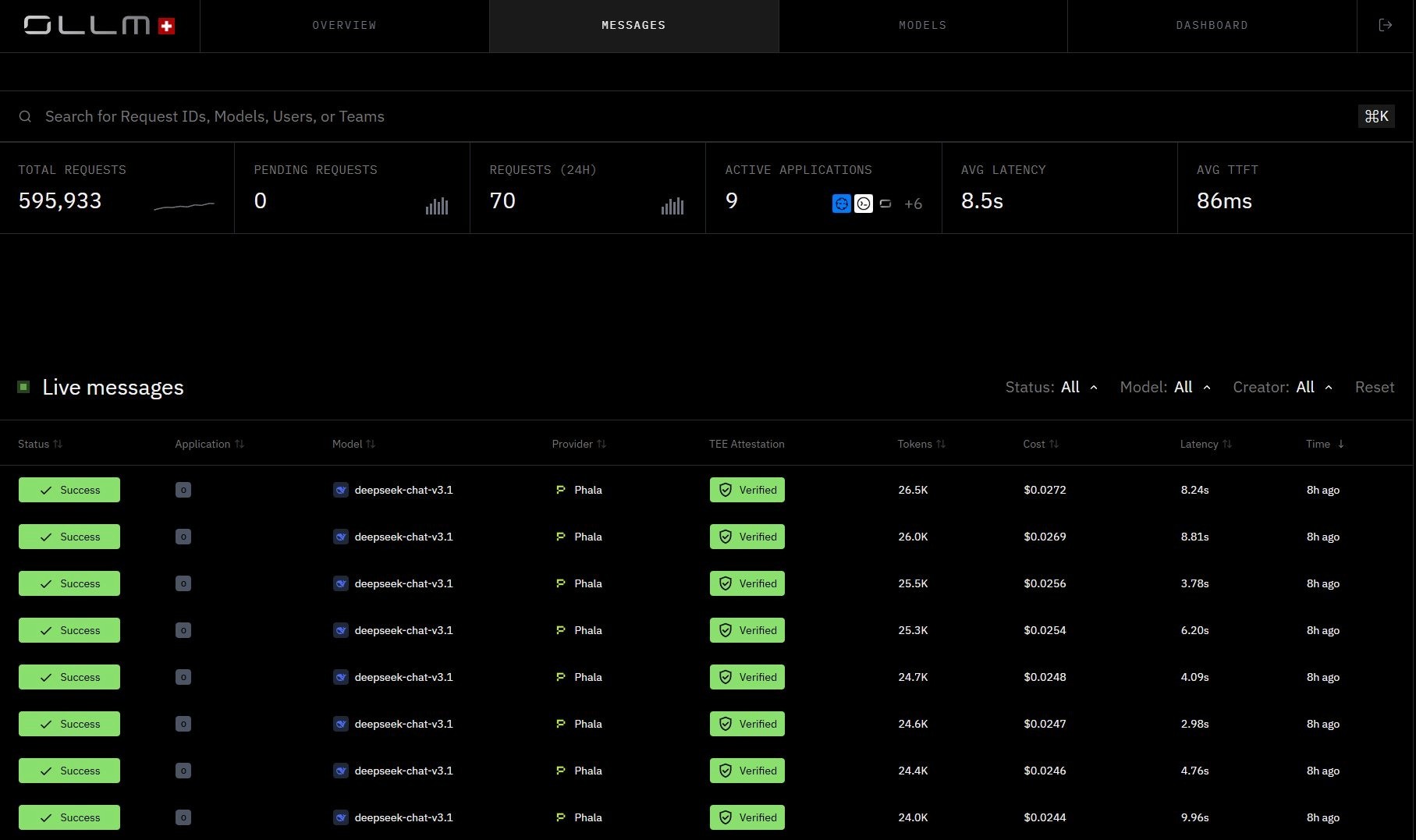
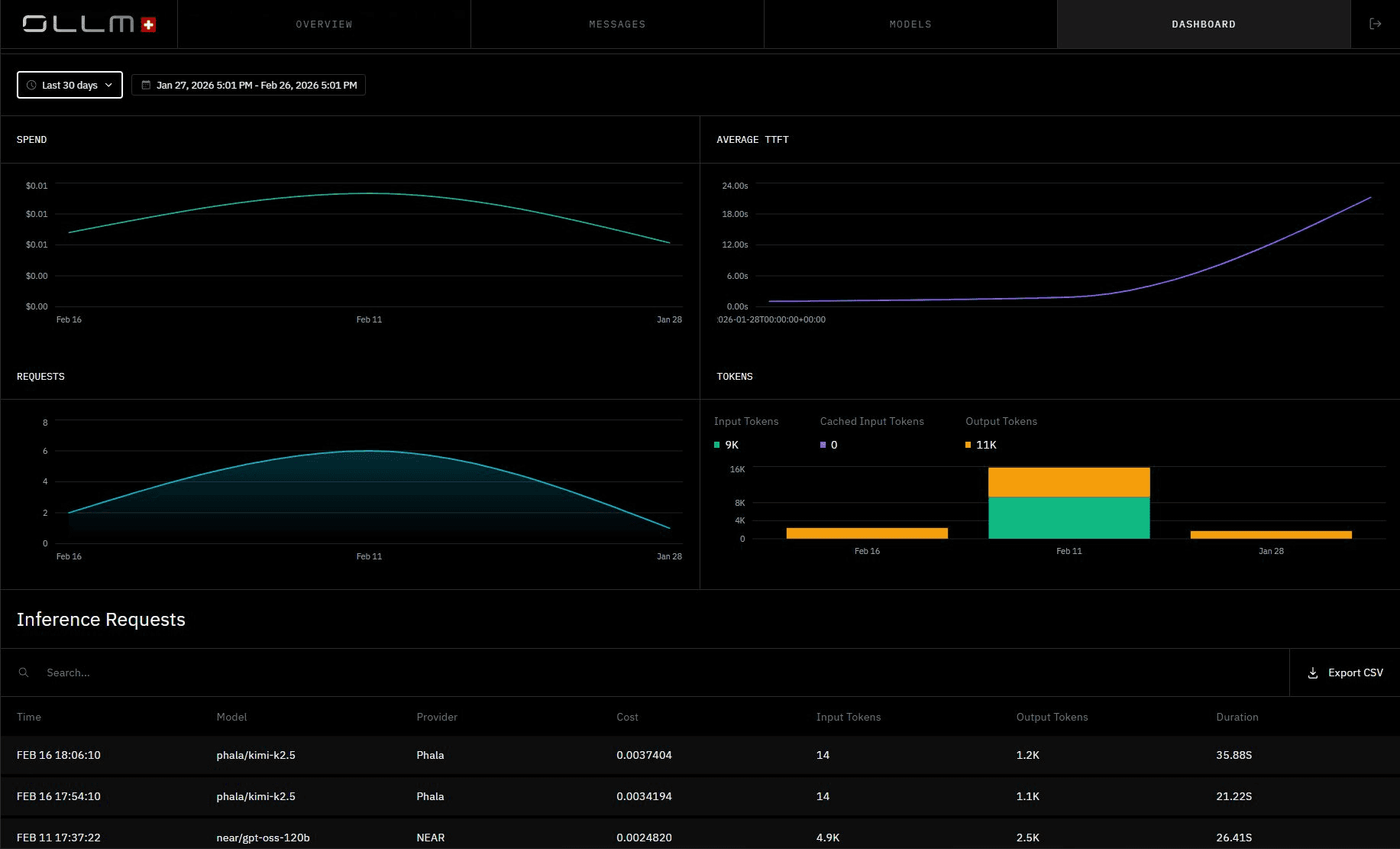
Every inference request returned with TEE Attestation Verified, per-request cost, token count, and latency. Each call is cryptographically verified and auditable, with no prompt or response content stored.
Centralized Observability and Cost Tracking
All usage flows through a single API, giving teams a unified view of token consumption, cost, and request metadata across models and providers. Scaling is handled through centralized quota enforcement and visibility. For higher-volume needs or reserved capacity, that's available as a plan or contract-specific option.
Self-Hosted Open Source Models: Full Control, High Overhead
Self-hosting open source models is the other end of the spectrum from direct API integration. Instead of sending data to a third-party provider, inference runs entirely on your own infrastructure. Tools like Ollama, vLLM, and LocalAI make it relatively straightforward to spin up models like Llama, Mistral, or Qwen on your own hardware or cloud instances.
The privacy argument is intuitive; if data never leaves your environment, there's nothing to breach at the provider layer. For some teams, that's enough. But the operational reality is more complicated.
The key trade-offs to consider:
Factor | Reality |
Infrastructure burden | You own provisioning, scaling, uptime, and model updates |
Model quality ceiling | Open source models still lag behind frontier models on many tasks |
No attestation | Self-hosted setups require significant custom implementation to achieve cryptographic attestation, even on hardware that supports it |
Scaling complexity | Load balancing, failover, and rate-limit handling require custom engineering |
Compliance gaps | Infrastructure compliance is your responsibility end-to-end |
Self-hosting gives you data locality, but it trades the vendor-trust problem for operational complexity. Teams that go this route often underestimate the engineering overhead required to run it reliably at scale, and few have the tooling to provide the kind of attestation that regulated industries increasingly expect.
Direct Competitor APIs: More Options, Same Structural Problems
The most obvious alternative to OpenAI is switching to another frontier model provider, Anthropic (Claude), Cohere, Mistral, or Google Gemini. The models are competitive, the APIs are well-documented, and for specific use cases, the capability or pricing profile can be a better fit. For many teams, this is the first move they make when OpenAI stops working for them.
But the structural problems don't change. Every one of these providers still receives your raw prompt and response data on their servers. There are no hardware-level isolation guarantees, no cryptographic attestation of the execution environment, and no unified compliance layer. You're trading one vendor's terms of service for another's.
The operational fragility carries over, too. Single-provider dependency means you're still exposed to:
Uptime risk: one provider's outage takes down your entire AI layer
Pricing and deprecation risk: model changes require migrations on their timeline, not yours
Single-provider ceiling: no architectural path to distribute load or switch providers without re-integrating
Switching providers solves the model question. It doesn't solve the architecture question. If the underlying concern is privacy, compliance, or operational resilience, a provider swap is a lateral move rather than an upgrade. The next step is infrastructure that abstracts the provider layer entirely.
Cloud Provider AI Services: Better Compliance, Still Not Enough
Cloud-hosted AI services, Azure OpenAI, AWS Bedrock, and GCP Vertex AI, are a step up from direct API integration. They sit inside cloud environments that enterprises already use, which means existing compliance frameworks, IAM policies, and network controls can extend to AI workloads. For teams already deep in a cloud ecosystem, this is an attractive path.
The compliance tooling is genuinely stronger here. Azure OpenAI, for example, offers private endpoints, data residency options, and integrations with Microsoft's broader compliance certifications. AWS Bedrock gives you VPC isolation and fine-grained access controls. These are real advantages over a raw API call.
But the trust boundary is still the cloud provider. Your prompts and responses are processed inside Azure, AWS, or GCP infrastructure, and you're ultimately relying on their attestation of what happens inside that boundary. There are no cryptographic proofs you can independently verify. There's no TEE-backed execution with hardware attestation reports you can validate yourself. And multi-cloud or multi-provider flexibility is essentially off the table; each service locks you into its own model catalog and billing layer.
For regulated industries that need verifiable execution integrity, not just contractual assurances, cloud AI services close some gaps but leave the most critical ones open.
How OLLM Solves What the Others Can't
Each alternative covered so far addresses part of the problem. Self-hosting gives you data locality but hands you an infrastructure burden. Competitor APIs give you model flexibility but no privacy architecture. Cloud AI services improve compliance tooling but keep you within a single vendor's trust boundary, offering no independently verifiable guarantees of execution.
OLLM is designed to close all of these gaps in a single layer.
Capability | Self-Hosted | Competitor APIs | Cloud AI Services | OLLM |
Zero-retention defaults | Data stays on your infrastructure, but no gateway-level enforcement | No retention controls | Contractual only | Default non-storage of prompt/response content at the gateway layer |
TEE-backed execution | No hardware attestation | No isolation guarantees | Cloud-trust boundary only | Intel TDX + NVIDIA GPU attestation on supported paths |
Multi-model access | Limited to what you self-host | Locked to one provider | Locked to cloud catalog | Hundreds of models, one API |
Unified cost tracking | Custom engineering required | Per-provider only | Partial, within the cloud ecosystem | Centralized usage and cost observability across all models |
Multi-model access and quota visibility | Manual engineering | No cross-provider visibility | Partial within cloud | Centralized quota tracking and visibility; provider switching requires only a model string change |
What sets OLLM apart isn't any single feature; it's that the privacy, attestation, and operational layers can be enforced together at the infrastructure level through configuration, not assembled piecemeal at the application layer.
On privacy, OLLM defaults to not persistently storing prompt or response content at the gateway layer. There is no durable record of what was sent or returned, which means there is no database to breach. There is no durable record of what was sent or returned, which means there is no database to breach. Usage metadata such as tokens, costs, and timestamps may still be logged for billing and reliability purposes.
On attestation, OLLM goes further than any cloud AI service by providing cryptographic TEE attestation proofs, not contractual assurances. For supported providers and models, inference runs inside hardware-isolated environments backed by Intel TDX-based confidential-VM isolation and NVIDIA GPU attestation. Enterprises can validate attestation evidence as part of their trust policy, typically before provisioning secrets (and, in some designs, before sending sensitive prompts) and/or before accepting results, to independently confirm the integrity of the execution environment. That's a level of verifiability no standard API or cloud service offers.
On scaling, the gateway provides centralized quota enforcement and visibility across all models and providers. For higher-volume deployments or reserved capacity, that's available as a plan-specific option worth a direct conversation with the OLLM team.
Conclusion: The Architecture Decision Behind Every Enterprise AI Deployment
Direct OpenAI integration gets projects off the ground, but it was never designed to carry enterprise workloads. Self-hosted models, competitor APIs, and cloud AI services each address some gaps, but none provides a single layer that combines hardware-backed confidential execution, zero-retention defaults, and centralized observability across hundreds of models. OLLM does, behind a single OpenAI-compatible API that requires a one-line change to adopt.
To get started, visit ollm.com and generate an API key to send your first TEE-attested inference request in minutes. If you want to go deeper, explore how OLLM compares to self-hosted gateways on total cost of ownership, or read about how confidential AI infrastructure addresses enterprise compliance requirements. For larger deployments or specific compliance needs, reach out to the OLLM team directly to discuss enterprise fit and reserved capacity.
FAQs
1. What is an AI gateway, and how is it different from calling a model API directly?
An AI gateway sits between your application and model providers, giving you access to hundreds of models through a single API, rather than managing separate integrations, credentials, and data-handling agreements for each. Beyond consolidation, a gateway centralizes token usage, cost tracking, and request observability across all models in one place, something you'd otherwise have to build yourself per provider. With OLLM specifically, every request also runs inside a hardware-isolated TEE with cryptographic attestation evidence returned per request, which no direct API integration provides regardless of how it's configured.
2. What is TEE attestation in the context of LLM inference?
TEE (Trusted Execution Environment) attestation provides cryptographic proof that inference ran inside a hardware-isolated enclave, such as an Intel TDX VM or an NVIDIA confidential GPU, and that the environment was genuine and unmodified. It's the difference between a contractual privacy assurance and a verifiable one.
3. How does OLLM's zero-retention policy work in practice?
By default, OLLM does not persistently store prompt or response content at the gateway layer. Usage metadata, tokens, costs, and timestamps may still be logged for billing and reliability. No database of request content could be breached or subpoenaed, which significantly reduces compliance exposure.
4. What are the risks of vendor lock-in with large language model providers?
Single-provider dependency exposes teams to model deprecations, unilateral pricing changes, and outage risk with no fallback. It also makes compliance harder; each provider has its own data-handling terms, and switching requires re-architecting integrations built around a single API.
5. Which OLLM providers and models support TEE-backed execution?
Every model available through OLLM runs on confidential hardware. Inference is routed to a hardware-isolated environment with Intel TDX-based confidential-VM isolation and NVIDIA GPU attestation.
"/><stop offset="1" stop-color="rgb(80, 78, 87)"/></linearGradient></defs><g d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z M 142.346 0.381 L 162 0.381 L 162 20 L 142.346 20 Z M 153.986 8.381 L 158.375 8.381 L 158.375 12 L 153.986 12 L 153.986 16.571 L 150.36 16.571 L 150.36 12 L 145.972 12 L 145.972 8.381 L 150.36 8.381 L 150.36 4.19 L 153.986 4.19 Z" fill="transparent" height="20px" id="cWM2PbaAz" width="162.00000833847133px"><path d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z" fill="url(%23UyELkL66Q-1582027827-linear-gradient)" height="20px" id="UyELkL66Q" width="134.52277004415487px"/><path d="M 0 0 L 19.654 0 L 19.654 19.619 L 0 19.619 Z" fill="rgb(176, 0, 0)" height="19.618991595424752px" id="t30DbKa7C" transform="translate(142.346 0.381)" width="19.653710120697895px"/><path d="M 8.014 4.19 L 12.403 4.19 L 12.403 7.81 L 8.014 7.81 L 8.014 12.381 L 4.389 12.381 L 4.389 7.81 L 0 7.81 L 0 4.19 L 4.389 4.19 L 4.389 0 L 8.014 0 Z" fill="rgb(255, 255, 255)" height="12.380917026238919px" id="bLcZkJmGc" transform="translate(145.972 4.19)" width="12.402826775197639px"/></g></svg>)