|

TL;DR
An LLM API aggregator like OpenRouter gives you one API key, a catalog of 200+ models, and consolidated billing. A confidential AI gateway like OLLM routes those same requests through hardware-isolated execution environments and hands back a cryptographic receipt proving your data was never exposed.
When an aggregator advertises ZDR, the provider is promising not to log your prompts. When a confidential gateway enforces it, the inference runs inside an Intel TDX confidential VM with NVIDIA GPU attestation, and the host OS itself cannot read the memory. One depends on trust; the other makes trust irrelevant.
If you're benchmarking models or shipping a prototype with no PII in the prompt, an aggregator is the right call. Once patient records, financial data, or legal documents are included in the prompt, the aggregator's convenience layer becomes a compliance liability.
Per OLLM's published architecture, the router authenticates requests, validates model availability, and coordinates attestation. It doesn't inspect prompt or response data, doesn't substitute models, and doesn't perform inference. That architectural constraint is what makes per-request verification possible.
OLLM exposes an OpenAI-compatible API. Existing applications using any OpenAI SDK connect with a base URL change and a new API key. The engineering cost is low; the compliance posture change is not.
After every inference on OLLM, the TEE produces attestation artifacts that prove the specified model ran inside a verified hardware boundary. Auditors don't get a policy document; they get a cryptographic receipt that they can independently verify with the OLLM scanner every single time.
Introduction
Gartner predicted in March 2024 that over 30% of the increase in API demand by 2026 would come directly from LLMs and GenAI tools, and, separately, that more than 80% of enterprises will have deployed GenAI APIs or applications by 2026, up from less than 5% in 2023. Both predictions are landing on schedule. What neither forecast accounted for is the infrastructure panic that follows when a team that started with a quick API key discovers, six months into production, that their routing layer was never built to answer the question an auditor is about to ask.
A thread on r/LLMDevs titled "Best LLM Gateway" collected hundreds of developer responses debating OpenRouter, LiteLLM, and custom proxies. The clearest pattern is this: developers who started with aggregators for convenience hit a wall the moment compliance requirements came into play. The conversation keeps cycling back to the same gap: the tool handles routing beautifully, but nobody can tell the security team what happened to the prompt after it left the aggregator's network. The confusion is partly a naming problem; "Gateway" now covers everything from a hosted routing proxy to a hardware-secured execution environment with per-request cryptographic attestation. Treating them as interchangeable is how teams end up shipping production AI infrastructure that passes a developer demo and fails a SOC 2 review.
OLLM was built specifically for the teams that ran into that ceiling. Its architecture separates TEE-backed model execution from the routing layer entirely: TEE models run inside hardware-backed Trusted Execution Environments with hardware-enforced memory isolation from the host OS, hypervisor, and infrastructure, with encryption of data in use via Intel TDX confidential VMs and NVIDIA H100 GPU attestation, and a cryptographic attestation receipt generated per request. Over the next several sections, we'll break down exactly what an API aggregator controls and what it doesn't, how a confidential AI gateway changes the execution trust model at the hardware level, how the request lifecycle differs between the two architectures step by step, and when each is the right call for the workload you're actually running.
Why Developers Keep Confusing These Two Infrastructure Layers
Every vendor in the LLM infrastructure space uses "gateway" in their copy. OpenRouter calls itself a gateway. LiteLLM calls itself a gateway. OLLM calls itself a gateway. None of them are wrong, but they're describing entirely different layers of a system, and that loose terminology has a cost.
The Naming Problem That Obscures Real Architectural Tradeoffs
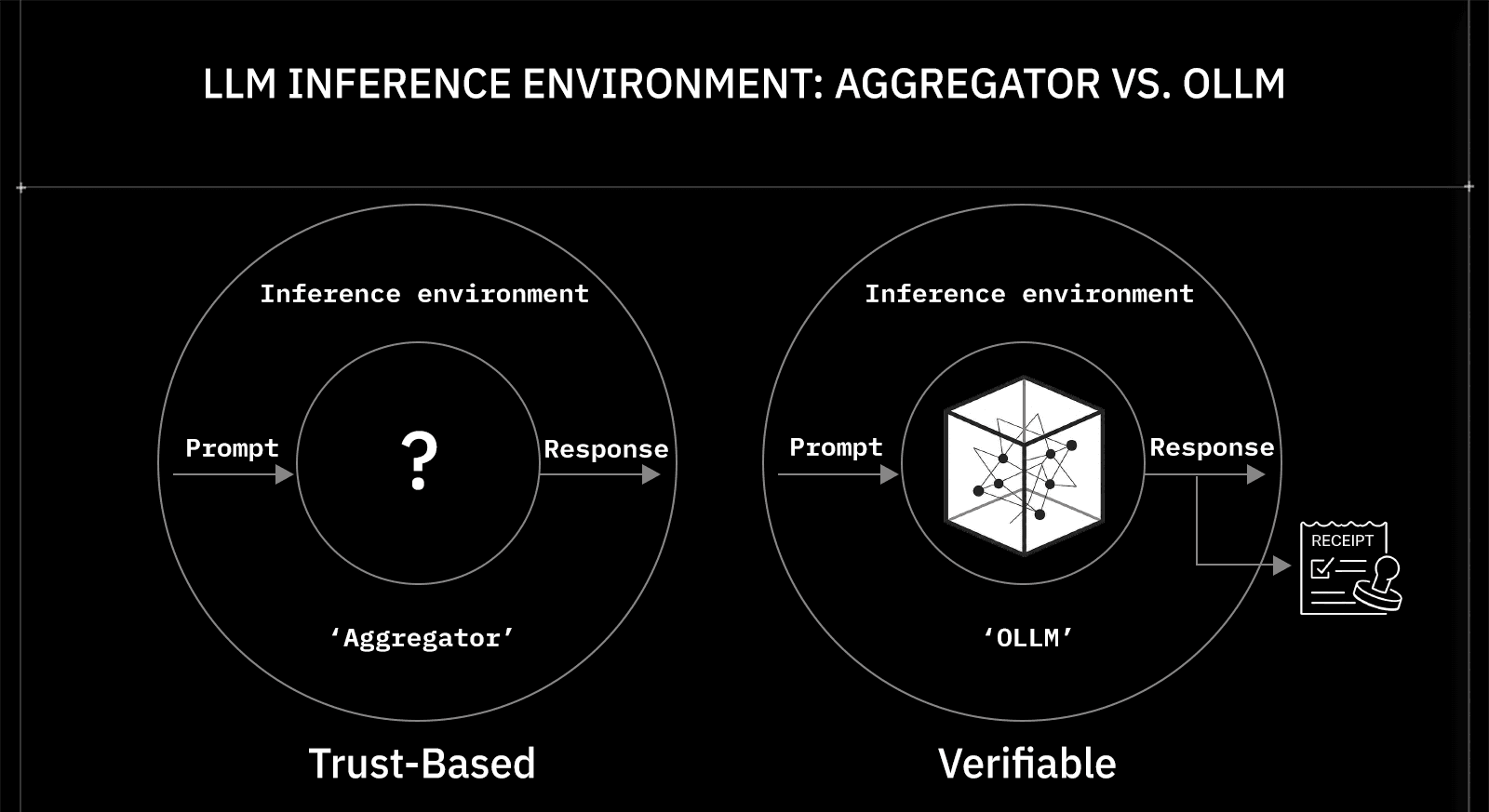
The confusion starts with how these tools market themselves. A quick scan of the LLM tooling space reveals that "gateway" has come to mean any layer between an application and a model provider, regardless of whether it performs routing, policy enforcement, observability, or hardware-level execution isolation. When every proxy, aggregator, and confidential execution layer shares the same label, developers end up picking infrastructure based on feature checklists rather than understanding what each architecture actually guarantees.
Teams choose an aggregator because it's easy to set up and offers hundreds of models through a single key. Months later, when the application processes real user data and a security review asks how prompts are handled, the answer is "the aggregator relays them to the upstream provider, and we trust the provider's ZDR policy." That's not an architectural answer; it's a contract answer. The gap only becomes visible when the stakes are high enough to care about the difference.
What Decision Engineers Are Actually Making When They Pick a Tool
There are two independent axes to consider when evaluating LLM infrastructure. The first is access breadth: how many providers and models can the tool reach, how is billing consolidated, and how quickly can you switch from GPT-4o to Claude Sonnet without touching application code? The second is execution trust: can you verify, per request and cryptographically, that your data was processed inside a trusted boundary?
For every TEE AI model inference request processed through OLLM, privacy guarantees are request-scoped, not platform-scoped. Each response stands on its own, with its own proof.
What is proven cryptographically
Using hardware attestation, OLLM enables customers to verify that:
The inference ran inside a genuine TEE
The execution environment was not tampered with
The environment matched the expected security measurements
The response was generated within that trusted boundary
These proofs are anchored in hardware root-of-trust mechanisms, not software assertions.
API aggregators are built almost entirely around the first axis. Confidential gateways like OLLM are built around the second. Most tools occupy exactly one of these axes, and the mistake is assuming that strong performance on one implies anything about the other. A tool with 600 models and excellent routing logic tells you nothing about what happens to your prompt once it leaves the aggregator's network and reaches the provider.
What an LLM API Aggregator Actually Does at the System Level
Understanding an aggregator at the system level requires looking past the developer experience and at the data path. The convenience is real, but so are the structural boundaries of what an aggregator can and cannot control.
Routing, Model Catalog, and Unified Billing as Core Functions
An API aggregator's primary job is normalization. Different LLM providers expose different API shapes, authentication schemes, and response structures. OpenAI uses one schema for chat completions; Anthropic uses another; models on HuggingFace add their own conventions for tool calling and context formatting. An aggregator absorbs all these differences and presents a single OpenAI-compatible endpoint to the calling application.
Billing consolidation is the other core function, i.e., instead of managing separate API keys, quota limits, and invoices for Anthropic, Google, Mistral, and a handful of open-source hosts, a team pays one aggregator and draws from a credit pool. For teams running experiments across many models, that operational simplicity has genuine value. OpenRouter, one of the most widely used aggregators, handles this for 200+ models and routes requests to provider infrastructure without requiring the caller to manage any of the provider-level credentials.
What Aggregators Do Not Own: The Execution Environment
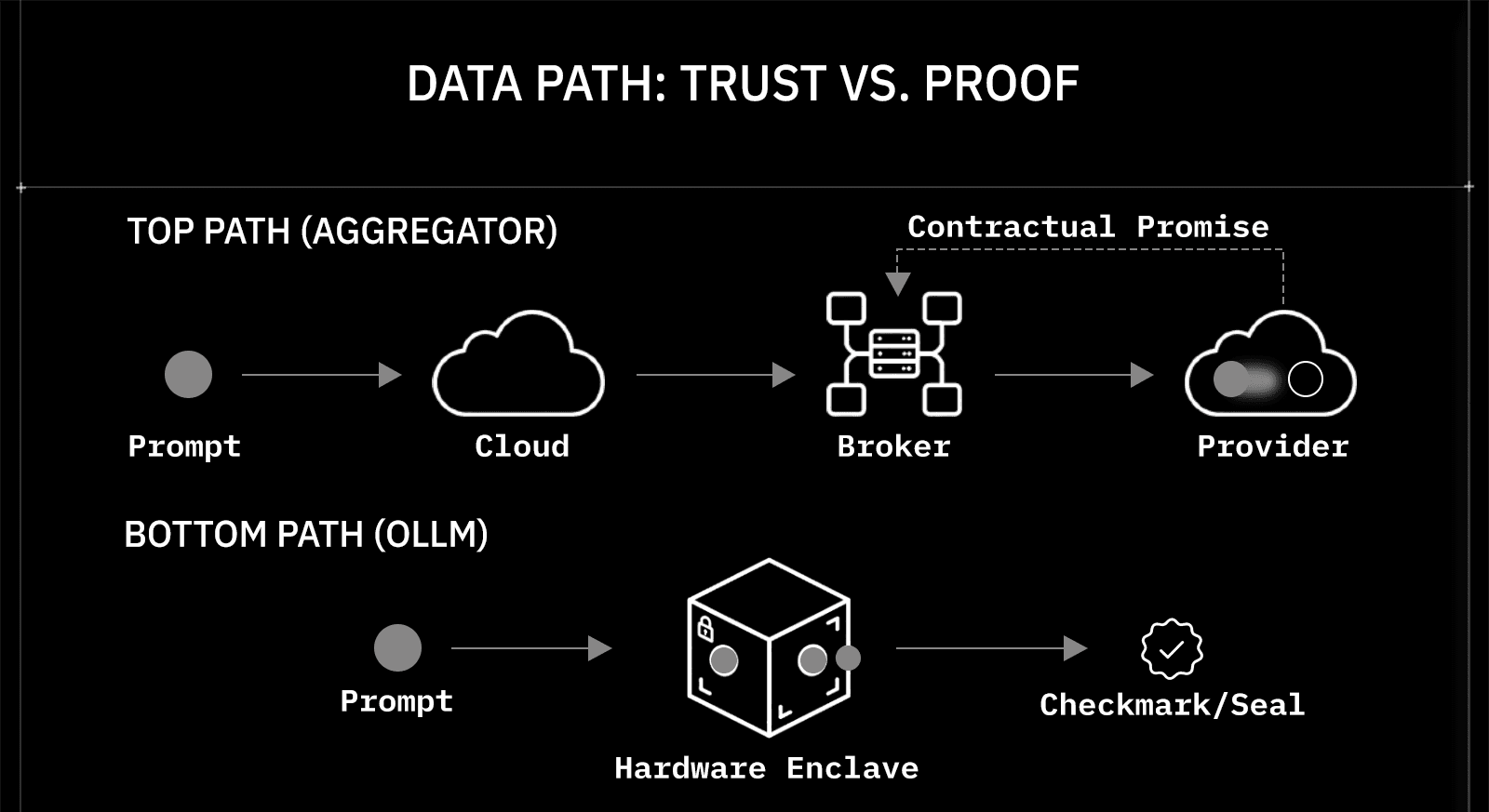
The important architectural constraint is what an aggregator does not control. When a request leaves the aggregator's network and reaches the upstream provider, inference runs on the provider's own infrastructure. The aggregator has no visibility into, and no control over, how the provider handles the prompt during execution. The aggregator can contractually promise not to log data in transit. It cannot guarantee what happens inside the provider's inference stack.
ZDR flags on aggregators are policy instruments. They tell you the aggregator isn't retaining your data on its own systems. They say nothing about what happens at the provider's inference layer, what the provider logs, or whether the compute environment is isolated at the hardware level. For most workloads, that distinction doesn't matter. For workloads in regulated industries, it's the only distinction that matters.
Where Aggregators Break Down Under Compliance and Audit Requirements
Regulated environments, financial services under SOC 2, healthcare under HIPAA, and legal work involving privileged communications require more than policy assertions. An auditor asking, "Prove that this prompt was processed in a compliant environment," needs a verifiable answer. An aggregator produces documentation: terms of service, ZDR agreements, and provider compliance certifications. None of those is wrong, but none of them is proof.
When teams build on a hosted aggregator, they route through third-party-controlled infrastructure, which raises compliance concerns for some teams and adds latency for everyone. That's not a hypothetical risk; it's an architectural fact. The aggregator sits in the data path, and the application has no independent mechanism to verify what occurred during execution. Compliance teams working under GDPR Article 32 or HIPAA's technical safeguards requirements increasingly treat that gap as a blocker for production deployment.
How a Confidential AI Gateway Changes the Execution Trust Model
Where an aggregator abstracts provider differences, a confidential gateway changes what's provable about execution. The architecture shift is not at the API surface; it's in what happens between the request leaving the client and the response returning.
Trusted Execution Environments as the Foundation of Verifiable Privacy
A Trusted Execution Environment is a hardware-isolated region of memory and compute resources where code runs on the processor, with encryption enforced. The host operating system, the hypervisor, and any other process running on the same machine cannot read the contents of a TEE's memory, even with root access. The hardware enforces the isolation; no software policy can override it.
In the context of LLM inference, a TEE means that the model processes the prompt inside an enclave where the provider's own infrastructure has no visibility into the plaintext data. Intel TDX creates confidential virtual machines at this level. NVIDIA's confidential compute extends the same guarantees to GPU workloads, which is where actual inference runs for large models. OLLM's published architecture states explicitly that all inference for TEE AI models runs inside hardware-backed TEEs provided by OLLM's supported providers, with hardware-enforced memory isolation protecting data from the host OS, hypervisor, and infrastructure access.
Per-Request Attestation: What It Produces and How to Verify It
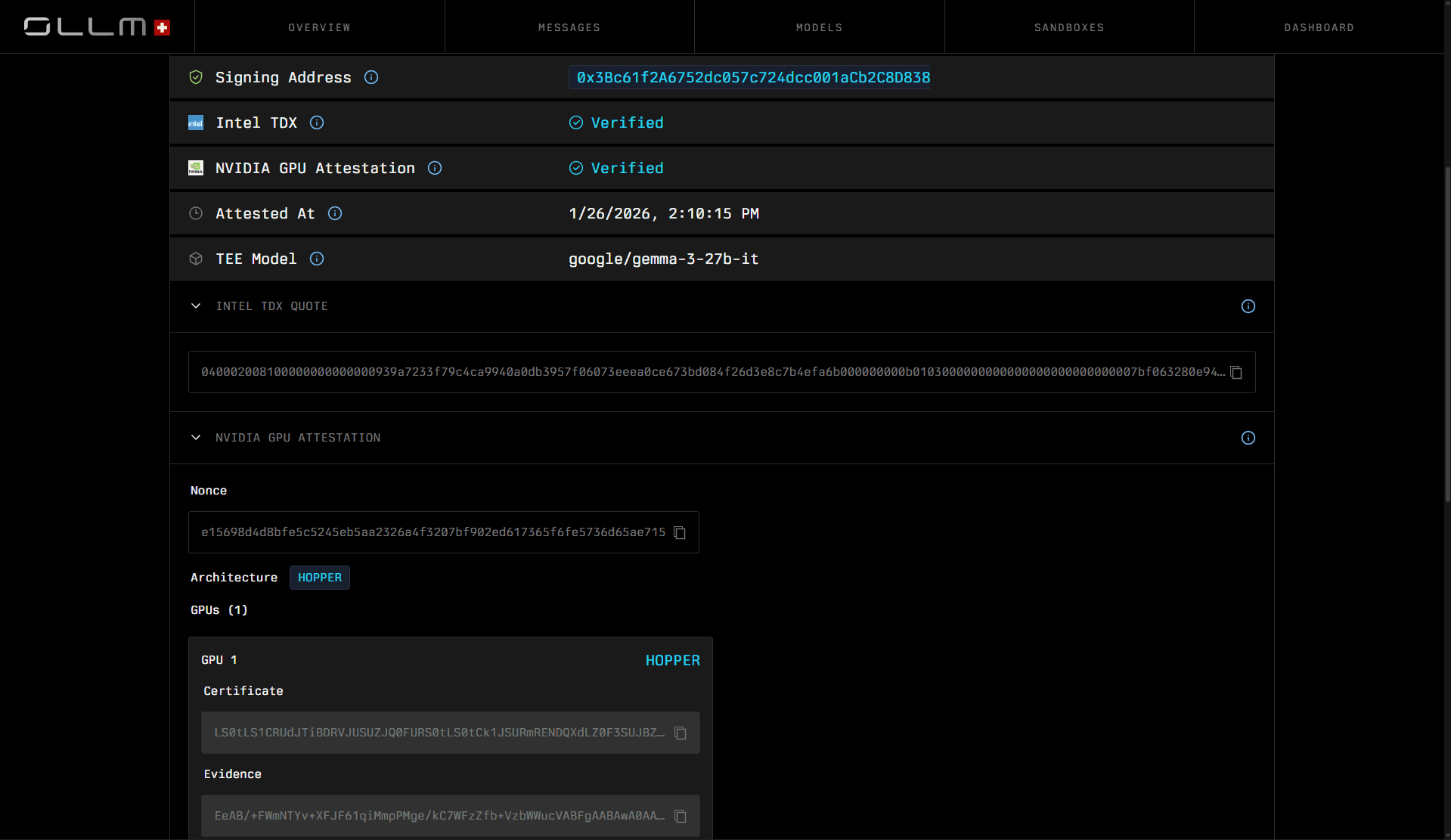
Attestation is the mechanism that makes TEE-backed inference verifiable to someone outside the execution environment. After inference runs inside a TEE, the hardware generates a cryptographic artifact that contains measurements of the execution environment: which model ran, which TEE platform was used, and whether the environment matched expected values. Anyone with the right public key can verify that artifact, without relying on the provider's word.
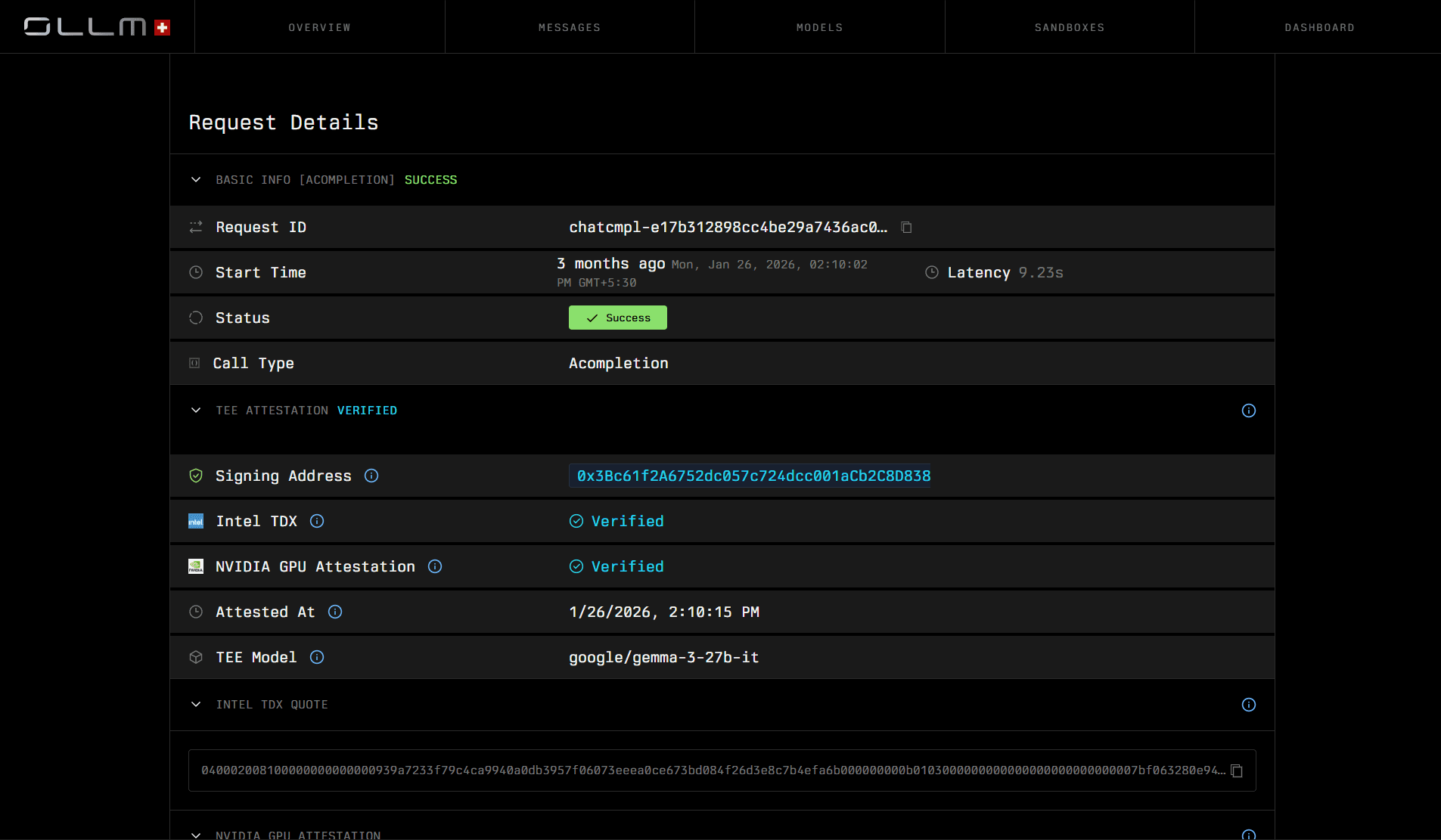
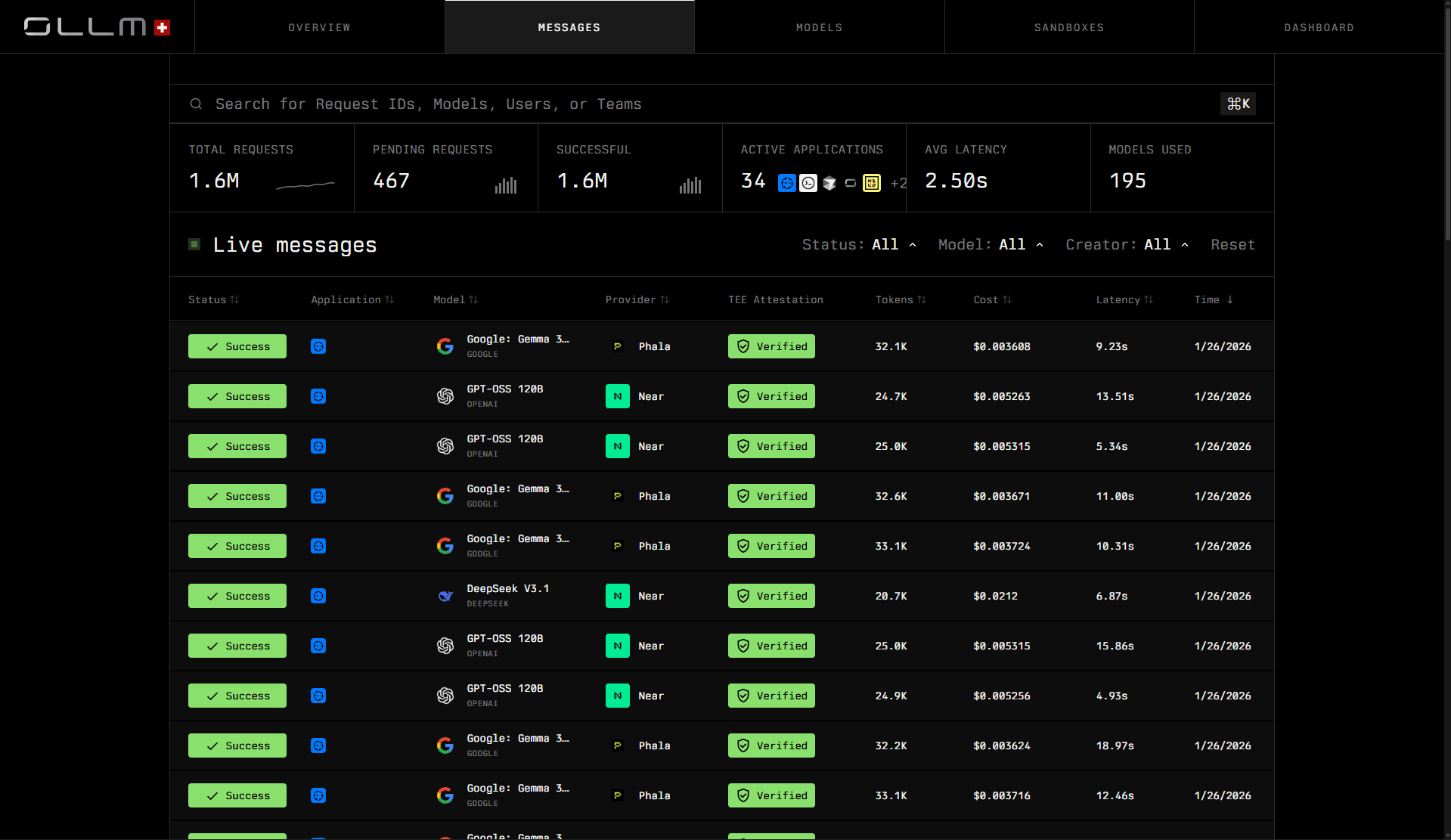
After sending a request, you can inspect it directly in the OLLM dashboard.
From the Messages view, you can:
See request status (Success, Failed, Pending)
View the selected model and provider
Confirm TEE attestation status (Verified / Pending / Failed)
Inspect cryptographic verification details
Per OLLM's architecture documentation, every TEE AI model request produces attestation artifacts that prove three things: the specified model ran inside a valid TEE, the execution environment matched expected measurements, and the response was generated within the trusted boundary. These artifacts are returned in the API response and can be independently verified using the OLLM scanner. OLLM's partnership with Phala extends this further: teams can now run frontier models on NVIDIA H200 GPUs with Intel TDX and AMD SEV protection, incurring only 0.5%-5% performance overhead, making full hardware-level privacy viable for production workloads without sacrificing meaningful throughput.
The Control Plane Constraint That Makes the Trust Model Work
OLLM's architecture makes an explicit design choice that most developers initially read as a limitation: the router does not perform automatic model selection or dynamic routing. The model specified in the request is the model that executes. OLLM's router authenticates the request, validates model availability and permissions, enforces security constraints, and coordinates attestation. It doesn't choose models, inspect inference data, or perform inference itself.
Verifiable inference is the core security guarantee provided by OLLM. It ensures that privacy is not based on policy, contractual assurances, or provider claims, but on cryptographic proof tied to each individual request.
Read as a security property rather than a missing feature, this constraint is load-bearing. Automatic model substitution would break the attestation chain: if the router can swap in a different model, the attestation artifact no longer proves what the caller requested. By making model selection entirely user-controlled, OLLM ensures that the cryptographic proof returned with the response refers to the exact model the application specified, rather than a "similar" model the router judged equivalent.
The Security Architecture Gap Between Routing and Attestation
Security claims in LLM infrastructure tend to cluster around data in transit, because TLS is table stakes and easy to advertise. The more substantive gap is what happens to data while it's being used.
Data in Transit vs. Data in Use: Where Encryption Differs
TLS encrypts data moving between your application and the aggregator, and between the aggregator and the provider. That's necessary, but it doesn't address data in use, which is the period when the model processes the prompt inside the provider's compute environment. Standard inference infrastructure decrypts the prompt at the compute layer so the GPU can process it. During that window, the prompt is in plaintext inside the provider's infrastructure, accessible to anyone with sufficient access to that environment.
Confidential computing closes that window; as per OLLM's documentation, the platform enforces encryption across the full request lifecycle: TLS between client, OLLM, and model providers for data in transit; hardware memory encryption via Intel TDX and NVIDIA confidential compute during inference for data in use; and encrypted configuration across the control plane. The prompt stays encrypted until the TEE processes it, and the TEE's hardware isolation prevents the provider's own infrastructure from reading the plaintext.
Insider Threat Surface and Infrastructure-Level Risks
An aggregator's managed infrastructure introduces a third-party network path with its own attack surface. A compromised aggregator, misconfigured logging, or an insider with access to request logs can expose prompt data even if the aggregator has good intentions. With a self-managed or hosted aggregator, your data passes through their infrastructure, and some organizations can't accept this due to regulatory requirements or data sensitivity.
OLLM's TEE model removes the aggregator itself from the threat model. Because OLLM's router cannot inspect raw prompt or response data outside the TEE boundary, a compromised OLLM infrastructure layer cannot expose inference data. The hardware guarantees what software policy cannot: even a fully compromised intermediary layer yields nothing from the TEE-protected inference. That's a materially different risk posture for any workload involving sensitive data.
Audit Trails and What Passes a Security Review
An aggregator's audit trail documents that a request was made, to which model, at what time, and for what cost. That's useful for billing attribution and basic operational monitoring. What it doesn't contain is any evidence about the execution environment, whether the prompt was processed in an isolated context, or whether the model that responded is the one requested.
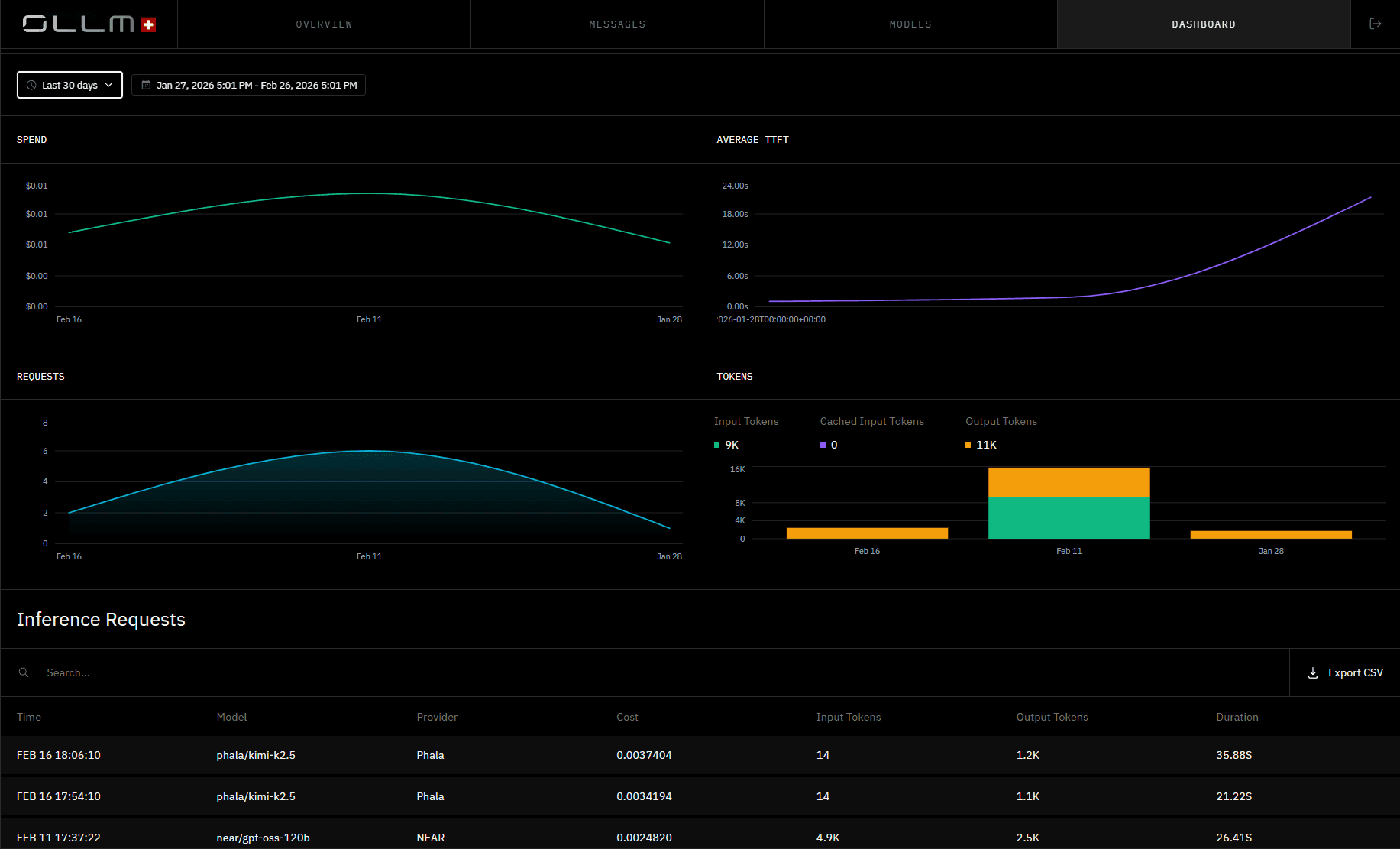
You can track your OLLM usage in the OLLM dashboard, including:
Total requests
Token usage
Model usage
Verification status
OLLM's per-request attestation artifacts directly fill that gap. Each artifact contains hardware-level proof of execution that can be verified independently against the TEE's cryptographic measurements. When a security review asks for evidence of compliant processing, the answer is a signed artifact with a timestamp and model measurement, not a link to a compliance certificate page. For teams operating under HIPAA, GDPR Article 32, or financial data handling requirements, that distinction separates a tool that passes an audit from one that requires an exemption.
Request Lifecycle Compared: Aggregator Path vs. Confidential Gateway Path
Walking through the actual mechanics of how a request travels through each system makes the architectural difference concrete rather than abstract.
Aggregator Request Lifecycle: Client to Provider via Third-Party Network Path
With a typical aggregator, the flow looks like this: the application sends a request to the aggregator's endpoint; the aggregator authenticates the API key, resolves the model name to a specific provider, and may apply routing logic like failover or load balancing; the request travels through the aggregator's network to the upstream provider's API; the provider runs inference on its standard compute infrastructure; the response returns through the aggregator to the calling application.
At no point in this flow does the calling application have any visibility into the provider's execution environment. The aggregator can tell you which provider handled the request and how many tokens were consumed. It cannot tell you whether the prompt was processed in isolated memory, whether the provider logged it for model training, or whether the execution environment matches any particular security standard. The aggregator provides a unified API across multiple models; what happens beyond that proxy layer depends entirely on the provider's infrastructure and policies.
Confidential Gateway Request Lifecycle: Client to TEE with Hardware Receipt
OLLM's request flow, as documented in its architecture reference, works differently at every step after authentication. The client sends a request with an explicit model specification; OLLM authenticates the request and verifies the model is available and supported; the request is forwarded to the selected model's TEE-backed execution environment; hardware attestation is generated as part of the execution process; and the model output plus verification metadata return to the client together.
Two properties of this flow matter most. First, OLLM does not alter the model choice at any point. The requested model is the one that runs. Second, OLLM's software layer generates the attestation artifact by the hardware, so neither OLLM nor the provider can fabricate a passing attestation for a non-compliant execution.
OLLM supports multiple hardware attestation technologies to enable verifiable inference across different execution environments.
Migration Path for Teams Moving from Aggregator to Confidential Gateway
The API-level migration is straightforward. OLLM is OpenAI-compatible, so any application that uses an OpenAI SDK can connect by changing the base URL and swapping in an OLLM API key. Model name conventions may differ slightly between providers, but the request and response structures remain consistent. An existing application can migrate with minimal changes, without custom clients, wrappers, or SDK rewrites.
The non-trivial work is on the verification side, specifically deciding whether to act on the attestation artifacts OLLM returns with each response. For teams that want to verify execution per request, the response includes attestation metadata that can be checked against the OLLM scanner. For teams that primarily need the hardware-level isolation guarantee without building custom verification logic, the trust model holds by default, with no additional integration.
When Each Architecture Is the Right Fit
Neither architecture is universally correct. The right choice depends on what data moves through the prompt, what regulatory environment the application operates in, and what an audit actually requires.
Aggregators as the Correct Choice for Prototype, Experimentation, and Low-Stakes Workloads
For teams benchmarking models, building internal tools with no PII in the prompt, or running development and staging environments, an aggregator is the right tool. The breadth of the catalog, consolidated billing, and zero infrastructure overhead genuinely reduce friction. A hosted aggregator removes the need to maintain gateway infrastructure, making it a fast starting point when breadth across models matters more than execution verification.
The workload signals that point toward an aggregator: no regulated data in prompts, no audit requirement for execution provenance, development iteration speed as the primary concern, and willingness to accept the provider's standard compliance posture for each model. Most prototype workloads check all these boxes, and an aggregator handles them well.
Confidential Gateways as the Correct Choice for Regulated, Sensitive, and Production-Grade Workloads
Once the application processes PII, PHI, financial records, legal documents, or any data that triggers a compliance obligation, the aggregator's policy layer no longer satisfies the requirement. HIPAA's technical safeguard rules require access controls and audit controls that can be demonstrated, not merely claimed. GDPR Article 32 requires appropriate technical measures to ensure a level of security appropriate to the risk. A cryptographic attestation artifact is a technical measure; a ZDR agreement is a contractual one.
OLLM's architecture is designed for organizations that cannot rely on trust statements alone when handling sensitive data. Rather than replacing implicit trust with better contracts, it replaces implicit trust with cryptographic verification and hardware-enforced isolation. For a healthcare application processing clinical notes, a financial platform handling transaction data, or a legal tool working with privileged documents, the confidential gateway is the architecture that passes a meaningful security review, not just a checkbox audit.
The Hybrid Stack Reality: Aggregator for Dev, Confidential Gateway for Production
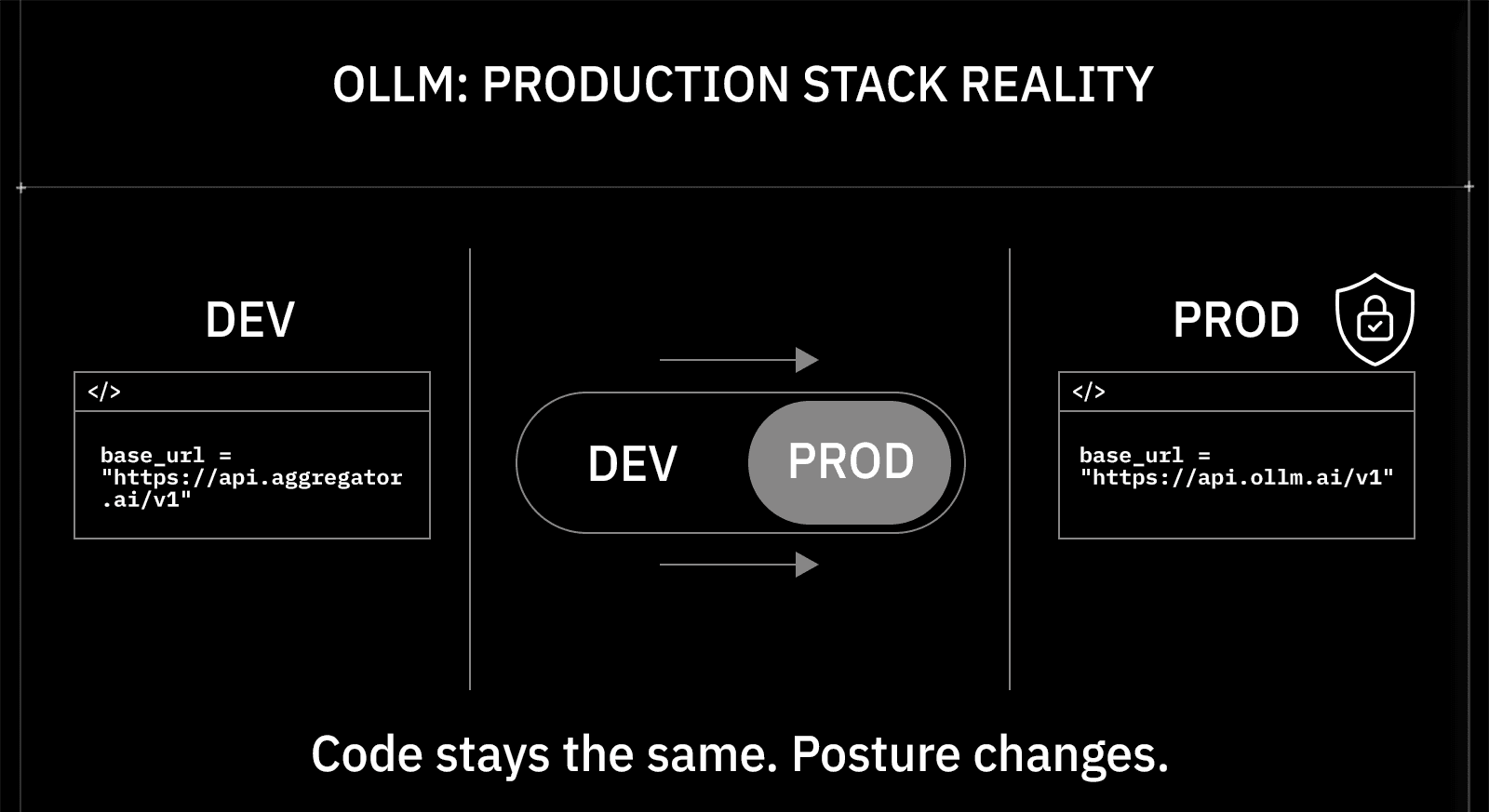
Many teams run both. An aggregator in development provides the iteration speed and model breadth that prototyping requires, without the latency overhead of confidential computing. Once the application moves to production and real user data enters the prompt, the base URL changes, and the application now routes through OLLM's confidential infrastructure. The performance overhead of TEE-backed inference runs between 0.5% and 5%, a trade-off that's operationally negligible for most production workloads compared to the compliance risk of running sensitive data through a standard aggregator.
The OpenAI SDK compatibility on both sides makes the switch mechanical. The application code doesn't change; the infrastructure posture does. That's the right division of concern: use the aggregator for speed when data sensitivity is low, and switch to the confidential gateway when it isn't.
Conclusion
LLM API aggregators and confidential AI gateways solve different problems at different layers of the stack. Aggregators solve the integration and access problem: one key, many models, consolidated billing, and no per-provider SDK work. Confidential gateways solve the execution trust problem: hardware-isolated inference, cryptographic proof of processing, and a control plane that cannot access the data it routes. Using an aggregator where a confidential gateway is needed doesn't leave a small gap; it leaves the entire execution layer unverified, and no contract fills an architectural gap.
The distinction becomes consequential the moment a production application handles data that a regulator, a legal team, or a security review will scrutinize. At that point, the question isn't "which tool has more models," it's "what can I prove about how this data was handled." OLLM's architecture answers that question with a hardware receipt per request, not a terms-of-service page.
FAQs
1. What Is The Difference Between An LLM API Aggregator And An LLM Gateway?
An LLM API aggregator, such as OpenRouter, normalizes multiple provider APIs into a single endpoint and consolidates billing. An LLM gateway, in the confidential computing sense, adds a hardware-enforced execution layer with per-request attestation. The API surface looks identical; the security posture differs at the execution layer, not the integration layer.
2. Can An API Aggregator Like OpenRouter Provide Zero Data Retention Guarantees?
Aggregators can contractually commit not to retain data in their own systems, but they relay requests to upstream providers whose infrastructure they don't control. ZDR on an aggregator is a policy commitment. ZDR on an aggregator is a policy commitment from the upstream provider. On OLLM, ZDR models carry the same policy-based guarantee: no prompts or responses are retained. Hardware-enforced guarantees with cryptographic attestation apply to OLLM's TEE models, which run inside Intel TDX confidential VMs provided by Phala and NEAR.
3. How Does Per-Request Attestation Work In A Confidential AI Gateway?
During inference within a TEE, the hardware generates a cryptographic artifact that contains measurements of the execution environment, thereby confirming that the specified model ran in a verified, isolated context. OLLM returns this artifact alongside the API response, and it can be independently verified through the OLLM scanner without trusting OLLM's own assertion that the execution was secure.
4. When Should A Team Switch From An LLM Aggregator To A Confidential AI Gateway In Production?
The moment production prompts contain PII, PHI, financial records, or legally privileged content, the aggregator's policy-layer guarantees are insufficient for most regulatory frameworks. Because OLLM is OpenAI-compatible, the migration is a base URL change, so the cost of switching is low relative to the compliance risk of not switching.
"/><stop offset="1" stop-color="rgb(80, 78, 87)"/></linearGradient></defs><g d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z M 142.346 0.381 L 162 0.381 L 162 20 L 142.346 20 Z M 153.986 8.381 L 158.375 8.381 L 158.375 12 L 153.986 12 L 153.986 16.571 L 150.36 16.571 L 150.36 12 L 145.972 12 L 145.972 8.381 L 150.36 8.381 L 150.36 4.19 L 153.986 4.19 Z" fill="transparent" height="20px" id="cWM2PbaAz" width="162.00000833847133px"><path d="M 28.559 14.287 C 28.559 15.87 28.009 17.216 26.893 18.333 C 25.784 19.441 24.431 20 22.849 20 L 5.879 20 C 4.342 20 2.828 19.449 1.727 18.378 C 1.169 17.835 0.757 17.239 0.466 16.581 L 22.773 16.581 C 23.269 16.581 23.774 16.39 24.11 16.023 C 24.408 15.694 24.561 15.304 24.561 14.86 L 24.561 10.233 C 24.561 8.023 26.35 6.233 28.559 6.233 L 28.559 14.286 Z M 40.856 0.469 C 40.908 0.469 40.947 0.488 40.973 0.527 C 41.012 0.553 41.031 0.592 41.031 0.644 L 41.031 14.98 C 41.031 15.436 41.194 15.833 41.52 16.172 C 41.845 16.497 42.242 16.66 42.711 16.66 L 64.85 16.66 C 64.889 16.66 64.921 16.68 64.947 16.718 C 64.986 16.745 65.006 16.777 65.006 16.816 L 65.006 19.844 C 65.006 19.883 64.986 19.922 64.947 19.961 C 64.921 19.987 64.886 20.001 64.85 20 L 42.711 20 C 41.162 20 39.841 19.459 38.747 18.379 C 37.667 17.285 37.127 15.963 37.127 14.414 L 37.127 0.645 C 37.127 0.592 37.14 0.553 37.166 0.527 C 37.205 0.488 37.244 0.469 37.283 0.469 L 40.856 0.469 Z M 75.049 0.469 C 75.1 0.469 75.14 0.488 75.166 0.527 C 75.204 0.553 75.224 0.592 75.224 0.644 L 75.224 14.98 C 75.224 15.436 75.387 15.833 75.712 16.172 C 76.038 16.497 76.435 16.66 76.903 16.66 L 99.042 16.66 C 99.081 16.66 99.114 16.679 99.14 16.718 C 99.179 16.745 99.198 16.777 99.198 16.816 L 99.198 19.844 C 99.198 19.883 99.179 19.922 99.14 19.961 C 99.114 19.987 99.078 20.001 99.042 20 L 76.903 20 C 75.354 20 74.033 19.459 72.94 18.379 C 71.86 17.285 71.319 15.963 71.319 14.414 L 71.319 0.645 C 71.319 0.593 71.332 0.553 71.358 0.527 C 71.397 0.488 71.437 0.469 71.476 0.469 L 75.049 0.469 Z M 128.939 0.469 C 130.488 0.469 131.803 1.015 132.883 2.109 C 133.976 3.203 134.523 4.518 134.523 6.054 L 134.523 19.844 C 134.523 19.883 134.503 19.922 134.465 19.961 C 134.439 19.987 134.399 20 134.347 20 L 130.774 20 C 130.735 20 130.696 19.987 130.657 19.961 C 130.633 19.926 130.619 19.886 130.618 19.844 L 130.618 5.488 C 130.618 5.033 130.456 4.642 130.13 4.316 C 129.805 3.991 129.408 3.828 128.939 3.828 L 121.97 3.828 L 121.97 19.844 C 121.97 19.883 121.95 19.922 121.911 19.961 C 121.885 19.987 121.846 20 121.794 20 L 118.241 20 C 118.189 20 118.143 19.987 118.104 19.961 C 118.079 19.927 118.066 19.886 118.065 19.844 L 118.065 3.828 L 111.095 3.828 C 110.627 3.828 110.23 3.991 109.904 4.316 C 109.579 4.642 109.416 5.033 109.416 5.488 L 109.416 19.844 C 109.416 19.883 109.397 19.922 109.358 19.961 C 109.332 19.987 109.297 20.001 109.26 20 L 105.688 20 C 105.639 20.001 105.592 19.987 105.551 19.961 C 105.527 19.927 105.513 19.886 105.512 19.844 L 105.512 6.055 C 105.512 4.518 106.058 3.203 107.152 2.109 C 108.245 1.016 109.56 0.469 111.095 0.469 L 128.939 0.469 Z M 22.849 0 C 24.431 0 25.777 0.551 26.893 1.667 C 27.42 2.195 27.825 2.784 28.101 3.418 L 5.718 3.418 C 5.252 3.418 4.854 3.594 4.51 3.931 C 4.166 4.267 3.998 4.673 3.998 5.14 L 3.998 9.767 C 3.998 11.977 2.209 13.767 0 13.767 L 0.008 13.759 L 0.008 5.714 C 0.008 4.069 0.612 2.685 1.812 1.545 C 2.89 0.528 4.334 0 5.817 0 Z" fill="url(%23UyELkL66Q-1582027827-linear-gradient)" height="20px" id="UyELkL66Q" width="134.52277004415487px"/><path d="M 0 0 L 19.654 0 L 19.654 19.619 L 0 19.619 Z" fill="rgb(176, 0, 0)" height="19.618991595424752px" id="t30DbKa7C" transform="translate(142.346 0.381)" width="19.653710120697895px"/><path d="M 8.014 4.19 L 12.403 4.19 L 12.403 7.81 L 8.014 7.81 L 8.014 12.381 L 4.389 12.381 L 4.389 7.81 L 0 7.81 L 0 4.19 L 4.389 4.19 L 4.389 0 L 8.014 0 Z" fill="rgb(255, 255, 255)" height="12.380917026238919px" id="bLcZkJmGc" transform="translate(145.972 4.19)" width="12.402826775197639px"/></g></svg>)